-
ALLGEMEINER
STAND DER TECHNIK
-
Gebiet der Erfindung
-
Die
Erfindung betrifft Systeme, welche maschinenlesbare Etiketten verwenden,
um Daten zu speichern und sie Lesegeräten zu übermitteln, wenn sie gescannt
werden. Beispiele sind ein- und zweidimensionale Strichcodes, Memory
Buttons, Chipkarten (Smartcards), Radiofrequenz-Identifikations-(RFID-)
Tags, Magnetstreifen, Mikrochip-Transponder
usw.
-
Stand der
Technik
-
Gegenwärtig existieren
verschiedene Vorrichtungen zum Codieren von Daten, bzw. sie befinden
sich in der Entwicklung. Diese nehmen viele unterschiedliche Formen
an, von optischen Vorrichtungen wie etwa zweidimensionalen Strichcodes
bis hin zu Funkvorrichtungen wie etwa Transpondern. Diese Vorrichtungen
ermöglichen
im Allgemeinen, dass Objekte mit Tags versehen oder etikettiert
werden, um Maschinen zu ermöglichen,
Daten zu lesen, die mit dem Objekt verknüpft sind. Die Verwendung von
eindimensionalen Strichcodes für
diesen Zweck war weit verbreitet, doch sie weisen Einschränkungen
auf, was die Menge der Informationen anbelangt, die sie speichern
können.
Zum Beispiel können
sie Klassen von Objekten kennzeichnen, nicht jedoch einzelne Objekte.
-
Eine
Neuentwicklung auf diesem Gebiet, Radiofrequenz-Identifikations-(Radio-Frequency
Identifier, RFID-) Tags, liefert Informationen über Funksignale an ein Lesegerät, genauso
wie ein Transponder. Eines der attraktiven Merkmale von RFID-Elementen ist ihre
Fähigkeit,
eine große
Menge an Informationen zu speichern. Dies steht im Gegensatz zu
herkömmlichen
Strichcodes, deren Datenkapazität
wesentlich begrenzter ist. Eine andere Alternative zu herkömmlichen
Strichcodes sind zweidimensionale Strichcodes. Dies sind zweidimensionale
Symbole, welche in der Lage sind, viel mehr Daten zu codieren als
ein herkömmlicher
Strichcode. Eine andere Codiereinrichtung ist der iButton®,
eine kleine Marke, welche Informationen speichert, die von einem
Lesegerät
gelesen werden können,
der einen elektrischen Kontakt mit dem iButton® herstellt.
Zu den sonstigen Vorrichtungen zum Speichern von Informationen gehören gedruckte
und nicht gedruckte (d.h. geätzte)
maschinenlesbare Symbole (z.B. unter Anwendung eines Mustererkennungs-Prozesses)
und digitale Wasserzeichen.
-
Es
ist zu erwarten, dass kommerzielle Anwendungen der RFID-Technologie
sehr erfolgreich sein werden. Eine der wichtigsten ist das Supply
Chain Management (Lieferkettenmanagement). Es ist geplant, dass Hersteller
die Seriennummer eines jeden Produkts in einer Datenbank registrieren,
auf welche während
der Wanderung des Produktes durch die Lieferkette zugegriffen werden
könnte.
Durch Aufbewahrung der Daten auf einer Netzressource wie etwa einem
Server könnte
ein Diensteanbieter Ladengeschäfte
oder Warenlager in die Lage versetzen, mit Hilfe eines tragbaren
Scanners die Vorgeschichte des Produktes zu prüfen. Einzelhändler könnten somit
eine Prüfung
auf Echtheit oder Diebstahl durchführen sowie Trends überwachen,
die ausgehende Lagerbestände
und nachlassende Nachfrage betreffen. RFID-Tags können programmierbar
sein und können
auch Sensoren enthalten, welche direkt im Tag verschiedene Umweltfaktoren
aufzeichnen können,
wie etwa die Zeitdauer, welche eine Kiste mit Obst bei einer gegebenen
Temperatur gelagert wurde.
-
Ein
offensichtliches Modell für
einen zukünftigen
Verbrauchermarkt für
RFID-Tags ist der gegenwärtige Verbrauchermarkt
für Strichcodeleser.
Während
Strichcodeleser durch industrielle und gewerbliche Anwender in großem Umfang
eingeführt
worden sind, war von Herstellern und Lieferanten unternommenen Versuchen, die
Verbrauchermärkte
zu entwickeln, ein sehr begrenzter Erfolg beschieden. Einige Beispiele
von gegenwärtigen
und zukünftigen
Verbraucheranwendungen werden weiter unten erörtert.
