CN1298520A - 按照层结构具有二维或多维可编程序的单元结构(FPGAs、DPGAs等)的数据流处理器和模块的高速缓存配置数据方法 - Google Patents
按照层结构具有二维或多维可编程序的单元结构(FPGAs、DPGAs等)的数据流处理器和模块的高速缓存配置数据方法 Download PDFInfo
- Publication number
- CN1298520A CN1298520A CN99805452A CN99805452A CN1298520A CN 1298520 A CN1298520 A CN 1298520A CN 99805452 A CN99805452 A CN 99805452A CN 99805452 A CN99805452 A CN 99805452A CN 1298520 A CN1298520 A CN 1298520A
- Authority
- CN
- China
- Prior art keywords
- address
- instruction
- configuration
- instruction sequence
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000000034 method Methods 0.000 title claims abstract description 107
- 230000015654 memory Effects 0.000 claims abstract description 43
- 238000003860 storage Methods 0.000 claims description 20
- 230000000694 effects Effects 0.000 claims description 7
- 230000000295 complement effect Effects 0.000 claims description 6
- 238000010276 construction Methods 0.000 claims description 4
- 230000003446 memory effect Effects 0.000 claims description 4
- 230000001413 cellular effect Effects 0.000 claims description 3
- 238000013461 design Methods 0.000 claims description 2
- 230000008569 process Effects 0.000 abstract description 40
- 238000012545 processing Methods 0.000 abstract description 18
- 238000011068 loading method Methods 0.000 abstract description 11
- 239000013598 vector Substances 0.000 description 40
- 230000005540 biological transmission Effects 0.000 description 24
- 230000014509 gene expression Effects 0.000 description 16
- 230000006870 function Effects 0.000 description 15
- 230000003139 buffering effect Effects 0.000 description 12
- 229910002056 binary alloy Inorganic materials 0.000 description 10
- 238000007726 management method Methods 0.000 description 10
- 239000010813 municipal solid waste Substances 0.000 description 10
- 230000008901 benefit Effects 0.000 description 8
- 230000004087 circulation Effects 0.000 description 8
- 239000003999 initiator Substances 0.000 description 8
- 230000008859 change Effects 0.000 description 7
- 238000013519 translation Methods 0.000 description 7
- 230000014616 translation Effects 0.000 description 7
- 238000004891 communication Methods 0.000 description 6
- 238000005516 engineering process Methods 0.000 description 5
- 239000011159 matrix material Substances 0.000 description 5
- 230000002093 peripheral effect Effects 0.000 description 5
- 238000006467 substitution reaction Methods 0.000 description 5
- 238000012546 transfer Methods 0.000 description 5
- 238000011282 treatment Methods 0.000 description 5
- 238000012217 deletion Methods 0.000 description 4
- 230000037430 deletion Effects 0.000 description 4
- 238000010586 diagram Methods 0.000 description 4
- 230000007246 mechanism Effects 0.000 description 4
- 230000001360 synchronised effect Effects 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- 230000009471 action Effects 0.000 description 3
- 238000006243 chemical reaction Methods 0.000 description 3
- 230000008676 import Effects 0.000 description 3
- 238000012432 intermediate storage Methods 0.000 description 3
- 230000009191 jumping Effects 0.000 description 3
- 230000033001 locomotion Effects 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 238000012544 monitoring process Methods 0.000 description 3
- 230000001105 regulatory effect Effects 0.000 description 3
- 238000013517 stratification Methods 0.000 description 3
- 239000012634 fragment Substances 0.000 description 2
- 230000003993 interaction Effects 0.000 description 2
- 238000005070 sampling Methods 0.000 description 2
- 238000012384 transportation and delivery Methods 0.000 description 2
- 102100038520 Calcitonin receptor Human genes 0.000 description 1
- 101710178048 Calcitonin receptor Proteins 0.000 description 1
- 241001269238 Data Species 0.000 description 1
- 101000931570 Dictyostelium discoideum Farnesyl diphosphate synthase Proteins 0.000 description 1
- 241001234523 Velamen Species 0.000 description 1
- 230000003044 adaptive effect Effects 0.000 description 1
- 230000000903 blocking effect Effects 0.000 description 1
- 230000006835 compression Effects 0.000 description 1
- 238000007906 compression Methods 0.000 description 1
- 230000001276 controlling effect Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 101150020073 cut-2 gene Proteins 0.000 description 1
- 238000005520 cutting process Methods 0.000 description 1
- 238000000354 decomposition reaction Methods 0.000 description 1
- 230000003111 delayed effect Effects 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000016507 interphase Effects 0.000 description 1
- 238000003754 machining Methods 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 238000012856 packing Methods 0.000 description 1
- 230000000737 periodic effect Effects 0.000 description 1
- 238000004886 process control Methods 0.000 description 1
- 230000001902 propagating effect Effects 0.000 description 1
- 230000000246 remedial effect Effects 0.000 description 1
- 230000008521 reorganization Effects 0.000 description 1
- 238000013468 resource allocation Methods 0.000 description 1
- 230000000717 retained effect Effects 0.000 description 1
- 230000007704 transition Effects 0.000 description 1
- 230000001960 triggered effect Effects 0.000 description 1
- 239000011800 void material Substances 0.000 description 1
- 239000002699 waste material Substances 0.000 description 1
Images























Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/78—Architectures of general purpose stored program computers comprising a single central processing unit
- G06F15/7867—Architectures of general purpose stored program computers comprising a single central processing unit with reconfigurable architecture
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0811—Multiuser, multiprocessor or multiprocessing cache systems with multilevel cache hierarchies
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/0813—Multiuser, multiprocessor or multiprocessing cache systems with a network or matrix configuration
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F12/00—Accessing, addressing or allocating within memory systems or architectures
- G06F12/02—Addressing or allocation; Relocation
- G06F12/08—Addressing or allocation; Relocation in hierarchically structured memory systems, e.g. virtual memory systems
- G06F12/0802—Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches
- G06F12/0806—Multiuser, multiprocessor or multiprocessing cache systems
- G06F12/084—Multiuser, multiprocessor or multiprocessing cache systems with a shared cache
Abstract
至今,中央和全局单元已经组成一个对所有配置请求进行处理的模块。本发明提供了多个能够执行该任务的工作单元。这些单元排列成一种结构。如果该请求是无法处理的,则来自最低层的请求仅传送到下一个最高层。最高层与内部的或外部的更高级别的配置存储器相连,该配置存储器含有所有该程序运行所需的配置数据。配置单元的树形结构使得能够对配置数据进行高速缓存。配置主要是在本地进行访问的。在最坏的一种情况下,如果层结构中任何一个CT(配置表)中都没有相关的数据,那么就必须从更高阶的配置存储器中载入一种配置。
Description
的数据流处理器和模块的高速缓存配置数据方法
本发明的背景
技术水平
本专利说明书所依据的相关技术在专利申请书19654846.2-53对具有二维或多维可编程序单元矩阵(FPGAs,DPGAs等等)的数据流处理器和模块进行自动动态的重加载的方法以及专利申请书19654 593.5-53(可编程模块的运行时间重构方法)中已被阐明。其中阐述了按照相关技术对DFPs,以及FPGAs,DPGAs和类似的模块进行配置和重构的一种方法,采用这种方法时一种独立配置的中央高阶微控制器型模块承担了对多个低阶,且多半是无源的控制单对于配置数据的分配。
相关技术的缺点
通过使用一个中央全局单元控制对一个或多个模块的部分(例如单元)的重构,如果许多不同的重构请求必须同时进行处理的话,可能出现瓶颈。上述的模块平行性优点,受到了这种中央单元相当大的限制,因为这种机构显示了典型的“瓶颈”,并且明显地减慢了数据的处理。
另外将事件源指派给要被加载的配置表现出一些问题,因为配置存储器使用的是绝对地址。因此,该重构单元必须包含一种存储器管理系统,这种系统就象在操作系统中那样,还要有记录哪一部分存储器区域用于哪一部分配置的各种文档。
资源(例如CELs)的管理是一个附加的问题,必须保证,每个CEL只能精确指派给由重构请求启动的每个算法一次特别是对于还使用了其余周围CELs的算法更是如此,否则会出现死锁。
为了再一次明确重构的问题下面举出例子;
CELs的一个矩阵是被重构的并处于复位状态。每个CEL应当能指示,它是否处于重构的状态。在矩阵中的所有的CELs均已经处于被配置状态,因而处于重构状态。第1个配置例程(KR1)被加载,这时没有充分利用矩阵。被配置的CELs清除它们处于可配置状态的指示:与第一配置例程独立的第二配置例程(KR3)被加载到一组尚未配置的CELs中。第三配置不能加载,因为这需要第1和第2配置资源(KR3)的CELs,可是第1和第2配置的CELs正在使用,因此还没有处于可重构状态。
KR3必须停止直到需要的CEL释放,即KR1和KR2已终结为止。
在KR1和KR2执行过程中用于第4配置例程(KR4)和第5配置例程(KR5)的加载请求到达了,它们关不能立刻加载,因为它们使用的CELs正被KR1和KR2的使用,KR3和KR4部分地使用了同样的CELs,KR5不利用KR3和KR4的CELs。
为了重新加载KR3-KR5,有如下的要求:
1.KR3-KR5应当尽可能按加载请求顺序予以加载。
2.应当尽可能加载许多互相独立的KR,即不具有共同CELs的KR,以便获得最大的平行性。
3.这些KRs不应该互相阻塞,即KR3被部分加载,但不能继续加载,因为其它的CELs被部分加载的KR4阻塞,而KR4也不能继续加载,因为再次需要的CELs被KR3阻塞。这样会导致典型的死锁情况。
4.生成了KRs的编译器不能识别和取消KRs的时间的相互作用,使得不出现冲突情况。
实施电路的代价和最佳的结果之间的比率必须尽可能良好,即发明的目的是提供灵活的,平行的,无死锁的配置,它能以昼小的代价化费适中的时间和计算资源被执行。对此必须解决以下基本问题:
-如果只有KR3被加载,这种方法没有死锁,但不是最佳的,因为KR5也会(可能)被加载。
-如果KR3被加载,KR4未加载,然而KR5(已被)和KR4必须被预先标记,让它在后面的加载顺序中具有最大的优先权,这说明要有高的开销。
由以下过程来确保无死锁操作:
本发明任务和达到的改善
本发明的基本任务是一个单元-以下称为配置表(CT),它具有层次结构的,并且可在每一层次上出现多次,同时,CT5的数目以最低结构分层到最高结构分层逐步减少,直到最高层次刚好只有一个CT。每个CT各自独立地和平行地配置和控制多数可配置元素(CELs)。较高结构分层的CTs可以缓冲存储用于较低层的CTs的配置例程。如果若干个处于较低层的CTs需要相同的配置例程,该配置例程可被缓冲存储在较高层的CT中,并且由各介CTs调出,同时较高层的CT只需要一次就可把有关的配置例程比一个全局共同的配置存储器中调出,这就获得了一个高速缓冲存储效应。在除了用于可配置模块外本发明还可在微处理器,DFP等中具有多个算术单元的用作指令和数据的高速缓冲过程。同时可以按照应用需要取消几个下面所述的单元(例如FILMO),但是在层次结构上根本一点也没有改变。因此,这种使用可看作一个子集并且不再详述。与常规的高速缓存过程相比,上述方法的一个明显的优点是,数据和/或代码是有选择性地被高速缓冲,即使用了精确地适用于算法的方法。
同样,本发明能使大的单元结构被重构而完全无死锁现象。
发明的说明
代替象至今统一在模块中的一个集中的和全局的单位,该单位处理所有的配置要求,因有许多划分成等级(枝叉结构)排列的活动的单位,这些单位能够承接这些任务。
同时,最低平面的一个要求,如果该要求不能予以处理的话,那么只能继续导入下一个高一些的平面上。对所有存在的平面均要重复该步骤,直到达到最高的平面为止。
最高的平面连接一个置于内部的或置于外部的配置存储器,该存储器包含着所有适用这种程序运行所需要的配置数据。
通过配置单位的枝叉结构达到配置数据的一种隐藏处(内存)。
存取到配置上主要是以局部进行。如果有关的数据在划分成等级排列的CTs中不存在,那么在最不利的情况下必须把来自于置于上面的配置存储器的一个配置下载。以固定的时间的顺序输入应予以下载的配置,并且把这些配置归纳成为一个明细表,这样就避免了死锁。在下载前固定CEL的配置信息,这样在完成配置的整个明细表的工作过程中,CEL的状态信息保持不变。
CT的基本原理
一个配置表(CT)是一个活动的单位,它是根据同步,信息所谓的触发器,作出反应。触发器是通过一个两维或多维矩阵,由电子结构组件,用于通常的算术的或逻辑的单位,地址发生器,计算单位等等--以下称作可配置的元件(CEL)--所产生的。籍助于出现的触发器触发在CT内的一个规定的行动。这时CT的任务是控制多数的CELs并且规定它们的算术的和/或逻辑的运算。尤其是必须对CELs配置和变化配置。该任务CT承担,CT管理多数可能的配置例程(KR),这些例程在它们方面总是由单独的配置词语(KW)的多数组成,并且CELs的多数根据触发器条件以一个或若干个KR配置。同时,一个CEL总是包含一个或多个配置词语,这些配置词语配备了需要配置的CEL的地址。此时必须把一个KR完整地及准确地描摹到CELs的多数上,同时可以把若干个CELs联合成组。这些组以不同的但结构完整的KRs配置。在一个组内的所有的CELs进行错接,按照一个必需的重构的规定,通过一个共同的信号(ReConfig)通知所有编入组内的CELs,使每个CEL结束数据处理并且必须转入一个重构的状态。
无死锁的重构的基本原理
在达到运行时间的重构的系统上出现这样的问题,该系统会到达一种状态,在这个状态中总是有两部分互相等待,以致于进入了死锁状态。
通过一种新的配置总是只能完全地或者一点也没有地下载到系统中,或者使用一种Timeout方法,这个问题是可以避免的。
这样就产生了一系列的不利情况(需要的位置,运行时间等等),例如:
-如果一个配置不能下载的话,走到前面。
-配置下载的顺序的管理。
-动作中断,因为没有注意可能会下载到CELs中的其它的配置。
采用下面说明的方法可以排除这些问题。这是根据技术水平从一个DFP系统出发的。
从一个CEL开始,一个触发器信号发送给一个CT。该CT确定触发器源并且通过一个Look-Up表选出一个应下载的配置(KR)。阻止触发器信号继续深入,在当时的配置全部做完之前不再继续接受触发器。一个配置由若干个命令组成,它被传送给一定数量的CELs。当然,在一个达到运行时间的可配置的系统中不保证每个配置命令(KW)也能执行。这可能例如碰到下面情况而失败,已有地址的可配置的元件(CEL)还没有结束它的任务,这样就不能收到新的配置数据。为了避免动作中断,所有不能做完的配置命令(因为相应的CEL处于一个不可重构的状态,并且拒绝配置(REJECT),按照一个FIFOs在一个(后面作进一步的说明)专门的存储器(FILMO)中的最后的配置命令之后写出。然后,按照相同的方法,做完以下的配置命令。这一直予以重复,直到达到一个配置的终结为止。
然后,CT行进,又进入接受触发器的状态,以便可能继续下载配置。在这种状态下,CT通过一个计时器控制,每隔一定的时间做完FILMO。
在对原来(本来)应下载的配置进行处理之前,CT通过存储器FILMO,达到对这些应下载的配置的优先。通过FILMO的一个FIFO类似的结构来保证,在前面的触发器要求过程中不能完全做完的KWs,在新的应做完的WK之前自动保持一个比较高的优先权。在存储器FILMO做完时,对每个通过一个配置命令确定地址的可配置的元件,在发送一个KWs之前或发送一个KWs的过程中,进行试验,以确定其是否处于“重构”的状态。如果状态是“可配置”的(ACCEPT),那么传输,并且把数据从存储器FILMO清除。如果状态为“不可重构”(REJECT),那么数据保留在FILMO中,并在下次通过时重新做完。CT处理FILMOK中的下一个项目。
这种过程一再重复,直到FILMO达到终结为止。然后把通过触发器信号的出现而激活的原来(本来)的配置予以做完。同时FILMOs的结构符合FIFO的原则,即首先处理最老的项目。如果没有新的KR下载,为了能把FILMO也做完,则由一个时间器控制,每隔一定的时间通过FILMO。
其它的,没有参加的可配置元件(CEL)在该阶段平行地继续地工作,并且不影响其功能。这样就会出现这种情况,即在CT做完FILMO的过程中,一个或几个可配置元件(CELs)转为“重构”状态。由于CT随着做完会处于FILMO中的一个任意的位置上,因此可能出现下列情况:
CT试图做完第1个命令,其已有地址的配置的元件(CEL)不是处于“重构”的状态。这样CT就带着下一个命令(KW)继续前行。在同样的时间一个或几个可配置元件转入“重构”状态,其中也有通过第1个配置命令可能已作说明的可配置元件。CT处理第2个配置命令(KW),该配置命令利用这种相同的可配置元件(CEL),就象第1个配置命令那样,当然,这是来自于一个不同的配置。到这一时刻,可配置元件(CEL)处于“重构”状态,并且这命令能够成功地做完。
由此不再保证,应当首先下载的配置实际上也首先予以完成。那么为了完全地下载,会存在两个局部完成的配置,这两个配置总是需要其它配置的可配置的元件。进入了在图18中说明的一种死锁情况。配置A和配置B应当予以配置。CT已经把配置A和配置B的划影线的部分予以下载。配置A为了完成还需要配置B的浅双影线的范围,以及配置B为了完成或还需要深双影线的范围。由于两个配置还没有完全结束,这样也就没有作用功能,因此,对于两个配置没有进入终结状态中,两个配置的一个配置要予以删除。两个配置等待,仍然需要的可配置元件予以释放。
在本方法中采用下列方式避免死锁,即CT在做完FILMOs之前把握住所有可配置元件的这些状态,并且在结束该过程之允许再发生变化,或者不能识别出现的变化。换言之,或者固定在做完FILMOs之前所有可配置元件的这些状态,或者避免在做完FILMOs过程中这些状态的变化。一种可能实现的技术结构为,在每个可配置元件中使用一个寄存器,在该寄存器中固定做完FILMOs之前的状态。CT只根据把握住的状态工作,而不能跟随着可配置的元件的当前的状态。这样一来确保了每个应作处理的命令(KW)找到可配置的元件(CELs)的相同的状态。这个步骤不排除,在做完FILMOs的过程中,一个或几个可配置的元件转入“重构”的状态。这种变化对于CT来说,在进行处理的过程中并不是立刻就可以发现的,而是直到开始下一次通过时才发现。
配置顺序
准确地保持写入CEL的KW的顺序,对于达到已确定了算法的配置是绝对必要的。例如,把CEL连接到一个接口系统之前,首先应对接口系统配置,这样该CEL就不会连接到由其它程序所利用的接口上去了。换言之,如果事先能对相应的接口连接配置,CEL也只能配置了。
按照发明的方法,如下所述应保持一个固定的流程:
配置词,其输出对于后面的KWs的配置是十分重要的,尤其要作出标记(以下简称KWR)。如果一种这样的KWR打不中,那么在有关的配置程序内的所有的后面的KWs均要写到FILMO上,并且在该通过中不再输出。即使在FILMOs通过时,处于一个KWR后面的顺序中的全部的KWs在当时的流程中也不输出。
内存方法
CT结构是划分成等级建立的,即在一个模块中有几个CT平面。这种排列主要按照一种树枝结构(CT-Tree)。同时,根CT(Root-CT)是一个外部的配置存储器(CER),该存储器按配位包含全部的KRs,而可配置元件(CELs)排列成树叶片,它们调入各外KRs。以相同划分成等级的可配置元件总是配合均匀平面的CT。
每个CT分配一个局部的内存储器。如果新的KRs需要贮存而没有位置,或者这KRs明显地要求通过一个专门的CT命令(REMOVE)的话,该存储器局部地予以清除。此时根据一种清除策略实现KR方式的清除,最好的情况是,只清除那些不再要求的,或者明显地要通过REMOVE命令说明的KR。
同样,这些KR单独予以清除,清除的数量正好达到,为了把新的需要下载的KR写入到存储器中去,存储器恰好必需空出的位置为止。
该优点在于,每个处于一个随机的CTx下的CT,则下面在CT树枝(主干)的上部有一个KR,这个KR贮存在CTx中,不是通过外部的配置存储器ECR要求的,而是直接由CTx获得。以此产生了几个平面的内存结构。在CT树枝(主干)中的数据传递化费以及尤其是ECR所需要的存储器带宽明显降低。
换言之,每个CT中间贮存着处于它们之中的CT的KRs。即处于比较低的位置的CTs直接从处于比较高的位置的CTs获得需要的KRs,不需要把存储器存取到外部的ECR上。只是如果在一个处于高一些CTs中已经没有所需要的KR,那么才必须通过存取到ECR上下载KR。这样就得到了一个对于KRs特别有效率的划分等级的内存结构。
根据这种结构也能获得清除策略,当然应当视用途的不同根据经验来确定策略。可以有几种方法:
-清除最老的项目
-清除最小的项目
-清除最大的项目
-清除调用最少的项目
CT划分等级的基本原理
为了获得一个内存效应,CTs联接一个在树枝结构(主干结构)中的划分的等级。在各个接头(CTs)之间有一个接口系统(Inter-CT-Bus),总是一个上面的接头(CTs)连接几个下面的接头(CTs)。同时,下面的接头(CTs)从上面的接头(CTs)那里要求数据,上面的接头把数据输送给下面的接头。下面的接头互相之间交换状态信息,于此在比较高的接头之间使用网络,这些网络必须按照地址予以解开的。
CT划分等级和定地址
CT划分等级是这样安排的,即可以使用一个二进制树枝(主干)进行各个CTs选定地址。这表示,最低价的地址二进位制标出树枝(主干)的各个叶片(分片)并且每个进一步的地址二进位制总是选择比较高的一个划分平面。因此每个CT就具备一个明确的地址。
以下的表格表示,各个地址二进位制如何分配各自的平面:
| 3 | 2 | 1 | 0 | 地址宽度 | |
| - | - | - | * | 平面0:叶片 | 1 |
| - | - | * | * | 中间平面:1 | 2 |
| - | * | * | * | 中间平面:2 | 3 |
| * | * | * | * | 中间平面:3 | 4 |
*=已使用地址二进位制
-=没有使用地址二进位制
如果一个置于上面的CT配入一组CTs,则相应地汇总这组的几个地址二进位制。
下面的表格表示,各个地址二进位制如何分配各自的平面,同时在平面0上的一组带8个CTs(地址二进位制2…0):
| 5 | 4 | 3 | 2…0 | 地址宽度 | |
| - | - | - | * | 平面0:叶片 | 3 |
| - | - | * | * | 中间平面:1 | 4 |
| - | * | * | * | 中间平面:2 | 5 |
| * | * | * | * | 中间平面:3 | 6 |
| … |
*=已使用地址二进位制
-=没有使用地址二进位制
二进制树杆(主干)的结构可以是一维或多维,采用的方法是,每个维建立一个二进制树杆(主干)。
一个已确定的CT(TARGET)选定地址,采用的方法是,这个要开始的CT或者说明精确的目的地址,或者对TARGET相对选定地址。
下面进一步地说明对一个相对地址的处理:
这是一个用于二维选定地址的相对地址区域的例子:
如果应当选择下一个高的划分等级的CT,则代入比特15。比特14标出传播,那么选择所有的CT。X/Y地址列出从Initiator地址发出的TARGET地址。
这些地址为带有符号的“signet”整数。通过相对于现实的地址位置的地址区域有Y/X地址的加法确定TARGET。每个平面具备一个规定的地址宽度(Address-width)。加法器按照这个宽度。
在进行加法时有上越界或下越界则说明,已选定位置的CT不是处于实际的接头的下面,并且向处于这上面的CT继续给出位置要求(后面上一位的接头)。
如果没有出现上越界或上越界,TSRGET位于实际的接头下面。在实际的平面上计算出的地址二进制位(比特)(相应的表格)这样直接处于实际接头下的CT。由此出发,根据相应的地址二进制位(比特)总是选择下一个较低的CT(接头)。
在CT划分等级中存取的优先权
存取到Inter-CT-接口上是由一个促裁器进行管理的,在这方面,所有下面的接头有同样的优先权。上面这个接头具有高的优先第一位。因此,存取就是从一个较高的接头向下面传递,或者已经把一个由INITIATOR开始的宽的通道放在一边,考虑了其它的存取。
一个CT的基本结构
下面的有关CT的概要可以综合说明各个结构组类的情况。下面对结构组类进行详细的说明。
一个CT的核心是控制状态机(CTs),该控制机控制配置例程(KRs)全部做完。配合CTs的有,Garbage收集器,该收集器控制从CT的存储器(CTR)中清除KR;FILMO,该FILMO管理仍需要做完的KWs,以及LOAD-状态机,该机器控制KRs的下载。
该存储器(CTR)的装备是作为通常的书写-阅读-存储器,同时可以用来执行所有的技术任务,以及用来对各自的CT以及置于其下面的CTs的KRs进行局部贮存。作为特殊情况存储器(CTR)也可以装备为ROM,EPROM,EEPROM,Flash-ROM等等,为了给模块配备一个固定的,ASIC或类似PLD(见技术的水平)的功能作用。
为了设计CTR地址使用4个作为下载的计数器装备的指示器:
1.空位指示器(FP)。显示在CTR中最后的KR之后的第1个空的存储器位置。
2.Garbage指示器(GP)。显示通过Garbage收集器(GC)应当从CTR中清除的一个项目。
3.运动指示器(MP)。显示在CTR中的一个存储器位置,从这个位置上一个有效的,不应当清除的配置词(KW),就是说一个KR的一个项目,向着通过GP确定的项目上复制/运动。
4.程序指示器(PP)。显示瞬时由CTs输出的KW。
KW通过一个输出分界面继续输向有关的CELs上。一旦它们是在一个重构的状态接受KE的话,CELs应答(指令)(ACCERT)。如果一个KW没有被应答(REJECT),那么在一个类似FIFO的存储器中根据时间予以中间贮存,以便在后面时间内,不利用程序指示器,而重新在选定地址的CEL上写出。
做完一个KR的要求包括通过触发器信号的这些CTs。触发器信号经过一个屏蔽,这是一个滤波器,它把不需要的触发器滤掉。按照技术水平可以通过UND取能元件建立一个屏蔽,该屏蔽把一个触发器和一个输出信号进行UND连接。触发器经过具有优选作用的Round-Robin-仲裁器(SCRR-ARB)转换成二进制信号。一个具有优先作用的Round-Robing-仲裁器把一个Round-Robing-仲裁器的同步解答的优点和以一个节拍对下一个输出的识别结合在一起,就是说,这是一个优先第一位-仲裁器的优点。
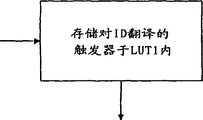
已屏蔽的触发器作为地址连接到一个第1 Lookup表(LUT1)上面,这是一个存储器,这个存储器把有关的KR的ID配位给作为地址进入的触发器,并且在数据线路上输出。
在一个第2 Lookup表(LUT2)中,KR的ID配位给在CTR中的KR的存储器位置的地址。该第2 Lookup表不仅进行触发器信号的配位,更多的是利用命令,这些命令使用一个ID作为参数,LUT2同样进行地址配位。
触发器信号针对有关的Ids的配位是下面阐述的命令(REFERENCE)记入到LUT1中。LUT2的管理,就是说Ids针对CTR中的地址的配位,通过CTs和GC自动发生。
为了更好地理解CT,下面列出一个可能的命令句子:
1.BEGIN<ID>
通过BEGIN<ID>表示一个配置例程的开始。<ID>说明配置例程的明确的识别号。
2.STOP
通过STOP表示一个配置例程的结束。在这个位置上,配置表(CT)结束配置例程的处理。Garbage-收集器(GC)结束该配置例程的项目的清除。
3.EXECUTE<ID>
跳向一个配置例程的开始(BEGIN<ID>)。如果该配置例程没有在该CT的存储器中,那么由置于其上面的CT对其予以要求,或者从存储器中出来予以下载。
4.LOAD<ID>
要求置于其上面的CTE KR<ID>。
5.REMOVE<ID>
调入GC,以便肥从开始(BEGIN<ID>)到结束(STOP)的配置例程<ID>从该CT的存储器中予以清除,并且把后面的配置例程不断推进,直到不存在由于清除配置例程而形成存储器孔为止。
6.PUSH<FORCED><ADDRESS><DATA><EXIT>
把配置数据<DATA>写到寄存器上<ADDRESS>。如果代入<FORCED>,即使不代入有关的目的寄存器的RECONFIG-Flag(旗),也要写上数据。使用<EXIT>并应当显示,这关系到一个KWR,它通过REJECT中断后面的KWRs继续输出。
7.MASK<SR><TRIGGER>
采用<TRIGGER>代入触发器屏蔽,或采用<TRIGGER>把它复位,取决于<SR>(Set/Reset)。
8.WAIT<UNMASKED><TRIGGER>
停止配置例程的处理并且等待触发器<TRIGGER>。如果代入了<UNMASKED>,则不管触发器-屏蔽的状态,记录到所希望的触发器上。
9.TRIGGER<TRIGGER><CT#>
把一个触发器的二进制值发送给置于上面的通过CT#选定地址的CT。
10.GETBUS/GETCTS
建立相对于Inter-CT-Bus的连接。
11.LOOSEBUS/LOSECTS
解除相对Inter-CT-Bus的连接。
12.REFERENCE<TRIGGER><id>
把数值<ID>在地址<TRIGGER>条件下写入LUT1,以此把一个规定的KR配位给一个触发器信号。
这些命令EXECUTE,LOAD,REMOVE,PUSH,MASK,WAIT,TRIGGER,REFERENCE只在BEGIN…STOP括号以内有效。在这个括号以外不输出这些命令。
一个配置例程(KR)的结构看上去就象如下这些情况。
BEGIN<ID>:
适用的命令
STOP;
间接寻址(引用)
CT中的高速缓冲存储器原理,能够在CT上对KR进行缓冲存储,并可从多个不同的较低层CTs或CELs中使用KR。
若较低层的单元访问模块(如RAM,外围设备)的外部接口,则有必要存储不同的地址或外部接口的各个部分。这将使所需的各个KR的内容根本不同。无高速缓存的可能性。
间接引用提供了一种补救办法。为此须使用包含和设定了必要的外部参数的特殊KR(以下称IKR)。也许其它不同的KRs可以经过触发器调入到不同的分级层面。从IKR的末端调入实际的KR。不过,IKR是无法高速缓存的,而被调入的KR是完全一致的,因此是可以高速缓存的。建议将IKR的大小减少至绝对最低值,也就是外部的和不同的参数以及对一致的KR的调入。
间接配置例程(IKR)可如下设定:
BEGIN<ID>;
…
***;有效命令,仅可启动外围设备,
TRIGGER<ID>;启动、停止或加载对外围处理的请求。
…
GOTO<ID>;跳跃至一致的KR。
特例:
1.WAITL FOR BOOT
此命令仅适用于CTR的第一地址。在引导过程中,完整的Boot-KR初始化时被写入CTR,但不写入Boot-KR BEGIN<0>的开始序列。在Boot-KR BEGIN<0>处(地址1)是WAIT-FOR-BOOT,可在RESET时自动设置。只有当整个Boot-KR被写至CTR之后,WAIT-FOR-BOOT可用BEGIN<0>进行复盖,CTS开始处理Boot-KR。
WAIT-FOR-BOOT不得在一个程序内出现。
2.BOOT<CT-ID>
BOOT<CT-ID>表明了后面的Boot-KR应写至哪个CT中。在Boot-<CT-ID>之后不是BEGIN,Boot-KR不是通过STOP,而是通过随后的一个BOOT<CT_ID>关闭。STOP结束引导过程。
BOOT<CT-ID>不得在一个程序内出现。
引导过程
在RESET之后,最上面的分级面(ROOT-CT)的CT将Boot-KR调入下面分级面的CTs中。因此,在到达一个所规定的地址(BOOT-ADR)时出现跳跃,即列入ROOT-CT的外部配置存储器(ECR)。ROOT-CT执行此跳跃,获得引导程序。可进行如下设置:
BOOT<CT-TD1>;COMMAND;COMMAND;…
BOOT<CT-TD0>;COMMAND;COMMAND;…
…
BOOT<CT-TDn>;COMMAND;COMMAND;…
STOP;
在引导过程中,整个Boot-KR首先写至从通过<CT-ID>列出的CT的地址2开始的CTR中。Boot-KR(BEGIN<O>)的开始程序并不是写至地址1中。在此位置上是WAIT-FOR-BOOT,可在RESET时自动设置。只要当整个Boot-KR被写至CTR之后,并且ROOT-CT到达随后的BOOT<CT-ID>,STOP才可被写至Boot-KR末端的CTR上,用BEGIN<0>修改WAIT_FOR_BOOT。CTS开始处理Boot-KR。
配置程序的调入
为了在Boot-KR之外请求一个配置程序,须有三大基本机理:
1.通过CTS执行LOAD<ID>
2.通过CTS执行EXECUTE<ID>,在CTS中并不含有相应ID的KR。
3.经LUT1传输至一个<ID>的触发器的出现,在CTR中没有所属的KR。
这三种情况的过程是一样的:
在作为地址的LUT2中列出被请求的KR的ID。此LUT2检查,是否在CTR中有一个有效的地址。若没有,也就是说,<ID>在LUT2中显示为0值,则load<ID>被传至CTS。
接着,在分级的上级CT时,CTS请求与<ID>有关的KR。此请求在一个触发器的模子中到达上级的CT,并相应地对其进行计算。
此上级的CT将被请求的KR传送到发出请求的CT。这些数据从FREE-POINTER(FR)所显示的地址起被写进CTR,此FR在每一次记录存取后提高一位。
如果FR到达了CTR的上限,则须调入无用数据集合器(GC),以清除CTR内的最下层KR以及压缩CTR。FR就这样重新设置了。此过程一直到即将调入的KR完全与CTR相配时才算结束。
配置存储器的跳跃表
分配到ROOT-CT的配置存储器包括在使用时必须调入的所有KR。在外部配置存储器(EDR)中,在一个所规定的地址(ADR-BOOT)有一个进入引导配置程序的跳跃。而在另外一个所规定的存储器范围(LUT-ECR)中,任意的然而在使用内部预定的长度可跳跃到各自的KRs。任何一个KR的<ID>可在ECR中作为地址使用,而任何一个KR的起动地址均在那儿;KRs间接寻址如下:
TD→LUT-ECR→KR
在配置存储器中改变KR
应改变ID<A>的KR。首先,HOST将ID<A>中的新KR写到ECR中的一个空余的存储器位置。ID<A>将与配置存储器中的KR新地址一起,从上级单位(HOST)写到一个预定的ROOT-CT寄存器上。此ROOT-CT将命令REMOVE<A>发送到所有下级CT中。然后在达到STOP或者在IDLE循环(只要不执行KR)时,所有CTs消除了CTR中的与ID发生关系的KR,将LUT2设置到“NoAdy”的地址<A>,也就是说,在LUT2的ID<A>中不存在有效的地址输入。若ID<A>重新获得请求,进入LUT2的位置<A>处的那个缺少的输入(“NoAdy”)强制每个CT重新请求ECR中的KR<A>。
FILMO
KR主要由命令PUSH组成,此PUSH可将新的配置语言写到一个特定的地址上。如果无法写入型号KW的配置语言,因为此具有地址的可以配置的元件(CEL)不愿意接收新配置(REJECT),则此配置语言并非被写到那个具有地址的可以配置的元件(CEL)而是被写到下面称之为FILMO的一个存储器上。后面的命令可得到正常运算,直到一配置语言无法重新写入为止,该配置语言然后再写FILMO中。
若无法写入型号KWR的配置语言,因为此具有地址的可以配置的元件(CEL)不愿意接收新配置(REJECT),对此配置语言并非被写到那个具有地址的可以配置的元件(CEL)而是被写到下面称之为FILMO的一个存储器上。所有后面的命令(至KR末端以下)封锁地写到CEL而是直接写入FILMO上。
FILMO将在IDLE循环时和在一个新的KR每次执行前得到完全运行。因此,在启动最老的数据字时并且与技术状态的FIFOs相一致,任何一个被读出的FILMO语言须传送至具有地址的元件上;因而,此具有地址的元件必须乐意接收此配置语言。只要这些数据字从一开始就可以写入的话(也就是说,那些具有地址的可以配置的元件(CEL)已作好准备),则必须按照一个FIFOs的方式清除FILMO中的输入。如果无法写入配置语言,那么须跳过它,不要从FILMO中清除。与一个FILMO相反的是,这些数据可以在跳过的配置语言之后继续读出。在一个跳过的配置语言之后可以写入的配置语言可根据FILMO的自动编码或者①:写入时作下标记,不要从FILMO中清除,这样写入时作下标记的配置语言在随后的运行时不能被读出,而是马上被清除,只要没有一个被跳过的配置语言在它们前面出现的话;或者②:从FILMO清除,这样这些配置语言在被清除的配置语言之前和之后均继续存在,因而为了得到清除,须将后面的语言移至前面(上面)或者须将前面的语言移至后面(下面),因此无论如何须保留配置语言的顺序。
若执行新的KR,则那些从CTS中无法写入具有地址的元件(CELs)的配置语言(KW)将重新跟踪至FILMO,也就是说,KW将写入FILMO的末端(读带方向)。如果FILMO已满,即不存在配置语言的空余输入,则KR的执行将终止。FILMO一直等到写入了足够的配置语言而且相应地出现了许多空余的输入时才结束运行,而KR将继续执行运算。FILMO提供了一个与FIFO相类似的存储器,可始终从最老的输入开始直线运行,而与FIFO不同的是,可跳过输入(首先在线性多路出口)。
配置表Statemachine(CTS)的功能
CTS行使对CT的控制。它执行KR的命令,并反应到触发器上,它行使对FILMO的管理,可以在IDLE循环以及在执行KR前读出FILMO。它反应到由LUT结构所产生的信号illegal<TRG>(非法触发器,可参见图1,0102)和load<ID>。当LUT2上出现高速缓冲存储器失败(0105)或者通过ID而查询的KR/IKR消除标记(0107)时,才会产生load<ID>。它反应到上级CT的控制信号上。
处理命令的自动编码举例,请参见图2-7。
控制信号的上级CT
-illegal<TRG>(0102)
向上级CT表示,出现了一个不明触动器<TRG>。
-load<ID>(0105/0107)
询问上级CT以调入<ID>。
-trigger<TRG>(CT#)(0108)
发送一个触动器(TRG)到上级的或者具有地址的CT<CT#>。
上级CTs的控制信号
-remove<ID>(参见图15,1513)
询问CT以清除<ID>
-write_to_FP<data>(参见图2,0205)
发送数据到CT。数据跟踪到被占用的存储器的末端。
无用数据集合器的功能(GC)
CTR受到两个问题的制约:
1.指点LOAD或者EXECUTE命令以及触发器注意ID,ID中的KR在CTR中是没有的,必须由KR自行稍后调入。然而有时候在CTR中调入被请求的KR时又没有足够的空间。
2.出现REMOVE<ID>时须从CTR中清除相应的KR。这样,只要不位于CTR的末端,就会出现一个间隔。在调入新的KR时,有时候此间隔不能重新完全被填满,或者此间隔对新的KR来说是太小。这将会导致一个CTR的局部图。无用数据集合器的任务就在于,从CTR中清除KR,以便为新的输入创造空间而且在清除输入后重新组织CTR时须将所有剩余的KR作为闭合程序块串联在存储器上,将那些空置存储块作为一个闭合程序块安置于CTR的末端。
这样,新的KR就可以在最佳方式和毫无损失地补充调入到存储位置上。
触发信号的利用
每一个CT均可连接到属于其各自的分级面的多个触发器信号上,这些触发器信号再聚集到总线上。这些详细的触发器将在一个屏蔽上得到利用,也就是说,仅能中继传输自由连接的触发器信号。这些自由连接的触发器信号将节拍同步地中间存储在一个抽样寄存器中。操作员可选择其中的一个被存储的触发器信号,将此信号转化成一个二进制向量。被选择的触发器信号可从抽样寄存器中得到清除。此二进制向量可中继传输到第一个搜索图1(LUTl),该LUT1再将二进制向量转换成得到请求的配置程序(KR)的标识号码(ID)。此ID在第二个搜索图(LUT2)中再转换成CT存储器(CTR)中的KR地址。CTS(CT-Statemachine)将其程序指示器(PP)设置到这个地址上,并开始执行KR。前提条件是,任何一个在屏蔽上自由连接的触发器在LUT外均有一个相应的输入。如果没有,那么这一错误状态将中继传输到CTS上(非法触发器),因此等同于“NoAdr”的每一个ID可计算为非存在的输入。“NoAdr”是一个依赖于自动编码的可选择的标识。
若在LUT2上缺少输入的话,也就是说,与ID有关的KR并不在CTR上,那么调入请求须被发送至CTS上(load<ID>)。
触发信号发送到上级CT
在已说明过的到达上极CT的接口以调入KR之外,还存在着另外一个接口,可对自由定义的命令尤其是触发器向量进行互换。因此一个CT或者向所有其它CTs发送一个命令(BROADCAST),或者向任意一个具有地址的CT发送一个命令(ADDRESSED)。
此命令“触发器向量”(Triggervector)提供了一个二进制值,可在接收到CT的LUT2中加以输入时查询。
发送触发器向量是很有必要的,如在一个IKR内部在另外一个CT中起动KR,如调节外围设备或存储器。
为了中继传输触发器向量到一个上级CT,须存在两个机理:
1.此LUT1须补充一个比特,说明存储器的内容被视作KRID或者被视作触发信号的二进制值。若有一个触发信号,则LUT1的数据内容可直接作为触发器发送至上极CT。
2.一个触发器的二进制值以命令TRIGGER就可说明它可直接发送至上级CT。(也可有选择性地直接传输ID而不是触发器值)。
在触发器向量上的一个外部CT中起动KR时,为获得无死锁必须实施同步方法。此方法必须注意的是,仅仅是在CTs特定的小组内的一个KR在这个小组内的其它CTs上起动其它KR。多个KR的起动同时可以导致CTs之间的死锁,与CEL等级上已经描述过的死锁相类似。
上述方法的基本原则如下:
一个KR的结构如下:
GETCTS/GETBUS
TRIGGER<ID>,<CT#>
TRIGGER<ID>,<CT#>
LOOSECTS/LOOSEBUS
CT(INITIATOR)中的KR内部的命令“GETCTS”表明下面信号将发送到其它CTs〔TARGET〕中。用Trigger<ID>,<CT#>,一个正在起动的KR的ID将随同唯一的IDCT#发送到CT上。触发器的发送首先到直接的上级CT,它与CT#相一致将触发器发送至CT范围内的一个新的下级CT或者发送至它那儿的上级CT(可参见CT分级)。若这一命令到达了TARGET,则TARGET可应答接收。
在通过一个CT的命令运行时,此命令的优先识别总是上升一位。结果一个命令的中继传输请求碰到一个CT内的另外一个请求时,那这一命令将会拒绝最低级的优先。因此a)须确保,在一个相冲突的系统内同一时间只传输一个因而也只能起动一个KR,而一个KR可引起所需要的无死锁。
b)须确保,拒绝迄今为止至少仍在传播的命令,而此命令可引起性能的提高。
在拒绝一个命令后,在GETCTS/LOOSECTS内部的所有上述的命令均被同样拒绝,也就是说,INITIATOR向所有TARGET发送信号DISMISS,而执行KR将在一段等候时间之后重新在GETCTS时起动。
在一个指令区段GETCTS…LOOSECTS内的所有触发器的应答将被发送到INITIATOR-CT。在每一次即将到达的应答时,对下一个指令的处理仍将继续进行。
在获得指令LOOSECTS时,INITIATOR向所有TARGET发送了信号GO。因此TARGET-CTs与由触发器传输的ID一起起动执行KR。
TARGETs在出现一次触发器之后变化成下面一种情况,即此时它们在等待着GO或DISMISS信号的出现。
由于更好的可自动编码性,另外可以看到一种很容易修改的方法:在分级层面的一个小组的CTs之间有一个总线系统(Intex-CT-Bus)。此总线系统连接了所有该小组的CTs和一个直接归属于该小组的CT。
通过此指令GETBNS(与功能性的GETCTS相类似),此总线系统将由一个CT判断。这些指令将经此总线系统被中继传输至同一小组的CTs。如果在该小组内没有具有地址的CT#,则可通过此上级CT自行判断其上级总线,此指令将得到中继传输。这些受到判断的总线将仍然分配INITIATOR并因此禁止所有其它的CTs,直至要么发生拒绝,要么指令LOOSEBUS分解总线为止。LOOSEBUS可与LOOSECTS相比较。在执行指令LOOSEBUS前,GO信号被发送至所有参与的CTs。这可以要么通过指令LOOSEBUS要么通过一个特有的预起动的指令进行。指令和触发器将同样按照早已描述过的基本方法予以处理。当一个总线系统无法得到判断时才会发生拒绝。在判断时,一个等级的CTs总是马上获得优先,上级CT具有更高的优先。在Intet-CT-Bus上面发送一个指令时,此指令必须一直保持活动状态,直至具有地址的CT接受该指令(ACCEPT)或拒绝(REJECT)为止。
优先的Round-Robin-仲裁器
优先的Round-Robin-仲裁器(单循环-Round-Robin-仲裁器SCRR-ARB)具有时钟同步的构造,即在每个-根据执行情况正的或负的-时钟周期间隔(TFI)仲裁器都提供一结果。进入信号(ARB-IN)通过一个屏蔽(ARB-MASK)传送,这个屏蔽由仲裁器本身根据下述过程自动管理。屏蔽的输出信号根据相关提供给技术优先仲裁器(ARB-PRIO),对每次周期间隔(TFI)仲裁器与系统时钟同步地输出一个结果(ARB-OUT),即:在屏蔽(ARB-MASK)后的最高优先级的信息的二进数值。一个信号(VALID)被指定给该结果,此信号表示这个二进数值是否有效。根据优先仲裁器的实施情况可以在有信号0时和在无信号时产生同样的二进数值:在这种情况下VALID表示:如果无信号存在则结果是无效的。这个信号是:
1.作为仲裁器的结果被输出。
2.送到一个解码器,这个解码器把一个3-位二进数值解码为例如下表所示的二进数值。(这个编码过程按照此原则适合于任何所需的二进数值)。
| 二进数值 | 解码 | 注释 |
| (ARB-OUT) | (ARB-DEC) | |
| 111 | 0111111100111111000111110000111100000111000000110000000111111111 | |
| 110 | ||
| 101 | ||
| 100 | ||
| 011 | ||
| 010 | ||
| 001 | ||
| 000 | 复位状态和当二进数值(ARB-OUT)无效时 |
一个寄存器(ARB-REG)被附加于解码器,这个寄存器在反问于TF1的节拍脉冲(TF2)时接收解码器的解码的数值(ARB-DEC)。ARB-DEC被反馈到屏蔽上(ARB-MASK)并且释放单个的输入信号(ARB-IN)。
在处理器中的作用过程如下:
1.在一次复位RESET以后所有的ARB-NI(输入信号)通过ARB-MASK(屏蔽)被释放,因为ARB-DEC(解码器)把所有的信号都调到“释放”上。
2.被设置为最优先的ARB-IN(例如上述表格中信号7(二进111)拥有最优先权和信号0(二进000)最不优先)被作为二进数值输出。
3.经过ARB-DEC信号被闭锁,一旦所有其它输入更为优先却未被设置。
4.下面的第5和6步一直重复,直到信号O(二进000)被到达,或在ARB-MASK后面没有信号为止。然后ARB-DEC(参见解码表)释放所有通过ARB-MASK经过ARB-DEC的信号并且流程在第2步处开始。
5.此时起最优先设置的ARB-IN被作为二进数值而输出。
6.一旦所有其它的输出更为优先却未被设置,信号经过ARB-DEC就被锁闭。(继续第4步)。
这样就可以同等地处理所有输入信号并且在输入信号(ARB-IN)中的一个的每个节拍循环时把所有输入信号解译成二进值和输出(ARB-OUT)。ARB-REG可以配一个激活一输入(EN),它只有在TF2时才允许寄存器内容的修改,如果有相应的信号存在。由此,一个二进矢量不再在每个节拍时被输出,而是同通过EN和TF2产生的释放相关。当后面的转换在一个节拍循环中不能执行处理,而需要多个循环并且然后才接受下一个二进矢量时,输入对于同步就是必要的。
在信号的大多数同等优先时,也许一系列信号通过处理器被认为较为优先是有意义的。这例如在前面描述的用于在CT之间继续传送信号的方法时是必要的。为了使一个信号更为优先,ARB-PRIO的最优先的连接并不遮蔽,即:从屏蔽(ARB-MASK)旁传送过。由此信号被优先处理。
在微控制器的基础上的CT的构造
同至此的描述不同,一个CT也可以在一个微控制器结构里被执行。
很容易理解:那些基本功能,如触发器控制,查看表LUT1和LUT2,以及CT间通信和把KW写入CEL都直接可以由一个微控制器执行完成。只是一个效率高的FILMO的结构有个首先在可达到一性能里就被查觉出的问题。因此,FILMO的结构被特别地研究了。
FILMO的结构
FILMO未被作为单独的存储器。这个普通的程序存储器更多地被扩展了FILMO-功能。因此一个附加的位(FILMO-位)被分配给每个KW,它表明相应的KW是否已被写入CEL。如果FILMO-位被设置,那么相应的KW就不被执行。在把一个KW写入存储器时FILMO-位被复位。在CT内的所有KR都经过一个链接表(FILMO-表)按顺序相互连接,就象它们被触发器或LOAD<ID>调入那样。一个KR一直在FILMO-表中,直到它完全被执行,然后它被从表中去除。FILMO-表按照FILMI-方法运行并由此成为FILMO-存储器的一个直接的替代物。
(为了完善性,可以看出同原来的FILOM-方法相反在表中一个KR不能再次出现。如果一个还在FILMO-表中的KR被调用,那么它的执行必须被延迟,直至它被从FILMO-表上去除。)
一个FILMO-存储器位置的结构如下:
| FILOM-位 | KW |
命令
微控制器支持下列对FILMO有直接影响的命令:PUSH 把一个KW写入CELPUSHSF 把一个KW写入CEL并且当KW被接受(ACCEPT)时设置FILMO-位PUSHRET 把一个KW写入CEL并且从子程序中返回(RETURN),当KW未被CEL
接受时(REJECT)。这个命令被使用,当在KR中的接着的KW取
决于这个KW的配置时(ACCEPT);其配置由从KR返回而妨碍,
直到PUSHRET成功(ACCEPT)为止。PUSHNR 把一个KW写入CEL,只有在前面在KR内部未出现REJECT时。
作用同PUSHRET相似,用于使用在配置顺序中对KW的依赖性。
垃圾箱
同至此的说明相符合,一个垃圾箱(GC)被用于删除不再需要的KR。当在存储器中没有足够的空间装载新的KR和ID必须被删除时;或者当一个KR明显地由命令REMOVE-显示所要删除的KR的ID-被删除时,GC启动。
为了使GC-过程尽可能简单,所有的KR都通过一个链接的清单相互联系。GC流览一遍清单并且删除那些不再需要的KR,通过这些KR被其它KR覆盖和清单登录被相应地适配来进行删除。此时所有在存储器中留下的KR相应地移动,使由于删除了KR而产生的存储器空位被填补并且在存储器的最后产生一个更大的相连的自由空间。
一个KR的结构
在下列表中列出了一个KR的可能有的基本构造:
| jmp START |
| Iength |
| garbage-previous |
| garbage-next |
| FILMO-previous |
| FILMO-NEXT |
| CACHE-statistic |
| KR-statistic |
| START |
| ret |
在KR开始时产生一个跳跃经过后面的控制器来启动命令序列。紧接着是双倍链接的用于垃圾箱的清单,在这个清单中所有的KR相互连接。
“length”说明了KR的长度。这个信息可以根据技术版本状况用于Block-Move-命令(程序块-移动-命令),这些命令在KR必须在存储器中移动时(垃圾,装载等)被应用。FILMO在紧接着的双重链接的清单中组成,此时只有含有那些尚未被写入CEL的KW的KR是相互连接的。产生一个关于高速缓冲-状态的统计,它包含例如KR的调入次数(每调入一次数值被提高1)、时效(根据通过KR的GC-过程的数量可测得)等。这个统计可以在一个KR必经被从存储器空间中删除时统计分析GC。对于高速缓冲,通过这些统计产生了很大的优点。这样可以例如根据所使用的高速缓冲-算法,同应用的要求相适应来给微控制器编程,以致
1.最旧的/最新的KR
2.最小的/最大的KR(参见登录“length”)
3.最少的/最频繁的调入的KR被从高速缓冲中删除,当需要空的存储器时。此时显而易见的其它有用的状态信息可以被存储,此种选择性的缓冲在现有所熟知的高速缓冲-结构中已不可能了。特别是在高速缓冲中可自由编程的高速缓冲算法根据现有的技术不被支持。
最后有一个KR一统计,它包含例如未被配置的(REJECT)或被配置的(ACCEPT)KW的数量。同时第一个还需必配置的KW的地址可以被存储。它的优点在于:在一次FILMO-过程中可以直接跳到KW上面不必经过KR,这样就大大提高了性能。
最后对于KR要说明的是被链接的清单优先地通过登录前一个/后一个-ID被组成,因为由此绝对的存储器地址可以由GC毫无问题地移动。在一个KR中应只应用相对跳跃而不是绝对跳跃,来避免在装载KR时和在GC-运行过程中产生问题,因为此时绝对地址会改变。
为了完善性,须提出的是根据已说明的原则在使用微控制器时在执行一个新的KR前(基于一个触发器或一个命令,也从另一个CT开始)FILMO也要经过并且在经过FILMO之前CEL的状态(可变换配置的或不可变换配置的)要被保证。
图
下面描述的图借助于一个执行例子说明了根据所介绍的方法进行的配置数据的管理:
图1:在查寻表中产生地址的方法
图2-7:处理命令和状态仪器的功能
图8:SCRR-ARB的结构
图9:LUT1&LUT2的结构
图10:指针算术和CTR的结构
图11:FILMO的结构
图12a:CT的等级配置
图12b:在CT之间的触发器的发送
图12c,d:触发器矢量的发送方法
图13:通过多个IKR来调入一个KR
图14:一个ROOT-CT的LUT1的结构
图15:一个ROOT-CT的HOST-控制结构
图16:说明LUT和ECR概念
图17:中间等级层的CT以及一个ROOT-CT的过程控制
图18:在一个2-因次的数组的配置时的死锁扣问题(参见专利说明)
图19:说明FILMO-概念
图20:CT间通信的基本原理
图21:根据GETCTS-方法的CT间通信的执行举例
图22:根据GETBUS-方法的CT间通信的执行举例
图23:CT间母线的排线结构
图24:在CT-等级里的地址
图25:垃圾-清单
图26:FILMO-清单
图27:在KR里的FILMO功能
图28:在执行一个KR或FILMO前存储状态
图的说明:
图1显示了在一个CT里的CTR-地址产生的过程。此时在LUT1里的一个详细的二进的触发器矢量(0101)被翻译到一个有效的KR或IKR ID上。如果没有有效的ID存在,那么就产生一个信号“非法触发器”(0102),此信息说明触发器在LUT1里不被识别。这个问题可以作为错误信息被中继传输到上一级CT上或被忽略。从“触发器”到“ID”的翻译借助于“REFERENCE”(参考)命令被登录到LUT1上。一个有效的ID(0103)被中继传输到LUT2上。在命令内部通过一个运算数说明的ID(0104)直接到达LUT2上。LUT2把一个详细的ID翻译到在CTR内部的KR/IKR的地址里。如果KR/IKR未被存储到CTR里(不在高速缓冲里),那么信息“Miss”(缺少)将被产生(0105)。如果KR/IKR的被翻译的地址标有信号“NoAdr”,那么用“No Entry”(0107)表示地址被删除。“Miss”和“No Entry”表示不可以翻译到CTR-内部的地址上。在此信号的基础上,装载-状态机用一个相应的置于其上的CT的ID再装载KR/IKR。
只要存在一个有效的地址,那么这个地址就被传送到地址发生器的指针算法上(0106)。在LUT1中一个详细的二进触发器矢量被翻译成一个ID或者另一个触发器矢量,此时在这种情况下触发器矢量被输出(0108)。
在图2中,在装载一个KR/IKR时的过程被说明。首先,要被装载的KR/IKR的ID(0201)被传送到置于其上的CT上。然后,在所要求的ID的登录处自由指针(FP)的数值被登记到LUT2中。FP指向在CTR中的最后一个用于一个KR/IKR的登记后面的登记,这是第一个在其上存储了要装载的KR/IKR的登记。
状态机等待置于其上的CT的数据字句。一旦字句可用,它就被写入由FP指出的位置上。FP被增量,如果FP指向CTR的末端后的登录,那么在CTR里的第一个登录被去除,用以创造空间(0202);此时FP被实现。如果由在其上的CT发送的数据字句为“STOP”,那么装载过程被停止(0203),否则,继续等待一个新的数据字句(0204)。
在图3a中,表示了“MASK”-命令。命令的运算数被写入MASK-寄存器中。MASK-寄存器位于LUT1前的触发器信号的输入之前并且标出无效的触发器。
在图3b中,命令的运算数通过命令“FRIGGER”被作为触发器矢量发送到其它CT上。
在图3c中,对于相应的KR/IKR ID的触发器翻译被通过命令“REFERENCE”写入LUT1。
在图4a中表示命令“WAIT”。命令的运算数据写入WAITMASK-寄存器。所有触发器,直到所等待的和由此在WAITMASK中释放的,都被忽略。只有在触发器后才返回到程序流。在图4b中,“PUSH”-命令被描绘。配置字句被发送到定址的可配置的元素(CEL)处。如果CEL不接受配置字句,由于例如CEL处在“非配置”状态下,那么配置字句被写入FILMO中(0401)。
图5指出“REMOVE”-命令的过程。有2个调入变量:
1.第1个在CTR中的KR/IKR被从CTR中删除,CTR的地址被分配给垃圾指针(GP)(0501)。
2.一个专用的由其ID说明的KR/IKR被从CTR中删除。在CTR中的要删除的KR/IKR的第1个地址被分配给垃圾指针(GP)(0502)。
移动指针被装载了GP的数值。就算首个KR/IKR应被从CTR中删除,GP和MP也要指向CTR中的一个“BEGIN<ID>”一命令。相关的ID的LUT2中被标为无效。MP被增量,直到下一个在存储器的KR/IKR的“BEGIN<ID>”被达到,ODERMP等于自由指针(FP),这表示要删除的KR/IKR为CTR中的最后一个(0504)。
在这种情况下,FP装上GP的数值,这样由要删除的KR/IKR占据的存储位置被标为空的;功能“REMOVE”结束(0505)。
否则(“BEGIN<ID>”被达到(0506)),由MP指出的数据被复制到由GP指出的存储器位置上。MP和GP被增量。这个过程一直进行到MP到达CTR末端或FP的位置为止(0507)。如果在过程中一个在其中有“BEGIN<ID>”的存储器位置被MP指出,那么在LUT2中的用于相应的ID的登录便被MP改写(0508),由此在查看时正确的存储器位置被输出。
图6指出FILMO的过程图。一个FILMO含有3个指针:
1.Write P:FIUMO-RAM的写指针
2.Write P:FILMO-RAM的读指针
3.Write P:代表FILMO-RAM的“填充状态”和防止过多以及不足的状态指针。
一个一位的寄存器“BeginF”显示实际的读存取是否位于FILMO-RAM的开始(TRUE),即:没有未删除的登录位于读指针和FILMO-RAM的开始之间;或读指针位于FILMO-RAM的中央(FALSE),即有用的登录位于读指针和FILMO-RAM的开始之间。另外,还有两个寄存器存在用于存储ReadP和FullP的状态。在出现第一个未被删除的登录时必须保护两个寄存器,因为在一个后面进行的读存取时在这个登录的位置上必须开始读出。另一方面,ReadP和FullP却必须在实际读过程中继续被修改,来获取下面的读地址以及确定FILMO-RAM的终端。由于FILMO的结构类似于FIFO-结构-作为所谓的圈存储器-所以存储器的开端和末端都不能借助于一个地址0或一个最大地址来被确定。从基本状态中引出两条运行路径:
1.读路径(0601)
FullP和Read P被确保在寄存器。处理回路开始:
BeginF为TRUE。
如果FullP等于0,那么Read P和FullP被从其寄存器中读回(0602)并且状态机返回基本状态。
此外(0603)被测试是否在FILMO中的RaedP指向的登录等于“NOP”,即:涉及一个在FILMO中央的标为删除的登录。如果不是这样(0604),那么就会把登录写入可配置的元素中(CEL)。如不行的话(REJECT,0605),由于CEL是不可改变配置的,那么BeginF被设置为FALSE,FullP减量而RaedP增量。状态机跳到处理回路(0606)的开始处。
如果把登录写入CEL成功(0607),或登录为NOP,那么BeginF被测试:BeginF=TRUE(0608):在它之前没有未删除的登录。FullP被增量,ReadP被保证在分配给的寄存器中来保持FILMO的新的开始。FullP被保证用于保持现实的数据量;ReadP被增量。
BeginF=FALSE(0609):FullP被增量和在FILMO-RAM中的实际登录被用NOP改写;即:登录被删除,ReadP被增量。
在两种情况下状态机都跳到处理回路的开始处。
2.写路径(0610)
通过检验最大数值上的FullP来测试FILMO-RAM是否满。
如果已满(0611),则跳到读路径里来获取空间。
否则,数据字句被写入FILMO-RAM中并且WriteP和FullP增量。
图7显示在主状态机中的过程。基本状态(IDLE)被离开,一旦
1.出现一个位于其上的CT的REMOVE-Kommando(移动一命令)(0701);移动命令被执行,状态机返回IDLE。
2.在CT之间出现一个用于产生触发器的触发信号(0702);触发器被输出。
状态机跳入“STOP”一命令,而后返回IDLE。
3.出现一个用于执行KR/IKR<ID>触发器信号(0703):程序指针(PP)被由LUT2产生的地址装载。如果地址无效,即:在存在用于要装载的KR/IKR的登录,则KR/IKR被装载(0704)和PP重新设置。
执行回路开始:
PP被增量(在首次回路运行时BEGIN<ID>命令便由此被跳过),其它触发器被禁止出现,RECONFIG被锁闭。命令被执行和跳到执行回路的开始(0707)。
命令“STOP”被特别执行(0705)。触发器和RECONFIG被重新释放并且状态机跳到IDLE。
命令“EXECUTE”也被特别执行(0706)。在EXECUTE<ID>中给出的ID被写入ID-REG。PP被重新装载并且由ID给出的KR/IKR被执行(0708)。
在CT复位后基本配置被装入CTR中并直接跳入基本配置的执行中(0709)。
图8显示一个SCRR-ARB的结构。要判断的信号经过DataIn到达一个屏蔽(0801),它根据所知的表连接信号的相关联部分以及锁闭。根据现有技术一个普通的优先处理器(0802)由连接的信号的数量判断一个信号并且把它的二进矢量(Bi-naryOut)同一个有效的/无效的-标识(ValidOut)一起(也根据现有技术)提供为SCRR-ARB的输出。
这个信号根据所知的表被翻译编码(0803)并且传递到用于同步节拍的寄存器上(0804)。经过这个寄存器DataIn屏蔽被打开。此时寄存器或者由一个节拍或者由一个询问下一个有效二进制矢量的下个信号(Euable EN)控制。在复位时或当标识(ValidOut)显示无效时,寄存器被接通,以致DataIn屏蔽连接所有的信号。
屏蔽的构造在0805中被说明,在0806中屏蔽再一次被说明,此时根据SCRR-原则,信号DataIn O..DataIn1为同等优先,而DataIn m…DataIn n较为优先。
在图9中LUT-结构被描绘。判断的触发器的二进制矢量(BinaryIn)被传到LUT1(0901)的地址输入上。LUT1把这个二进制矢量或者翻译到有效的触发器里来把它中继传输到另一个CT上,或者翻译到一个有效的ID里、两个都经过0910被输出。0911显示出是涉及一个触发器还是一个ID。如果经过命令“REFERNCE”没有详细的二进矢量的翻译被登录到LUT1中,那么-借助于一个位登录或一个比较器以一定的方式(例如“VOID”)-产生信号“非法触发器”0914。一个触发顺经过0912被引导到外部CT上,ID经过乘法器(0902)被继续处理。0902或者接通说明一个有效ID的LUT1的数据输出,或者接通CT的ID-寄存器(0903)到LUT2的地址输入上(0904)。0904具有一个高速缓冲-相类似的结构,即:0902的数值输出的低值部分(0906)被接到0904的地址输入上,而较高值的部分(0907)被接通到0904的数据输入上。属于0907的数据输出经过一个比较器(0905)同0907比较。这种方法的优点是0904不必显示用于翻译所有ID的深度,而是可以分析出更小的深度。类似于普通的高速缓冲,只有ID的一个部分被翻译,同时在LUT2里借助于0907可以确定所选择的ID是否符合由LUT1说明的ID。根据现有技术,这符合Cache/TAG-方法。
一个乘法器0908被分配给0904的第二个数据输入,它根据操作把自由指针(FP,操作LOAD),垃圾指针(GP,操作REMOVE)或一个无效-标识/记号(NoAdr,操作REMOVE)送到LUT2上用于存储。这两种指针指向CTR中的存储器位置,“NoAdr”表明不存在适合的ID的登录,登录被删除。这是通过数据在记号“NoAdr”上经过比较器0909被比较来被在数据输出上确定的。下列被继续传导到状态机上:
-通过“ValidIn”出现一个二进制矢量(比较图8)。
-说明在翻译到LUT1里时是涉及到一个触发器还是涉及到一个ID(0911,“Trigger/ID Out”)。触发器被经过0912传送到其它CT上。ID在自有的CT里被处理并继续传送到LUT2上。
-0905的结果,它说明相应的ID是否被存储在0904中(“Hit/Miss Out”)。
-0909的结果,它说明相应的ID是否指向CTR中的一个有效的地址(“NoEntry Out”)。
由0904产生的地址被继续传送到CTR上(“CTR Address Out”)。
LUT1经过命令“REFERENCE”被用详细的二进制矢量的翻译装载到一个触发器或ID上。命令的这算数被经过母线0913传导到LUT1上。ID-寄存器(0909)经过相同的线母被装载。
图10显示垃圾指针(PG)、程序指针(PP)、移动指针(MP)和自由指针(FP)的指针算法。每个指针由一个可分开控制装载的上/下-计数器组成。每个计数器都可以-只要有必要-用其它的计数器的数值来装载;同用LUT2的输出一样(1007)。
通过比较器来确定是否
1.PP等于MP
2.MP等于FP
3.FP等于在CTR中的最大位置
这些结果被用于控制状态机。
指针中的一个经过乘法器(1001)被传导到CTR的地址输入处。数据经过乘法器(1002)或者从置于其上的CT(1005)处或者从一个寄存器里(1003)到达CTR上。经过一个乘法器(1004)或者是上一级的CT的数据或者是CTR的数据被继续传送到状态机和FILMO(1006)处。此时在出现一个REMOVE-命令时命令直接由上级CT经过1004传送到状态机上,而不然的话,命令被从CTR传到状态机上。寄存器1003用于把命令存储和反馈到CTR输入上,这些命令在垃圾箱运行时被从一个地址移动到另一个地址。
一个FILMO的结构被在图11中被说明。数据从CTR(1101)到达FILMO并且或者经过乘法器(1102)被写入FILMO-RAM(1103)或者经过乘法器(1104)被发送到可配置的元素(1116)上。如果数据在1103中被删除,那么一个“NOP”-信号就经过1102被写往1103。“NOP”-信号经过数据输出口的比较器(1105)被识别并且防止写入可配置的元素。经过乘法器1106,不是写指针WriteP(1107)就是读指针(1108)被导往1103的地址输入上。在寄存器1109中,读指针被保证,以便可以复位(参见图6)。
1103的填充状态计数器满(1110)被根据图6存储在寄存器1111中用于复位。两个比较器测试1103是空的(1112)还是满的(1113)。经过乘法器1115来选择是状态机(1101)的控制信号还是FILMO的控制信号被发送到1116上。
图12a指出CT的等级结构。所有的CT从ROOT-CT中(1201)和从属于它的ECT(1204)中取得数据。对于在一个组件中的每个执行层面都存在一个或数个CT。每个CT都负责管理其层面和下层的CT。树的所有树枝都一样深是没有必要的。例如,用于控制一个组件的外围设备(1202)的层面要比用于控制工作元件(1203)的层面少。数据传递如树状进行。每个CT作为用于置于其下的CT的高速缓冲而运行。
图12b显示在CT之间的触发器流。当数据流按树状移动时,触发器流未被固定。每个CT都可以发送一个触发器给其它的CT。一般而言,触发器交换只由页(1203)朝ROOT-CT的方向(1201)进行。而有时传递也可以朝相反的方向移动。
在图12C中一个触发器矢量Broadcast(播送)被说明,同时1205向所有CT发送一个触发器矢量。
图12d显示一个较高级的触发器矢量,它被1206发送到置于其上的CT上。1208把一个直接编址的(ADDRESSED)-触发器矢量传输到一个特定的CT上,此CT并不直接同1207相连。
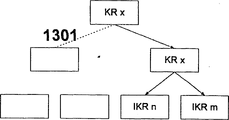
在图13中两个独立的IKRn和m请求一个共同的在置于其上的CT中高速缓冲的KRx。这表明这个KR由整个分支缓冲并且也在一个相邻分支中(1301)可使用一个共同的CT。
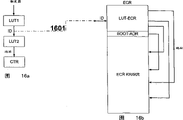
图14表明一个相对于图9修改过的LUT-系统,这个系统在ROOT-CT和CT中借助于等级层面被使用。其同至此所描述的CT的根本区别在于:必须由CT来管理ID-和/或触发器矢量,而不是单个触发器信号。此时一个手摇一信号(RDY)被分配给每个矢量以显示矢量的有效性,这个显示被传到一个处理器(1401)。经过乘法器(1402,1403),不是触发器矢量中的一个(1404)就是ID-矢量之一(1405)被选择。触发器矢量直接到达LUT1的地址输出上(1406),这些矢量否则就按图9被接线,ID-寄存器(1407)也按图9接线。同图9相反,乘法器1408有三个输入口(比较0902)。同时乘法器除了由状态机控制外,另外也由处理器1404控制。ID-矢量经过另外的输入口被直接经过1403中继传输到LUT2上。母线1409即用于此。(原则上,在CT处根据图9ID也可以按照乘法器(1408)直接转换到LUT2上。然后ID可以在未翻译的情况下直接由CEL发送到LUT2)。“Trigger/ID Out”被按图9产生。一个按照图9被中继传输到“Valid Out”上的“Valid In”信号不存在。取而代之的是根据判断由1401产生一个“ValidTrigger Out”用于触发器矢量和一个“Valid ID Out”用于ID-矢量,未规定状态机如何进行处理。母线1409被经过1410引入一个只存在于ROOT-CT里的在图15中说明的另一个单位。
一个ROOT-CT除普通CT-功能外,还需要一个通向外部配置存储器(ECR)的界面,以及必要的地址发生器和用于管理存取到ECR上的单位。
一个普通的CT在LUT1中把详细的触发器矢量翻译到一个ID上并在LUT2里把ID翻译到CTR中的一个存储器位置上(参见图16a)。在存取到ECR上时一个ROOT-CT把一个在ECR内部的ID翻译到ECR里的地址上,在这个地址上由ID指出的KR/IKR开始。为此在ECR中一个其大小相当于ID上可能的数量的存储范围被确定(如果一个ID例如为10-位宽,得210=1024个可能的ID,也就是说在ECR中预留了1024个登录)。在下列举例中这个存储范围位于ECR的下端末尾处并且LUT-ERC被列举出用以强调同LUT2的相似性。此时根据在LUT1中已熟知的CT把一个触发器翻译到一个ID上(1601)。为了更好地理解,图16b说明了到ECR上的存取。
在图15中一个ID经过图14上的1410到达乘法器1501。ID经过1501被写入可装载的计数器1502中。1502的输出口经过乘法器1503导入ECR的地址母线(1504)上。ID的翻译经过数据母线1505到达经过1501上的乘法器/除法器(1506)的一个存储器地址,这个乘法器把存储器地址装到1502上。接着,相应的KR/IKR的数据字句被经过主机LOAD-ECR(参见图17)从ECR中读出并且写入CTR,同时1502根据每次读过程被提高,直到命令“STOP”被读取。
经过界面1507,上级的HOST经过1503/1506把KR/IKR写入ECR。此时经过状态机(CT)被判断是HOST还是ROOT-CT有到ECT上的存取。
在组件复位后,一个基本配置(BOOT-KR)必须被装载。为此引进一个固定的指向BOOT-KR的第一个存储位置的存储地址。作为BOOT-ADR,存储位置Oh被推荐。只要ID在1时开始,否则2ID或任意一个其它的存储位置被使用,在执行例子中2ID被使用。
ROOT-CT进行查寻用以在BOOT-ADR位置上装载BOOT-KR,一旦一个BOOT-KR被装载。ROOT-CT把数据写往1502,用以从那里装载BOOT-KR直到出现一个“STOP”命令。
在ROOT-CT内部的一个监控单位接收HOST同组件的同步。这如下进行:
地址小2ID由1508监控,即:在由HOST存取到这些地址上时一个信号(ACC-ID)被发送到状态机(CT)上。同样地,BOOT-ADR被经过1509监控并且把一个信号ACC-BOOT发送到状态机(CT)上。状态机(CT)如下反应:
-如果HOST写入BOOT-ADR,这就导致BOOT-KR的装载。
-如果HOST把数据字句0(1512)写入BOOT-ADR,那么就被经过比较器1510确定并且导致组件的停止。
-如果HOST写入地址较小的2ID,那么地址被装载到REMOVE-寄存器(1511)上。因为地址符合ID(参见ECR-LUT),所以被修改的KR/IKR的ID在1511中。命令REMOVE<ID>被发送到所有CT上用于立即执行(1513)。接着CT从其CTR以及CUT2中删除相应的ID的KR/IKR。在接着存取KR/IKR时CT必须强制性地从ECR中装载新的KR/IKR。
图17指出在从ECR中装载KR/IKR时在ROOT-CT里的过程。如果一个ID不在内部的CTR中(比较图1,1701),那么ID就被写入计数器1502中(1703)。把1502中的地址存取到ECR上提供了KR/IKR的基本地址。这个地址被写入1502中(1704)。根据图2的LOAD进行了(1702)。此时数据不是从上级CT中而是从ECR中被读取(1705)并且不仅被写入自有的CTR中,而且被发送到下属的CT上(1706)。在较中等的等级层面的CT中触发器的翻译运行类似于图1,触发器矢量和ID-矢量按图14被处理是个例外。KR/IKR被按图2装载,数据字未被写入自有的CTR(0210)而是同时被发送到下级的CT上为例外。
图19说明了FILMO原理。FILMO(1901)在写和读的存取时总是从开始运行到最后(1902)。如果登录被从FLIMO的开始被写入和删除(1903),那么读指针移到第一个未被删除的登录上(1904)。如果登录被从FILMO的中间写入(1905),那么读指针保持不变(1906),登录使用“NOP”作标记(1907)。如果数据被写入FILMO,那么它被挂在最后,在最后的登录后面(1909),读指针(1910)保持不变。
当然,一个CT可以由只有一个存储器、LUT1、LUT2和CTR包围着构成。而为此的控制却较浪费。这时CT的构造同己把LUT2和CTR集合入ECR的ROOT-CT相类似。不必描述这个CT来理解这种方法。
如果一个CT被作为高速缓冲系统用于数据,那么触发器被引进用于把数据写入CTR。此时数据被CEL写入CTR。在此必要的修改是很普通的,FILMO可以完全不要。
在数据缓冲时出现数据密度的问题,它可以通过使用一种根据DE4221278A1的方法来在单个等级层面中标识数据和其有效性来解决。如果数据被要求用于执行一个读-修改-写-循环(RMW-循环),那么这些数据在所有的等级层面上借助于一个附加的登录在CTR/ECR中被标识为“无效”(INVATID)。为此,使用这些数据的KR/IKR的单一ID被登记到登录中。这些数据不可以由带其它ID的KR/IKR使用,直到使用这些数据的KR/IKR写回了这些数据(比较现有技术的写-回-方法)并且删除了它们的ID。
图20指出了一个执行举例:
在图20a中CT2007要求置于其上的CT的数据,这个置于其上的CT要求ROOT-CT2004的数据;随着数据要求,要求的KR/IKR的(2001)ID被传输。数据(2002)被发送到2007上。所有其它的后面的存取都被拒绝(2003)。
在图20b中数据被写回(2005),其它的后来的存取重新被接受(2006)。
在图20c中数据被由含有数据的中等等级的一个CT要求,并且被发送到2007上。用于锁闭数据的ID被发送到在等级中的所有CT上。(2001)在图20d中写回数据(Write-Back)时数据被写到等级中的所有CT上并且删除ID。
图21显示一个INITIATOR CT(2101)经过几个中间-CT(2104,2105,2106)同一个TARGET CT(2102)的通信,以及根据GETCTS/LOOSECTS-方法进行的没有中间层面的同一个TARGET CT(2103)的直接通信。
2101建立了同2103的联系。在成功的建立后,2101和2103处获得一个GRANT作为建立的确认。此后2101经过2104、2105、2106建立起同2102的联系。只有2102被到达时,同2102的联系才被确认(GRANT)。如果不能建立联系,由于母线中的一根被占线,那么一个REJECT被送到2101上并且2101中断该过程。这表明,同2103的连接也被中断而且一个REJECT被发送到2103上。
如果2102用GRANT确认了连接,那么2101把一个GO-命令发送到2103和2102上,用以同时向2103和2102确认成功的母线建立和同步。通过这个记录数据或命令可同步地和不锁扣地传输,因为经过GO确保了所有TARGET正确地接收了命令。
图22显示按照GETBUS/LOOSEBUS-方法的CT间通信的过程。在按照图21的方法中各个上级的CT拥有控制和优先任务时,在此控制就由CT间母线(2201)来承担了。
通过INITIATOR-CT(2101)要求其局部的CT间母线(2202)来建立同2103的连接。当母线是畅通的(ACCEPT)时要求被确认,或者当母线占线时(REJECT),要求被拒绝。然后它把地址从2102发送到母线上。根据定址图表母线系统控制识别出地址位于局部母线地址之外并且经过上级CT2104建立起同其局部母线的连接(2203)。由于2102的地址位于其地址范围内,所以同2102的局部的母线的连接被经过2106建立(2204)。由于2101现在是所有用于数据通信所必要的数据总线的唯一的数据主线,所以就确保了通信顺利地无锁闭地运行,因为用于其它所有CT的通信渠道被锁闭了。2102和2103也不能使用数据总线,因为这些母线在其TARGET-角色中只能接收命令并且只能应INITIATOR(2101)的要求自己发送数据。一旦通信结束,数据总线便由2101的一个信号去除连接。如果在数据总线建立时2101到达一个被使用的母线,那么一个REJECT便被发送到2101上,而2101重新去除数据母线系统的连接并且试图重新在后面的时间里建立。如果多个CT同时要求同一个母线,那么上级的CT更为优先(2205)。由此避免一个已运行经过了多个层面的先进得多的母线结构被一个还很局部的母线结构所中断。
通过一个扩展的记录可以在REJECT时只拆除那些被较为优先的母线结构所需要的母线。这可以大大提高性能,因为不是所有的母线都能在后面的时间里重新建立的。
用于根据图22的方法的CT间母线的结构被在图23中说明了。CT2301-2304被经过其界面(2308-2311)同上级的CT2305一起(界面2307)连接到CT间母线2312上。连通到CT间母线经过一个Ronnd-Robin-处理器发生,它同2308-2311同样优先而比2307更为优先,它控制一个乘法器用于联接母线(2306)。一个处理控制信号(例如:建立/拆除、接受、拒绝……)的状态机被分配给这个处理器。
图24显示一个一维的CT-树的地址示意图的结构。长方形表示一个CT。CT的地址就登录在那里。一标出那些不被处理的不相关的地址位,相关的地址位被用二进制0或1表示,*表示每个任意的地址位。很容易理解,通过这个示意图的投影也可以在多维树上被应用,此时被说明的地址各表示轴中的一个;也就是说:每根轴有一个相应的单独的地址系统。
图24a显示CT0001的定址。此时说明相对于地址1。通过计算-1+1=00(“相对运动”+“在实际界面上的INITIATOR-CT的地址”)可以计算出在同一个局部数据母线上被接通的CT0000、图24b中CT0010调入相对地址+10。10+0=10的计算(“相对移动“+”在实际层面上的INITIATOR-CT的地址”产生传输1,因为最低的局部数据总线的地址范围正好为一位。由此下一个较高的数据总线被选择。它的地址计算随着10+10=100(“相对移动”+“在实际层面上的INITIATOR-CT的地址”)重新产生一个传输,因为它的2位的地址范围正好比最低的数据总线的地址范围大1。在下一个层面上在计算10+010=0100时不出现传输,以致第三位(从左起)选择地址在带下一个较低层面的路径1**上,第2位(从左起)把一下最低的层面的路径10*定为地址并且最终最后一位选择TARGET-CT。
图24c在正方向显示经过2个层面的已知方法,而图24d在带负的超程的负方向上的经过3个层面的方法。
图25显示一个2-维的CT树的结构,在最低的层面上(2502)有2-维设置的CT(2501)。维的地址在各CT中用x/y表示,置于2502上的是下一个较高的层面(2504)。其CT(2503)各控制层面2502的4个CT的一个组,在2504上的CT的地址空间宽了一位,*作为层面2502的同2504上的CT的选择无关的地址位。ROOT-CT2505位于2504之上。2505的地址又大一位,*的作用是相同的。
图26显示在微控制器-执行时的垃圾箱的链接。此时所有的KR一起经过页眉登录(垃圾-前一个/垃圾下一个)被相互链接。在垃圾箱通过列表时,KR的年龄通过把登录提高(+1)被记录用于高速缓冲-统计(2602)。垃圾箱注意KR-统计(2601)的登录,它显示KR是否还挂在FILMO-列表中。在这种情况下KR不允许被从GC处删除,因为它还含有未被配置的KW。作为另一种选择,这个测试也可以经过登录FILMO-下一个和FILMO-前一个。在图27中说明了FILMO-列表的链接。
此时链接可以完全不同于在垃圾-清单中的链接(图26)。KR经过FILMO-前一个和FILMO-下一个被链接。登录KR-统计(2701)指向在各自的KR中的第一个还未被配置的KW。一个FILMO-过程如此形成,以致KR在第一个KD中被启动。在执行以后,未被执行的KW被写往2701。如果KR被完全执行,那么KR被从链接的FILMO-清单中删除,却留在存储器中。此后,经过FILMO-清单跳到也被处理的下一个KR去。
图28说明了在微控制器控制时KR的结构。开始时有一个跳跃命令,它跳到KR的页眉(2801)后面。FILMO-位(2802)被分配给每个KW,一个1(2803)显示KW被CEL接受(ACCEPT)和在下一次通过时不再执行。一个0(2804)表示拒绝,KW必须在下一次通过时重新被执行。选择的KR-统计(2701)指向第一个用0作标记的KW。如果PUSHRET(2805)收到一个拒绝,那么KR的数据处理就在此中断并且在下一次通过时不是在第一个KW时就是在指向2701的位置上重新被装上。否则,KR在其终端在2806处顺序地离开。
图29显示用于防止CEL的状态信息经过FILMO或启动KR的接通。状态信息从CEL(2901)到达一个寄存器处(2902)。在通过FILMO或启动一个KR前CF把一个释放信号(2903)发送到2902上。接着,状态信息被接收并且中断传输到CT上(2904)。2904保持不变直到2903的下一次发送。
概念定义
接收信号这个信号表明有地址的可配置元件处在可配置状态中并且采用发送来的配置代码。
信息组--指令(或指令组--移动)指令将大部分数据(1个信息组)移入存储器中或存储器和外部设备之间。为此需要给出被移动数据的原始地址,数据的目标地址和数据信息组的长度。
中继 把一条信息发放到多接收机中
数据接 收继续处理可配置元件结果的单元
数据发送 数据作为可配置操作数的单元
数据代码 数据代码由任意一个长的二进制组构成。这个二进制组表示机器的加工单元。在数据代码中可以对处理程序和功能模块的指令以及纯数据进行编码。
闭锁 由于相互封闭而不能进行数据处理的状态
DFP 依照专利DE4416881的数据流处理程序
DPGA 动态可配置FPGA。技术状态
元素 所有具有闭锁单元的总称。元素可以作为块进入电子模块。元素指:
-所有类型的可配置元件
-组件
-随机存取存储器程序段
-逻辑电路
-计算器
-寄存器
-乘法器
-电路板的输入/输出线
事件 一个事件可以通过硬件元素在任何一种方式中得到评估。评估的结果是释放限定反应。事件有下列几种类型:
-计算机的循环节拍
-内部或外部中断信号
-功能模块中其它元素的起动信号
-数据流和/或指令流与数值的对比
-输入/输出事件
-指针的流出、溢流和重新设置等
-对比的评估
FIFO技术状态下首次输入、首次输出存储器
FILMO从线性数据中可以读出的变化的FIFO。在存储器始端不存在对读取指针的限制。
FPGA技术状态下的可编程序逻辑块。
在F-PLUREG调节器中设置可配置元件的功能。同样可以设置一次使用和睡眠模式。调节器功能由PLU说明。
碎片 把存储器分到许多小的又没有用处的存储器区域。
无用数据收集器 管理存储器的单元,防止碎片。
H-电平 逻辑1电平,从属于应用技术。
HOST 上级计算机的功能模块或标准组件
无效循环 在这种循环中状态机不能进行数据处理。这是状态机的一种基本状态。
起动-高速缓存器单元-总线 位于平面高速缓存器单元和高层高速缓存器单元(或单元组)之间的总线系统
起动器 在起动-高速缓存器单元-总线上存取数据的高速缓存器单元
指针 指示地址或数据代码的指针
可配置元素(KE)可配置元素表示一个逻辑块单元,这个单元可以通过配置代码调节特殊功能。可配置元素包括随机存取存储器元件、乘法器、逻辑算术单元和寄存器以及内外部交联描述器等元件的所有类型。
可配置元件(CEL)参见逻辑元素
配置功能设置和逻辑单元、(FPGA)元件或CEL之间的交联(试比较循环配置)
配置数据 随机产生的配置代码
配置路径(KR)许多配置代码组合成一条规则系统。
配置存储器 配置存储器包括一条或多余配置代码。
配置代码(KW)配置代码由随机产生的一个长的二进制组构成。这个二进制组对可配置元素进行有效调整,因而产生一个功能单元。
逻辑载入 可配置元件的配置和循环配置单元。通过和装载任务匹配的微控制器调节
逻辑元件 用于DFP、FPGA和DPGA的可配置元件,可以通过配置来完成简单的逻辑或算术任务。
一览表指令 技术状态下转换数据的方法
LUT1 一览表指令将同步信号转换成识别码并确定同步信号是否和有效的识别码相匹配。
LUT2 一览表指令将识别码转换成局部存储器相应的配置路径地址并确定局部存储器是否存在配置路径。
L-电平 逻辑0电平,依赖于应用技术
屏蔽 对大部分有效信号进行说明的二进制位组合
优先权 确定顺序
重新配置 可配置元件的重新配置状态
重新配置--同步信号 将可配置元件设置成重新配置状况。
拒绝 这个信号表明可配置元件不在可配置状态中并且不采用接收的配置代码
消除-<识别码>1.用配置路径内的指令去除以识别码为基准的配置路径。
2.用分离界面上的上置交流器指令或下置交流器的符号交换来消除以识别的为基础的配置路径。
重设 在定义的基本状态下重新设置功能模块或整个计算机系统
根部-高速缓存器单元具有在外部配置存储器上直接存取功能的最高级高速缓存器单元
循环-Robin-工人 工人循环工作并且最终信号总是和最低优先权相匹配
状态机 参见状态机(zustandsmachine)
同步信号 从可配置元素或计算器中产机的状态信号,这个信号对其它可配置元素或计算器的数据处理产生同步性。同步信号可能在导回可配置元素或计算器时滞后(存储)。
目标 高速缓存器是起动-高速缓存器-总线上的一个存取对象
Trigger同步信号的同义词
重新配置 在任意剩余的可配置元件继续保持自身功能时对任意一组少配置元件进行重新配置(比较“配置”)。
联接清单 技术状态下描针上结合的数据结构
元件 可配置元素的同义词
状态机 采用不同状态的逻辑过程。状态之间的过渡依赖于不同的输入参数。机器控制复杂的功能并且符合技术状态。
Claims (12)
1.一种高速缓冲存储器存储指令的方法,这些指令是存在于由许多计算器组成的微处理机和具有二维或多维单元结构(比如FPGA、DPGA、DFP等)的功能模块之中的,其特征在于,
1.1许多元件和可配置元件(CEL)结合成一组,而每个分组都和一个高速缓冲存储器单元(CT)相匹配,
1.2每个分组的高速缓存器单元通过一个树形结构转换成上置的高速缓存器单元(ROOT-CT),这个单元占据了指令存储器(ECR)的存取指令并中断指令,
1.3指令汇总指令序列(KR),可以整体存储并在存储器之间传输,
1.4位于树形结构底层或中间层的每一个高速缓存器单元要求用于上置高速缓冲器单元的必要指令,
1.5只要指令序列在本地存储器中,上置高速缓存器单元就会将要求的指令序列发送到下置单元中,
1.6只要指令序列不在本地存储器中,上置高速缓存器就要求有必要的指令序列。
2.如权利要求1所述的方法,其特征在于,指令序列会完全消除代码。
3.如权利要求1至2所述的方法,其特征在于,如果本地存储器中要求的指令序列没有足够的载入空间,那么高速缓存器单元的指令序列就会清除代码。
4.如权利要求1至2所述的方法,其特征在于,指令序列中的一条指令(移动)可以通过高速缓存器单元中的指令序列来中断一条程序。
5.如权利要求1至4所述的方法,其特征在于,指令序列中的一条指令(执行)可以中继一条确定的指令序列的载入。
6.如权利要求1至5所述的方法,其特征在于,高速缓存器单元之间总线上的任意一条指令(执行、移动等)可以中断任意地址上的高速缓存器单元中和指令相匹配的作用。
7.如权利要求1至6所述的方法,其特征在于,一个程序序列设有有效的缓存作用,是因为这个序列只能用于一个高速缓存器单元中并且只能在小的分序列中分解,而许多高速缓存器单元需要分序列,一个附加的分序列(IKR)包括指令序列中没有缓存作用的部分和分序列中有缓存作用的部分。
7.如权利要求1至6所述的方法,其特征在于,每一条指令序列都符合统计学,它给出了时效信息,也就是说高速缓存器单元和指令序列中缓存器的停留时间。
8.如权利要求1至6所述的方法,其特征在于,每一条指令序列都符合统计学,它给出了有关指令序列的调入情况。
9.如权利要求1至6所述的方法,其特征在于,每一条指令序列都符合统计学,它给出了指令序列的长度。
10.如权利要求1至9所述的方法,其特征在于,清除代码路径可以设计参数,它可以评估每个指令序列的统计性并去除和规则系统相匹配的不重要的指令序列。
11.如权利要求1至10所述的方法,其特征在于,清除代码路径和可编程规则系统相匹配。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| DE19807872.2 | 1998-02-25 | ||
| DE19807872A DE19807872A1 (de) | 1998-02-25 | 1998-02-25 | Verfahren zur Verwaltung von Konfigurationsdaten in Datenflußprozessoren sowie Bausteinen mit zwei- oder mehrdimensionalen programmierbaren Zellstruktur (FPGAs, DPGAs, o. dgl. |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| CN1298520A true CN1298520A (zh) | 2001-06-06 |
Family
ID=7858839
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN99805452A Pending CN1298520A (zh) | 1998-02-25 | 1999-02-25 | 按照层结构具有二维或多维可编程序的单元结构(FPGAs、DPGAs等)的数据流处理器和模块的高速缓存配置数据方法 |
| CN99805453A Pending CN1298521A (zh) | 1998-02-25 | 1999-02-25 | 具有二维或多维可编程序的单元结构(fpgas、dpgas等)的数据流处理器和模块的无死锁配置方法 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN99805453A Pending CN1298521A (zh) | 1998-02-25 | 1999-02-25 | 具有二维或多维可编程序的单元结构(fpgas、dpgas等)的数据流处理器和模块的无死锁配置方法 |
Country Status (10)
| Country | Link |
|---|---|
| US (3) | US6571381B1 (zh) |
| EP (4) | EP1057117B1 (zh) |
| JP (2) | JP4338308B2 (zh) |
| CN (2) | CN1298520A (zh) |
| AT (2) | ATE217715T1 (zh) |
| AU (2) | AU3326299A (zh) |
| CA (2) | CA2321877A1 (zh) |
| DE (5) | DE19807872A1 (zh) |
| EA (2) | EA003407B1 (zh) |
| WO (2) | WO1999044120A2 (zh) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100397331C (zh) * | 2001-09-07 | 2008-06-25 | Ip菲力股份有限公司 | 数据处理系统以及控制方法 |
| CN101539889B (zh) * | 2004-03-30 | 2011-11-09 | 英特尔公司 | 提高存储性能 |
Families Citing this family (104)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2002071196A2 (de) | 2001-03-05 | 2002-09-12 | Pact Informationstechnologie Gmbh | Verfahren und vorrichtung zu datenbe- und/oder verarbeitung |
| US7266725B2 (en) * | 2001-09-03 | 2007-09-04 | Pact Xpp Technologies Ag | Method for debugging reconfigurable architectures |
| US7664263B2 (en) | 1998-03-24 | 2010-02-16 | Moskowitz Scott A | Method for combining transfer functions with predetermined key creation |
| US6205249B1 (en) | 1998-04-02 | 2001-03-20 | Scott A. Moskowitz | Multiple transform utilization and applications for secure digital watermarking |
| US7177429B2 (en) | 2000-12-07 | 2007-02-13 | Blue Spike, Inc. | System and methods for permitting open access to data objects and for securing data within the data objects |
| US7159116B2 (en) | 1999-12-07 | 2007-01-02 | Blue Spike, Inc. | Systems, methods and devices for trusted transactions |
| US7346472B1 (en) | 2000-09-07 | 2008-03-18 | Blue Spike, Inc. | Method and device for monitoring and analyzing signals |
| US7457962B2 (en) | 1996-07-02 | 2008-11-25 | Wistaria Trading, Inc | Optimization methods for the insertion, protection, and detection of digital watermarks in digitized data |
| US7095874B2 (en) | 1996-07-02 | 2006-08-22 | Wistaria Trading, Inc. | Optimization methods for the insertion, protection, and detection of digital watermarks in digitized data |
| DE19651075A1 (de) * | 1996-12-09 | 1998-06-10 | Pact Inf Tech Gmbh | Einheit zur Verarbeitung von numerischen und logischen Operationen, zum Einsatz in Prozessoren (CPU's), Mehrrechnersystemen, Datenflußprozessoren (DFP's), digitalen Signal Prozessoren (DSP's) oder dergleichen |
| DE19654595A1 (de) | 1996-12-20 | 1998-07-02 | Pact Inf Tech Gmbh | I0- und Speicherbussystem für DFPs sowie Bausteinen mit zwei- oder mehrdimensionaler programmierbaren Zellstrukturen |
| EP1329816B1 (de) | 1996-12-27 | 2011-06-22 | Richter, Thomas | Verfahren zum selbständigen dynamischen Umladen von Datenflussprozessoren (DFPs) sowie Bausteinen mit zwei- oder mehrdimensionalen programmierbaren Zellstrukturen (FPGAs, DPGAs, o.dgl.) |
| DE19654846A1 (de) * | 1996-12-27 | 1998-07-09 | Pact Inf Tech Gmbh | Verfahren zum selbständigen dynamischen Umladen von Datenflußprozessoren (DFPs) sowie Bausteinen mit zwei- oder mehrdimensionalen programmierbaren Zellstrukturen (FPGAs, DPGAs, o. dgl.) |
| US6542998B1 (en) | 1997-02-08 | 2003-04-01 | Pact Gmbh | Method of self-synchronization of configurable elements of a programmable module |
| DE19704728A1 (de) * | 1997-02-08 | 1998-08-13 | Pact Inf Tech Gmbh | Verfahren zur Selbstsynchronisation von konfigurierbaren Elementen eines programmierbaren Bausteines |
| DE19704742A1 (de) * | 1997-02-11 | 1998-09-24 | Pact Inf Tech Gmbh | Internes Bussystem für DFPs, sowie Bausteinen mit zwei- oder mehrdimensionalen programmierbaren Zellstrukturen, zur Bewältigung großer Datenmengen mit hohem Vernetzungsaufwand |
| US8686549B2 (en) | 2001-09-03 | 2014-04-01 | Martin Vorbach | Reconfigurable elements |
| DE19861088A1 (de) | 1997-12-22 | 2000-02-10 | Pact Inf Tech Gmbh | Verfahren zur Reparatur von integrierten Schaltkreisen |
| US7664264B2 (en) | 1999-03-24 | 2010-02-16 | Blue Spike, Inc. | Utilizing data reduction in steganographic and cryptographic systems |
| WO2000077652A2 (de) | 1999-06-10 | 2000-12-21 | Pact Informationstechnologie Gmbh | Sequenz-partitionierung auf zellstrukturen |
| US7475246B1 (en) | 1999-08-04 | 2009-01-06 | Blue Spike, Inc. | Secure personal content server |
| DE19946752A1 (de) * | 1999-09-29 | 2001-04-12 | Infineon Technologies Ag | Rekonfigurierbares Gate-Array |
| EP2226732A3 (de) | 2000-06-13 | 2016-04-06 | PACT XPP Technologies AG | Cachehierarchie für einen Multicore-Prozessor |
| US7127615B2 (en) | 2000-09-20 | 2006-10-24 | Blue Spike, Inc. | Security based on subliminal and supraliminal channels for data objects |
| US7502920B2 (en) * | 2000-10-03 | 2009-03-10 | Intel Corporation | Hierarchical storage architecture for reconfigurable logic configurations |
| US20040015899A1 (en) * | 2000-10-06 | 2004-01-22 | Frank May | Method for processing data |
| US8058899B2 (en) | 2000-10-06 | 2011-11-15 | Martin Vorbach | Logic cell array and bus system |
| GB2368669B (en) * | 2000-10-31 | 2005-06-22 | Advanced Risc Mach Ltd | Integrated circuit configuration |
| US7444531B2 (en) | 2001-03-05 | 2008-10-28 | Pact Xpp Technologies Ag | Methods and devices for treating and processing data |
| US20090210653A1 (en) * | 2001-03-05 | 2009-08-20 | Pact Xpp Technologies Ag | Method and device for treating and processing data |
| US20090300262A1 (en) * | 2001-03-05 | 2009-12-03 | Martin Vorbach | Methods and devices for treating and/or processing data |
| WO2005045692A2 (en) | 2003-08-28 | 2005-05-19 | Pact Xpp Technologies Ag | Data processing device and method |
| US7210129B2 (en) * | 2001-08-16 | 2007-04-24 | Pact Xpp Technologies Ag | Method for translating programs for reconfigurable architectures |
| US9037807B2 (en) * | 2001-03-05 | 2015-05-19 | Pact Xpp Technologies Ag | Processor arrangement on a chip including data processing, memory, and interface elements |
| US7844796B2 (en) | 2001-03-05 | 2010-11-30 | Martin Vorbach | Data processing device and method |
| US7624204B2 (en) * | 2001-03-22 | 2009-11-24 | Nvidia Corporation | Input/output controller node in an adaptable computing environment |
| US7657877B2 (en) | 2001-06-20 | 2010-02-02 | Pact Xpp Technologies Ag | Method for processing data |
| US7996827B2 (en) | 2001-08-16 | 2011-08-09 | Martin Vorbach | Method for the translation of programs for reconfigurable architectures |
| US7434191B2 (en) | 2001-09-03 | 2008-10-07 | Pact Xpp Technologies Ag | Router |
| AU2002338729A1 (en) * | 2001-09-19 | 2003-04-01 | Pact Xpp Technologies Ag | Router |
| US8686475B2 (en) | 2001-09-19 | 2014-04-01 | Pact Xpp Technologies Ag | Reconfigurable elements |
| DE10147772C1 (de) * | 2001-09-27 | 2003-09-11 | Siemens Ag | Verfahren zum Betreiben eines Übertragungssystems und Übertragungssystem in einem Energieversorgungsnetz |
| US7594229B2 (en) * | 2001-10-09 | 2009-09-22 | Nvidia Corp. | Predictive resource allocation in computing systems |
| US7644279B2 (en) * | 2001-12-05 | 2010-01-05 | Nvidia Corporation | Consumer product distribution in the embedded system market |
| US7577822B2 (en) * | 2001-12-14 | 2009-08-18 | Pact Xpp Technologies Ag | Parallel task operation in processor and reconfigurable coprocessor configured based on information in link list including termination information for synchronization |
| AU2003214046A1 (en) * | 2002-01-18 | 2003-09-09 | Pact Xpp Technologies Ag | Method and device for partitioning large computer programs |
| AU2003208266A1 (en) | 2002-01-19 | 2003-07-30 | Pact Xpp Technologies Ag | Reconfigurable processor |
| AU2003214003A1 (en) | 2002-02-18 | 2003-09-09 | Pact Xpp Technologies Ag | Bus systems and method for reconfiguration |
| WO2003081454A2 (de) * | 2002-03-21 | 2003-10-02 | Pact Xpp Technologies Ag | Verfahren und vorrichtung zur datenverarbeitung |
| US8914590B2 (en) | 2002-08-07 | 2014-12-16 | Pact Xpp Technologies Ag | Data processing method and device |
| WO2004088502A2 (de) * | 2003-04-04 | 2004-10-14 | Pact Xpp Technologies Ag | Verfahren und vorrichtung für die datenverarbeitung |
| JP4501914B2 (ja) * | 2002-04-03 | 2010-07-14 | ソニー株式会社 | 集積回路、および集積回路装置 |
| US7287275B2 (en) | 2002-04-17 | 2007-10-23 | Moskowitz Scott A | Methods, systems and devices for packet watermarking and efficient provisioning of bandwidth |
| US7093255B1 (en) * | 2002-05-31 | 2006-08-15 | Quicksilver Technology, Inc. | Method for estimating cost when placing operations within a modulo scheduler when scheduling for processors with a large number of function units or reconfigurable data paths |
| US7620678B1 (en) | 2002-06-12 | 2009-11-17 | Nvidia Corporation | Method and system for reducing the time-to-market concerns for embedded system design |
| US7802108B1 (en) | 2002-07-18 | 2010-09-21 | Nvidia Corporation | Secure storage of program code for an embedded system |
| US20110238948A1 (en) * | 2002-08-07 | 2011-09-29 | Martin Vorbach | Method and device for coupling a data processing unit and a data processing array |
| US7657861B2 (en) | 2002-08-07 | 2010-02-02 | Pact Xpp Technologies Ag | Method and device for processing data |
| WO2004021176A2 (de) | 2002-08-07 | 2004-03-11 | Pact Xpp Technologies Ag | Verfahren und vorrichtung zur datenverarbeitung |
| US7249352B2 (en) * | 2002-08-22 | 2007-07-24 | International Business Machines Corporation | Apparatus and method for removing elements from a linked list |
| US7394284B2 (en) * | 2002-09-06 | 2008-07-01 | Pact Xpp Technologies Ag | Reconfigurable sequencer structure |
| US7502915B2 (en) * | 2002-09-30 | 2009-03-10 | Nvidia Corporation | System and method using embedded microprocessor as a node in an adaptable computing machine |
| US8949576B2 (en) * | 2002-11-01 | 2015-02-03 | Nvidia Corporation | Arithmetic node including general digital signal processing functions for an adaptive computing machine |
| US7617100B1 (en) | 2003-01-10 | 2009-11-10 | Nvidia Corporation | Method and system for providing an excitation-pattern based audio coding scheme |
| US9330060B1 (en) * | 2003-04-15 | 2016-05-03 | Nvidia Corporation | Method and device for encoding and decoding video image data |
| US7450600B2 (en) * | 2003-04-21 | 2008-11-11 | Microsoft Corporation | Method and apparatus for managing a data carousel |
| US7565677B1 (en) | 2003-04-21 | 2009-07-21 | Microsoft Corporation | Method and apparatus for managing a data carousel |
| US8660182B2 (en) * | 2003-06-09 | 2014-02-25 | Nvidia Corporation | MPEG motion estimation based on dual start points |
| US7603542B2 (en) * | 2003-06-25 | 2009-10-13 | Nec Corporation | Reconfigurable electric computer, semiconductor integrated circuit and control method, program generation method, and program for creating a logic circuit from an application program |
| US8296764B2 (en) * | 2003-08-14 | 2012-10-23 | Nvidia Corporation | Internal synchronization control for adaptive integrated circuitry |
| US8018463B2 (en) | 2004-05-10 | 2011-09-13 | Nvidia Corporation | Processor for video data |
| US8130825B2 (en) * | 2004-05-10 | 2012-03-06 | Nvidia Corporation | Processor for video data encoding/decoding |
| US7278122B2 (en) * | 2004-06-24 | 2007-10-02 | Ftl Systems, Inc. | Hardware/software design tool and language specification mechanism enabling efficient technology retargeting and optimization |
| TWI256013B (en) * | 2004-10-12 | 2006-06-01 | Uli Electronics Inc | Sound-effect processing circuit |
| EP1849095B1 (en) * | 2005-02-07 | 2013-01-02 | Richter, Thomas | Low latency massive parallel data processing device |
| CN100476795C (zh) * | 2005-02-21 | 2009-04-08 | 徐建 | 事件处理机 |
| WO2006128396A1 (de) * | 2005-06-01 | 2006-12-07 | Siemens Aktiengesellschaft | Mess- oder schutzgerät mit unabhängigen software modulen |
| US7281942B2 (en) * | 2005-11-18 | 2007-10-16 | Ideal Industries, Inc. | Releasable wire connector |
| US8731071B1 (en) | 2005-12-15 | 2014-05-20 | Nvidia Corporation | System for performing finite input response (FIR) filtering in motion estimation |
| WO2007082730A1 (de) | 2006-01-18 | 2007-07-26 | Pact Xpp Technologies Ag | Hardwaredefinitionsverfahren |
| US8724702B1 (en) | 2006-03-29 | 2014-05-13 | Nvidia Corporation | Methods and systems for motion estimation used in video coding |
| US7827451B2 (en) * | 2006-05-24 | 2010-11-02 | International Business Machines Corporation | Method, system and program product for establishing decimal floating point operands for facilitating testing of decimal floating point instructions |
| US8660380B2 (en) * | 2006-08-25 | 2014-02-25 | Nvidia Corporation | Method and system for performing two-dimensional transform on data value array with reduced power consumption |
| JP5045036B2 (ja) * | 2006-09-05 | 2012-10-10 | 富士ゼロックス株式会社 | データ処理装置 |
| US7999820B1 (en) | 2006-10-23 | 2011-08-16 | Nvidia Corporation | Methods and systems for reusing memory addresses in a graphics system |
| US20080111923A1 (en) * | 2006-11-09 | 2008-05-15 | Scheuermann W James | Processor for video data |
| WO2008061161A2 (en) * | 2006-11-14 | 2008-05-22 | Star Bridge Systems, Inc. | Execution of legacy code on hybrid computing platform |
| US8169789B1 (en) | 2007-04-10 | 2012-05-01 | Nvidia Corporation | Graphics processing unit stiffening frame |
| US7987065B1 (en) | 2007-04-17 | 2011-07-26 | Nvidia Corporation | Automatic quality testing of multimedia rendering by software drivers |
| US8572598B1 (en) | 2007-04-18 | 2013-10-29 | Nvidia Corporation | Method and system for upgrading software in a computing device |
| US8756482B2 (en) * | 2007-05-25 | 2014-06-17 | Nvidia Corporation | Efficient encoding/decoding of a sequence of data frames |
| US20080291209A1 (en) * | 2007-05-25 | 2008-11-27 | Nvidia Corporation | Encoding Multi-media Signals |
| US8726283B1 (en) | 2007-06-04 | 2014-05-13 | Nvidia Corporation | Deadlock avoidance skid buffer |
| US7948500B2 (en) * | 2007-06-07 | 2011-05-24 | Nvidia Corporation | Extrapolation of nonresident mipmap data using resident mipmap data |
| US7944453B1 (en) | 2007-06-07 | 2011-05-17 | Nvidia Corporation | Extrapolation texture filtering for nonresident mipmaps |
| US9118927B2 (en) * | 2007-06-13 | 2015-08-25 | Nvidia Corporation | Sub-pixel interpolation and its application in motion compensated encoding of a video signal |
| US8873625B2 (en) | 2007-07-18 | 2014-10-28 | Nvidia Corporation | Enhanced compression in representing non-frame-edge blocks of image frames |
| JP5294304B2 (ja) * | 2008-06-18 | 2013-09-18 | 日本電気株式会社 | 再構成可能電子回路装置 |
| US8598990B2 (en) * | 2008-06-30 | 2013-12-03 | Symbol Technologies, Inc. | Delimited read command for efficient data access from radio frequency identification (RFID) tags |
| US8666181B2 (en) * | 2008-12-10 | 2014-03-04 | Nvidia Corporation | Adaptive multiple engine image motion detection system and method |
| US9086973B2 (en) | 2009-06-09 | 2015-07-21 | Hyperion Core, Inc. | System and method for a cache in a multi-core processor |
| JP2016178229A (ja) | 2015-03-20 | 2016-10-06 | 株式会社東芝 | 再構成可能な回路 |
| JP6672190B2 (ja) * | 2017-01-16 | 2020-03-25 | 株式会社東芝 | データベースシステムおよびデータ処理方法 |
| US11803507B2 (en) | 2018-10-29 | 2023-10-31 | Secturion Systems, Inc. | Data stream protocol field decoding by a systolic array |
Family Cites Families (152)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS5936857A (ja) | 1982-08-25 | 1984-02-29 | Nec Corp | プロセツサユニツト |
| US4739474A (en) | 1983-03-10 | 1988-04-19 | Martin Marietta Corporation | Geometric-arithmetic parallel processor |
| US5123109A (en) | 1983-05-31 | 1992-06-16 | Thinking Machines Corporation | Parallel processor including a processor array with plural data transfer arrangements including (1) a global router and (2) a proximate-neighbor transfer system |
| US4870302A (en) | 1984-03-12 | 1989-09-26 | Xilinx, Inc. | Configurable electrical circuit having configurable logic elements and configurable interconnects |
| USRE34363E (en) | 1984-03-12 | 1993-08-31 | Xilinx, Inc. | Configurable electrical circuit having configurable logic elements and configurable interconnects |
| US4761755A (en) | 1984-07-11 | 1988-08-02 | Prime Computer, Inc. | Data processing system and method having an improved arithmetic unit |
| US5023775A (en) | 1985-02-14 | 1991-06-11 | Intel Corporation | Software programmable logic array utilizing "and" and "or" gates |
| US5247689A (en) | 1985-02-25 | 1993-09-21 | Ewert Alfred P | Parallel digital processor including lateral transfer buses with interrupt switches to form bus interconnection segments |
| US4706216A (en) | 1985-02-27 | 1987-11-10 | Xilinx, Inc. | Configurable logic element |
| US5015884A (en) | 1985-03-29 | 1991-05-14 | Advanced Micro Devices, Inc. | Multiple array high performance programmable logic device family |
| US5225719A (en) | 1985-03-29 | 1993-07-06 | Advanced Micro Devices, Inc. | Family of multiple segmented programmable logic blocks interconnected by a high speed centralized switch matrix |
| US4967340A (en) | 1985-06-12 | 1990-10-30 | E-Systems, Inc. | Adaptive processing system having an array of individually configurable processing components |
| DE3687400T2 (de) | 1985-11-04 | 1993-07-15 | Ibm | Digitale nachrichtenuebertragungsnetzwerke und aufbau von uebertragungswegen in diesen netzwerken. |
| US4852048A (en) | 1985-12-12 | 1989-07-25 | Itt Corporation | Single instruction multiple data (SIMD) cellular array processing apparatus employing a common bus where a first number of bits manifest a first bus portion and a second number of bits manifest a second bus portion |
| US5021947A (en) | 1986-03-31 | 1991-06-04 | Hughes Aircraft Company | Data-flow multiprocessor architecture with three dimensional multistage interconnection network for efficient signal and data processing |
| US4860201A (en) | 1986-09-02 | 1989-08-22 | The Trustees Of Columbia University In The City Of New York | Binary tree parallel processor |
| US5367208A (en) | 1986-09-19 | 1994-11-22 | Actel Corporation | Reconfigurable programmable interconnect architecture |
| US4811214A (en) | 1986-11-14 | 1989-03-07 | Princeton University | Multinode reconfigurable pipeline computer |
| US5226122A (en) | 1987-08-21 | 1993-07-06 | Compaq Computer Corp. | Programmable logic system for filtering commands to a microprocessor |
| US5115510A (en) | 1987-10-20 | 1992-05-19 | Sharp Kabushiki Kaisha | Multistage data flow processor with instruction packet, fetch, storage transmission and address generation controlled by destination information |
| US4918690A (en) | 1987-11-10 | 1990-04-17 | Echelon Systems Corp. | Network and intelligent cell for providing sensing, bidirectional communications and control |
| US5113498A (en) | 1987-11-10 | 1992-05-12 | Echelon Corporation | Input/output section for an intelligent cell which provides sensing, bidirectional communications and control |
| US5303172A (en) | 1988-02-16 | 1994-04-12 | Array Microsystems | Pipelined combination and vector signal processor |
| US5204935A (en) | 1988-08-19 | 1993-04-20 | Fuji Xerox Co., Ltd. | Programmable fuzzy logic circuits |
| US4901268A (en) | 1988-08-19 | 1990-02-13 | General Electric Company | Multiple function data processor |
| US5353432A (en) * | 1988-09-09 | 1994-10-04 | Compaq Computer Corporation | Interactive method for configuration of computer system and circuit boards with user specification of system resources and computer resolution of resource conflicts |
| ES2047629T3 (es) | 1988-09-22 | 1994-03-01 | Siemens Ag | Disposicion de circuito para instalaciones de conmutacion de telecomunicaciones, especialmente instalaciones de conmutacion telefonica de multiplexacion temporal-pcm con campo de acoplamiento central y campos de acoplamiento parcial conectados. |
| EP0390907B1 (en) | 1988-10-07 | 1996-07-03 | Martin Marietta Corporation | Parallel data processor |
| US5014193A (en) | 1988-10-14 | 1991-05-07 | Compaq Computer Corporation | Dynamically configurable portable computer system |
| US5136717A (en) | 1988-11-23 | 1992-08-04 | Flavors Technology Inc. | Realtime systolic, multiple-instruction, single-data parallel computer system |
| US5081375A (en) | 1989-01-19 | 1992-01-14 | National Semiconductor Corp. | Method for operating a multiple page programmable logic device |
| GB8906145D0 (en) | 1989-03-17 | 1989-05-04 | Algotronix Ltd | Configurable cellular array |
| US5203005A (en) | 1989-05-02 | 1993-04-13 | Horst Robert W | Cell structure for linear array wafer scale integration architecture with capability to open boundary i/o bus without neighbor acknowledgement |
| US5109503A (en) | 1989-05-22 | 1992-04-28 | Ge Fanuc Automation North America, Inc. | Apparatus with reconfigurable counter includes memory for storing plurality of counter configuration files which respectively define plurality of predetermined counters |
| US5212652A (en) | 1989-08-15 | 1993-05-18 | Advanced Micro Devices, Inc. | Programmable gate array with improved interconnect structure |
| US5489857A (en) | 1992-08-03 | 1996-02-06 | Advanced Micro Devices, Inc. | Flexible synchronous/asynchronous cell structure for a high density programmable logic device |
| US5233539A (en) | 1989-08-15 | 1993-08-03 | Advanced Micro Devices, Inc. | Programmable gate array with improved interconnect structure, input/output structure and configurable logic block |
| US5128559A (en) | 1989-09-29 | 1992-07-07 | Sgs-Thomson Microelectronics, Inc. | Logic block for programmable logic devices |
| JP2968289B2 (ja) | 1989-11-08 | 1999-10-25 | 株式会社リコー | 中央演算処理装置 |
| GB8925721D0 (en) | 1989-11-14 | 1990-01-04 | Amt Holdings | Processor array system |
| US5522083A (en) | 1989-11-17 | 1996-05-28 | Texas Instruments Incorporated | Reconfigurable multi-processor operating in SIMD mode with one processor fetching instructions for use by remaining processors |
| US5125801A (en) | 1990-02-02 | 1992-06-30 | Isco, Inc. | Pumping system |
| US5142469A (en) | 1990-03-29 | 1992-08-25 | Ge Fanuc Automation North America, Inc. | Method for converting a programmable logic controller hardware configuration and corresponding control program for use on a first programmable logic controller to use on a second programmable logic controller |
| US5198705A (en) | 1990-05-11 | 1993-03-30 | Actel Corporation | Logic module with configurable combinational and sequential blocks |
| US5483620A (en) | 1990-05-22 | 1996-01-09 | International Business Machines Corp. | Learning machine synapse processor system apparatus |
| US5111079A (en) | 1990-06-29 | 1992-05-05 | Sgs-Thomson Microelectronics, Inc. | Power reduction circuit for programmable logic device |
| SE9002558D0 (sv) | 1990-08-02 | 1990-08-02 | Carlstedt Elektronik Ab | Processor |
| US5752067A (en) | 1990-11-13 | 1998-05-12 | International Business Machines Corporation | Fully scalable parallel processing system having asynchronous SIMD processing |
| US5734921A (en) | 1990-11-13 | 1998-03-31 | International Business Machines Corporation | Advanced parallel array processor computer package |
| US5588152A (en) | 1990-11-13 | 1996-12-24 | International Business Machines Corporation | Advanced parallel processor including advanced support hardware |
| US5590345A (en) | 1990-11-13 | 1996-12-31 | International Business Machines Corporation | Advanced parallel array processor(APAP) |
| US5765011A (en) | 1990-11-13 | 1998-06-09 | International Business Machines Corporation | Parallel processing system having a synchronous SIMD processing with processing elements emulating SIMD operation using individual instruction streams |
| CA2051222C (en) * | 1990-11-30 | 1998-05-05 | Pradeep S. Sindhu | Consistent packet switched memory bus for shared memory multiprocessors |
| US5301344A (en) | 1991-01-29 | 1994-04-05 | Analogic Corporation | Multibus sequential processor to perform in parallel a plurality of reconfigurable logic operations on a plurality of data sets |
| DE59109046D1 (de) | 1991-02-22 | 1998-10-08 | Siemens Ag | Programmierverfahren für einen Logikbaustein |
| JPH04290155A (ja) | 1991-03-19 | 1992-10-14 | Fujitsu Ltd | 並列データ処理方式 |
| JPH04293151A (ja) | 1991-03-20 | 1992-10-16 | Fujitsu Ltd | 並列データ処理方式 |
| US5617547A (en) | 1991-03-29 | 1997-04-01 | International Business Machines Corporation | Switch network extension of bus architecture |
| JPH04328657A (ja) * | 1991-04-30 | 1992-11-17 | Toshiba Corp | キャッシュメモリ |
| US5389431A (en) | 1991-05-14 | 1995-02-14 | Idemitsu Kosan Co., Ltd. | Nonwoven fabric and process for producing same |
| US5446904A (en) * | 1991-05-17 | 1995-08-29 | Zenith Data Systems Corporation | Suspend/resume capability for a protected mode microprocessor |
| WO1992022029A1 (en) | 1991-05-24 | 1992-12-10 | British Technology Group Usa, Inc. | Optimizing compiler for computers |
| US5659797A (en) | 1991-06-24 | 1997-08-19 | U.S. Philips Corporation | Sparc RISC based computer system including a single chip processor with memory management and DMA units coupled to a DRAM interface |
| US5317209A (en) | 1991-08-29 | 1994-05-31 | National Semiconductor Corporation | Dynamic three-state bussing capability in a configurable logic array |
| US5260610A (en) | 1991-09-03 | 1993-11-09 | Altera Corporation | Programmable logic element interconnections for programmable logic array integrated circuits |
| WO1993011503A1 (en) | 1991-12-06 | 1993-06-10 | Norman Richard S | Massively-parallel direct output processor array |
| US5208491A (en) | 1992-01-07 | 1993-05-04 | Washington Research Foundation | Field programmable gate array |
| JP2791243B2 (ja) | 1992-03-13 | 1998-08-27 | 株式会社東芝 | 階層間同期化システムおよびこれを用いた大規模集積回路 |
| US5452401A (en) | 1992-03-31 | 1995-09-19 | Seiko Epson Corporation | Selective power-down for high performance CPU/system |
| US5611049A (en) * | 1992-06-03 | 1997-03-11 | Pitts; William M. | System for accessing distributed data cache channel at each network node to pass requests and data |
| WO1993024895A2 (en) | 1992-06-04 | 1993-12-09 | Xilinx, Inc. | Timing driven method for laying out a user's circuit onto a programmable integrated circuit device |
| DE4221278C2 (de) | 1992-06-29 | 1996-02-29 | Martin Vorbach | Busgekoppeltes Mehrrechnersystem |
| US5475803A (en) | 1992-07-10 | 1995-12-12 | Lsi Logic Corporation | Method for 2-D affine transformation of images |
| US5590348A (en) | 1992-07-28 | 1996-12-31 | International Business Machines Corporation | Status predictor for combined shifter-rotate/merge unit |
| US5684980A (en) * | 1992-07-29 | 1997-11-04 | Virtual Computer Corporation | FPGA virtual computer for executing a sequence of program instructions by successively reconfiguring a group of FPGA in response to those instructions |
| US5497498A (en) | 1992-11-05 | 1996-03-05 | Giga Operations Corporation | Video processing module using a second programmable logic device which reconfigures a first programmable logic device for data transformation |
| US5392437A (en) | 1992-11-06 | 1995-02-21 | Intel Corporation | Method and apparatus for independently stopping and restarting functional units |
| US5361373A (en) | 1992-12-11 | 1994-11-01 | Gilson Kent L | Integrated circuit computing device comprising a dynamically configurable gate array having a microprocessor and reconfigurable instruction execution means and method therefor |
| GB9303084D0 (en) | 1993-02-16 | 1993-03-31 | Inmos Ltd | Programmable logic circuit |
| JPH06276086A (ja) | 1993-03-18 | 1994-09-30 | Fuji Xerox Co Ltd | フィールドプログラマブルゲートアレイ |
| US5548773A (en) | 1993-03-30 | 1996-08-20 | The United States Of America As Represented By The Administrator Of The National Aeronautics And Space Administration | Digital parallel processor array for optimum path planning |
| US5596742A (en) | 1993-04-02 | 1997-01-21 | Massachusetts Institute Of Technology | Virtual interconnections for reconfigurable logic systems |
| US5473266A (en) | 1993-04-19 | 1995-12-05 | Altera Corporation | Programmable logic device having fast programmable logic array blocks and a central global interconnect array |
| DE4416881C2 (de) | 1993-05-13 | 1998-03-19 | Pact Inf Tech Gmbh | Verfahren zum Betrieb einer Datenverarbeitungseinrichtung |
| IL109921A (en) * | 1993-06-24 | 1997-09-30 | Quickturn Design Systems | Method and apparatus for configuring memory circuits |
| US5444394A (en) | 1993-07-08 | 1995-08-22 | Altera Corporation | PLD with selective inputs from local and global conductors |
| JPH0736858A (ja) | 1993-07-21 | 1995-02-07 | Hitachi Ltd | 信号処理プロセッサ |
| US5457644A (en) | 1993-08-20 | 1995-10-10 | Actel Corporation | Field programmable digital signal processing array integrated circuit |
| US5440538A (en) | 1993-09-23 | 1995-08-08 | Massachusetts Institute Of Technology | Communication system with redundant links and data bit time multiplexing |
| US5455525A (en) | 1993-12-06 | 1995-10-03 | Intelligent Logic Systems, Inc. | Hierarchically-structured programmable logic array and system for interconnecting logic elements in the logic array |
| US5535406A (en) | 1993-12-29 | 1996-07-09 | Kolchinsky; Alexander | Virtual processor module including a reconfigurable programmable matrix |
| AU700629B2 (en) | 1994-03-22 | 1999-01-07 | Hyperchip Inc. | Efficient direct cell replacement fault tolerant architecture supporting completely integrated systems with means for direct communication with system operator |
| US5561738A (en) | 1994-03-25 | 1996-10-01 | Motorola, Inc. | Data processor for executing a fuzzy logic operation and method therefor |
| US5761484A (en) | 1994-04-01 | 1998-06-02 | Massachusetts Institute Of Technology | Virtual interconnections for reconfigurable logic systems |
| US5430687A (en) | 1994-04-01 | 1995-07-04 | Xilinx, Inc. | Programmable logic device including a parallel input device for loading memory cells |
| US5896551A (en) * | 1994-04-15 | 1999-04-20 | Micron Technology, Inc. | Initializing and reprogramming circuitry for state independent memory array burst operations control |
| US5426378A (en) | 1994-04-20 | 1995-06-20 | Xilinx, Inc. | Programmable logic device which stores more than one configuration and means for switching configurations |
| JP2671804B2 (ja) | 1994-05-27 | 1997-11-05 | 日本電気株式会社 | 階層型資源管理方法 |
| US5532693A (en) | 1994-06-13 | 1996-07-02 | Advanced Hardware Architectures | Adaptive data compression system with systolic string matching logic |
| US5513366A (en) | 1994-09-28 | 1996-04-30 | International Business Machines Corporation | Method and system for dynamically reconfiguring a register file in a vector processor |
| EP0707269A1 (en) | 1994-10-11 | 1996-04-17 | International Business Machines Corporation | Cache coherence network for a multiprocessor data processing system |
| US5493239A (en) | 1995-01-31 | 1996-02-20 | Motorola, Inc. | Circuit and method of configuring a field programmable gate array |
| US5532957A (en) | 1995-01-31 | 1996-07-02 | Texas Instruments Incorporated | Field reconfigurable logic/memory array |
| US5742180A (en) | 1995-02-10 | 1998-04-21 | Massachusetts Institute Of Technology | Dynamically programmable gate array with multiple contexts |
| US5659785A (en) | 1995-02-10 | 1997-08-19 | International Business Machines Corporation | Array processor communication architecture with broadcast processor instructions |
| US6052773A (en) | 1995-02-10 | 2000-04-18 | Massachusetts Institute Of Technology | DPGA-coupled microprocessors |
| US5537057A (en) | 1995-02-14 | 1996-07-16 | Altera Corporation | Programmable logic array device with grouped logic regions and three types of conductors |
| US5892961A (en) | 1995-02-17 | 1999-04-06 | Xilinx, Inc. | Field programmable gate array having programming instructions in the configuration bitstream |
| US5570040A (en) | 1995-03-22 | 1996-10-29 | Altera Corporation | Programmable logic array integrated circuit incorporating a first-in first-out memory |
| US5541530A (en) | 1995-05-17 | 1996-07-30 | Altera Corporation | Programmable logic array integrated circuits with blocks of logic regions grouped into super-blocks |
| US5646544A (en) | 1995-06-05 | 1997-07-08 | International Business Machines Corporation | System and method for dynamically reconfiguring a programmable gate array |
| US5559450A (en) | 1995-07-27 | 1996-09-24 | Lucent Technologies Inc. | Field programmable gate array with multi-port RAM |
| US5784313A (en) * | 1995-08-18 | 1998-07-21 | Xilinx, Inc. | Programmable logic device including configuration data or user data memory slices |
| US5778439A (en) | 1995-08-18 | 1998-07-07 | Xilinx, Inc. | Programmable logic device with hierarchical confiquration and state storage |
| US5583450A (en) | 1995-08-18 | 1996-12-10 | Xilinx, Inc. | Sequencer for a time multiplexed programmable logic device |
| US5652894A (en) | 1995-09-29 | 1997-07-29 | Intel Corporation | Method and apparatus for providing power saving modes to a pipelined processor |
| US5943242A (en) * | 1995-11-17 | 1999-08-24 | Pact Gmbh | Dynamically reconfigurable data processing system |
| US5936424A (en) | 1996-02-02 | 1999-08-10 | Xilinx, Inc. | High speed bus with tree structure for selecting bus driver |
| US5956518A (en) | 1996-04-11 | 1999-09-21 | Massachusetts Institute Of Technology | Intermediate-grain reconfigurable processing device |
| US5894565A (en) | 1996-05-20 | 1999-04-13 | Atmel Corporation | Field programmable gate array with distributed RAM and increased cell utilization |
| US6023564A (en) * | 1996-07-19 | 2000-02-08 | Xilinx, Inc. | Data processing system using a flash reconfigurable logic device as a dynamic execution unit for a sequence of instructions |
| US5838165A (en) | 1996-08-21 | 1998-11-17 | Chatter; Mukesh | High performance self modifying on-the-fly alterable logic FPGA, architecture and method |
| US5828858A (en) | 1996-09-16 | 1998-10-27 | Virginia Tech Intellectual Properties, Inc. | Worm-hole run-time reconfigurable processor field programmable gate array (FPGA) |
| US6005410A (en) | 1996-12-05 | 1999-12-21 | International Business Machines Corporation | Interconnect structure between heterogeneous core regions in a programmable array |
| DE19651075A1 (de) | 1996-12-09 | 1998-06-10 | Pact Inf Tech Gmbh | Einheit zur Verarbeitung von numerischen und logischen Operationen, zum Einsatz in Prozessoren (CPU's), Mehrrechnersystemen, Datenflußprozessoren (DFP's), digitalen Signal Prozessoren (DSP's) oder dergleichen |
| DE19654595A1 (de) | 1996-12-20 | 1998-07-02 | Pact Inf Tech Gmbh | I0- und Speicherbussystem für DFPs sowie Bausteinen mit zwei- oder mehrdimensionaler programmierbaren Zellstrukturen |
| DE19654593A1 (de) * | 1996-12-20 | 1998-07-02 | Pact Inf Tech Gmbh | Umkonfigurierungs-Verfahren für programmierbare Bausteine zur Laufzeit |
| DE19654846A1 (de) * | 1996-12-27 | 1998-07-09 | Pact Inf Tech Gmbh | Verfahren zum selbständigen dynamischen Umladen von Datenflußprozessoren (DFPs) sowie Bausteinen mit zwei- oder mehrdimensionalen programmierbaren Zellstrukturen (FPGAs, DPGAs, o. dgl.) |
| DE19704044A1 (de) * | 1997-02-04 | 1998-08-13 | Pact Inf Tech Gmbh | Verfahren zur automatischen Adressgenerierung von Bausteinen innerhalb Clustern aus einer Vielzahl dieser Bausteine |
| DE19704728A1 (de) * | 1997-02-08 | 1998-08-13 | Pact Inf Tech Gmbh | Verfahren zur Selbstsynchronisation von konfigurierbaren Elementen eines programmierbaren Bausteines |
| WO1998038958A1 (en) | 1997-03-05 | 1998-09-11 | Massachusetts Institute Of Technology | A reconfigurable footprint mechanism for omnidirectional vehicles |
| US6125408A (en) * | 1997-03-10 | 2000-09-26 | Compaq Computer Corporation | Resource type prioritization in generating a device configuration |
| US5884075A (en) * | 1997-03-10 | 1999-03-16 | Compaq Computer Corporation | Conflict resolution using self-contained virtual devices |
| US6085317A (en) * | 1997-08-15 | 2000-07-04 | Altera Corporation | Reconfigurable computer architecture using programmable logic devices |
| US6321366B1 (en) * | 1997-05-02 | 2001-11-20 | Axis Systems, Inc. | Timing-insensitive glitch-free logic system and method |
| US6389379B1 (en) * | 1997-05-02 | 2002-05-14 | Axis Systems, Inc. | Converification system and method |
| US6421817B1 (en) * | 1997-05-29 | 2002-07-16 | Xilinx, Inc. | System and method of computation in a programmable logic device using virtual instructions |
| US6047115A (en) * | 1997-05-29 | 2000-04-04 | Xilinx, Inc. | Method for configuring FPGA memory planes for virtual hardware computation |
| US6122719A (en) | 1997-10-31 | 2000-09-19 | Silicon Spice | Method and apparatus for retiming in a network of multiple context processing elements |
| US6108760A (en) | 1997-10-31 | 2000-08-22 | Silicon Spice | Method and apparatus for position independent reconfiguration in a network of multiple context processing elements |
| US5915123A (en) * | 1997-10-31 | 1999-06-22 | Silicon Spice | Method and apparatus for controlling configuration memory contexts of processing elements in a network of multiple context processing elements |
| US6127908A (en) | 1997-11-17 | 2000-10-03 | Massachusetts Institute Of Technology | Microelectro-mechanical system actuator device and reconfigurable circuits utilizing same |
| WO1999038071A1 (en) | 1998-01-26 | 1999-07-29 | Chameleon Systems, Inc. | Reconfigurable logic for table lookup |
| US6282627B1 (en) | 1998-06-29 | 2001-08-28 | Chameleon Systems, Inc. | Integrated processor and programmable data path chip for reconfigurable computing |
| US6243808B1 (en) | 1999-03-08 | 2001-06-05 | Chameleon Systems, Inc. | Digital data bit order conversion using universal switch matrix comprising rows of bit swapping selector groups |
| US6347346B1 (en) | 1999-06-30 | 2002-02-12 | Chameleon Systems, Inc. | Local memory unit system with global access for use on reconfigurable chips |
| US6370596B1 (en) | 1999-08-03 | 2002-04-09 | Chameleon Systems, Inc. | Logic flag registers for monitoring processing system events |
| US6341318B1 (en) | 1999-08-10 | 2002-01-22 | Chameleon Systems, Inc. | DMA data streaming |
| US6311200B1 (en) | 1999-09-23 | 2001-10-30 | Chameleon Systems, Inc. | Reconfigurable program sum of products generator |
| US6288566B1 (en) | 1999-09-23 | 2001-09-11 | Chameleon Systems, Inc. | Configuration state memory for functional blocks on a reconfigurable chip |
| US6349346B1 (en) | 1999-09-23 | 2002-02-19 | Chameleon Systems, Inc. | Control fabric unit including associated configuration memory and PSOP state machine adapted to provide configuration address to reconfigurable functional unit |
| US6392912B1 (en) | 2001-01-10 | 2002-05-21 | Chameleon Systems, Inc. | Loading data plane on reconfigurable chip |
-
1998
- 1998-02-25 DE DE19807872A patent/DE19807872A1/de not_active Withdrawn
-
1999
- 1999-02-25 CA CA002321877A patent/CA2321877A1/en not_active Abandoned
- 1999-02-25 EP EP99913087A patent/EP1057117B1/de not_active Expired - Lifetime
- 1999-02-25 DE DE59901447T patent/DE59901447D1/de not_active Expired - Lifetime
- 1999-02-25 DE DE59901446T patent/DE59901446D1/de not_active Expired - Lifetime
- 1999-02-25 DE DE19980309T patent/DE19980309D2/de not_active Expired - Lifetime
- 1999-02-25 AU AU33262/99A patent/AU3326299A/en not_active Abandoned
- 1999-02-25 EP EP99914430A patent/EP1057102B1/de not_active Expired - Lifetime
- 1999-02-25 AU AU31371/99A patent/AU3137199A/en not_active Abandoned
- 1999-02-25 EA EA200000880A patent/EA003407B1/ru not_active IP Right Cessation
- 1999-02-25 EP EP01120095A patent/EP1164474A3/de not_active Withdrawn
- 1999-02-25 EA EA200000879A patent/EA003406B1/ru not_active IP Right Cessation
- 1999-02-25 WO PCT/DE1999/000505 patent/WO1999044120A2/de active IP Right Grant
- 1999-02-25 AT AT99913087T patent/ATE217715T1/de not_active IP Right Cessation
- 1999-02-25 AT AT99914430T patent/ATE217713T1/de not_active IP Right Cessation
- 1999-02-25 CA CA002321874A patent/CA2321874A1/en not_active Abandoned
- 1999-02-25 US US09/623,113 patent/US6571381B1/en not_active Expired - Lifetime
- 1999-02-25 WO PCT/DE1999/000504 patent/WO1999044147A2/de active IP Right Grant
- 1999-02-25 DE DE19980312T patent/DE19980312D2/de not_active Expired - Fee Related
- 1999-02-25 CN CN99805452A patent/CN1298520A/zh active Pending
- 1999-02-25 JP JP2000533804A patent/JP4338308B2/ja not_active Expired - Fee Related
- 1999-02-25 JP JP2000533829A patent/JP4215394B2/ja not_active Expired - Fee Related
- 1999-02-25 US US09/623,052 patent/US6480937B1/en not_active Expired - Lifetime
- 1999-02-25 CN CN99805453A patent/CN1298521A/zh active Pending
- 1999-02-25 EP EP10012017A patent/EP2293193A1/de not_active Withdrawn
-
2002
- 2002-07-09 US US10/191,926 patent/US6687788B2/en not_active Expired - Lifetime
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN100397331C (zh) * | 2001-09-07 | 2008-06-25 | Ip菲力股份有限公司 | 数据处理系统以及控制方法 |
| CN101539889B (zh) * | 2004-03-30 | 2011-11-09 | 英特尔公司 | 提高存储性能 |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN1298520A (zh) | 按照层结构具有二维或多维可编程序的单元结构(FPGAs、DPGAs等)的数据流处理器和模块的高速缓存配置数据方法 | |
| CN1378665A (zh) | 编程概念 | |
| CN1287282C (zh) | 执行实时操作的方法和系统 | |
| CN1111790C (zh) | 检查点处理加速装置及具有该装置的计算机 | |
| CN1130644C (zh) | 一种在具有多系统总线的计算机系统中保持存储器相关性的系统和方法 | |
| CN1324861C (zh) | 位串的校验方法及装置 | |
| CN1236380C (zh) | 具随机数产生器及用于存储随机数数据的指令的微处理器 | |
| CN1282929C (zh) | 高速缓存一致性协议的非随机分布式冲突解决 | |
| CN1427335A (zh) | 电路组控制系统 | |
| CN1284095C (zh) | 多处理器系统中的任务分配方法和多处理器系统 | |
| CN1282925C (zh) | 利用页标志寄存器跟踪存储器装置内物理页的状态的方法 | |
| CN1601474A (zh) | 执行实时操作的方法和系统 | |
| CN1299177C (zh) | 数据管理装置、计算机系统及数据处理方法 | |
| CN1218565A (zh) | 多路径fifo库缓冲器以及总线传送控制系统 | |
| CN1573656A (zh) | 并行处理系统中的电源管理系统及电源管理程序 | |
| CN1221909C (zh) | 并行处理方法中的作业分配方法及并行处理方法 | |
| CN1175034A (zh) | 存储器控制器和存储器控制系统 | |
| CN1577311A (zh) | 调度方法和实时处理系统 | |
| CN1669018A (zh) | 手持终端框架系统 | |
| CN1592905A (zh) | 自动产生数据库查询的系统和方法 | |
| CN1577316A (zh) | 单处理器操作系统并行处理系统中的安全管理系统 | |
| CN1670721A (zh) | 应用单处理器操作系统的并行处理系统中的处理器间通信系统及其程序 | |
| CN101034381A (zh) | 多主机系统和数据传送系统 | |
| CN1860441A (zh) | 用于可重新配置环境中的高效高性能数据操作元件 | |
| CN1383511A (zh) | 通过重排序存储器请求提高总线利用率的存储器控制器 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| C06 | Publication | ||
| PB01 | Publication | ||
| C10 | Entry into substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| AD01 | Patent right deemed abandoned | ||
| C20 | Patent right or utility model deemed to be abandoned or is abandoned |