-
Ein
Beispiel eines Strichcodeleser-Produktes, das für Verbraucher vorgesehen ist,
ist der Cue Cat®, ein
Lesegerät,
das dazu bestimmt ist, an einem Computer installiert zu werden,
und verwendet wird, um Strichcodes zu lesen, die in Katalogen und
Zeitschriftenanzeigen sowie auf Etiketten von Produkten gedruckt
sind. Wenn ein Benutzer einen Strichcode scannt, wird der Code automatisch über das
Internet zu einem Server übermittelt,
welcher den Browser des Benutzers auf eine Website für den betreffenden
Strichcode hinweist. Dem Benutzer wird die Mühe erspart, eine Webadresse
einzugeben, welche, wie man sich vorstellen kann, lang sein könnte, wenn
jedes Produkt seine eigene Webadresse hätte; viel größer ist
der Nutzen jedoch nicht. Außerdem
können
Webadressen für
existierende Produkte (wie eine Jahre alte Dose mit Pfirsichen im Schrank)
generiert werden, ohne dass der Benutzer eines nachschlagen muss
(wie etwa durch Suchen mit einer Suchmaschine). Falls der Anbieter
des Cue Cat® Dienstes
es versäumt,
den Link für
ein Produkt zur Verfügung
zu stellen, können
Benutzer eine Webadresse vorschlagen. Eine andere, ähnliche
vorgeschlagene Anwendung sind Strichcodes auf Coupons, welche den
Benutzer zu einem "Bonus-Coupon"-Abschnitt auf einer Website
führen.
-
Eine
andere vorgeschlagene Anwendung sind Rezeptbücher mit Strichcodes, welche
ein Benutzer scannen kann, wonach er automatisch eine Einkaufsliste
für das
Lebensmittelgeschäft
erzeugen kann. Der Benutzer wählt,
was gekauft werden soll, indem er zu Hause Strichcodes auf Etiketten
von Produkten scannt. Daraus erzeugt ein Dienst eine Einkaufsliste,
die in das Geschäft
mitgenommen und als Ernährungsanleitung verwendet
werden kann. Mit Hilfe eines schnurlosen Strichcodescanners scannt
der Benutzer Strichcodes auf Schachteln oder Schutzhüllen von
Lebensmittelprodukten ein, um sie der Benutzer-Einkaufsliste hinzuzufügen. Der
Scanner wird vor dem Einkaufen mit einem Computer synchronisiert,
und mittels einer Internetverbindung wird die personalisierte Einkaufsliste
erzeugt und ausgedruckt. Die Einkaufsliste enthält gesunde Empfehlungen für die Artikel
auf der Liste, welche als ähnlich
zu denjenigen, die ursprünglich
gescannt wurden, jedoch als besser mit den angegebenen Ernährungszielen
des Benutzers vereinbar identifiziert werden. Es sind Kategorien
vorgesehen, wie etwa weniger Fett, weniger Kalium, weniger Kalorien
oder andere Optionen. Die Liste ist in zwei Spalten unterteilt,
von denen eine empfohlene Alternativen und eine die ursprünglich gescannten
Artikel enthält.
Für jeden
Artikel wird eine Erläuterung
mitgeliefert, weshalb das betreffende Lebensmittelprodukt besser
ist. Außerdem
wird eine Angabe mitgeliefert, wie nahe das ursprüngliche
Produkt der besten Auswahl des Systems für die Produktklasse kommt.
Ein Rezept-Bildsymbol neben manchen Artikeln fordert den Benutzer
auf, Links zu Rezepten anzuklicken, in denen die Artikel auf der
Einkaufsliste verwendet werden und die mit dem Ernährungsprofil
konform sind. Für
Lebensmittelhändler,
die einen Dienst abonnieren, können
Gutscheinangebote auf der Einkaufsliste eingegeben und sogar zur
Paybackkarten-Datei des Benutzers heruntergeladen werden.
-
Bei
verschiedenen anderen Anwendungen werden tragbare Lesegeräte verwendet,
bzw. ihre Verwendung ist beabsichtigt. Zum Beispiel kann ein Verbraucher
ein Verzeichnis von mit Strichcodes versehenen Wertgegenständen, wie
etwa Fahrrädern, Camcordern,
Autos usw., führen.
Eine andere Anwendung ermöglicht
Benutzern, Artikel bei teilnehmenden Einzelhändlern zu scannen und eine "Wunschliste" zu erstellen, welche
sie auf einer personalisierten Webseite bekannt machen können. Die
Liste kann organisiert und für
Anlässe,
die mit Geschenken verbunden sind, per E-Mail an andere übermittelt
werden. Käufer
melden sich bei einem Geschäft
eines Einkaufszentrums an, richten ein Passwort ein und leihen einen
Scanner aus. Käufer
erstellen dann ihre "Wunschliste", indem sie einfach
Strichcodes von Produkten scannen. Die Daten werden danach zu dem
Geschäft
heruntergeladen, wenn der Scanner zurückgegeben wird, und die Wunschliste
wird auf der Website bekannt gemacht. Eine weitere Anwendung, welche
dem Cue Cat® sehr ähnlich ist,
ist die Idee, einen Strichcode auf einem Kinokarten-Abschnitt oder
Ticketabschnitt einer Sportveranstaltung anzubringen. Der Strichcode
bringt den Benutzer auf dieselbe Art und Weise wie bei Cue Cat® automatisch
zu einer Website, welche dem Benutzer ermöglicht, Produkte zu kaufen,
die mit dem Ereignis zusammenhängen,
wie etwa Sport-Erinnerungsstücke oder
Soundtracks von Filmen. Bei einer anderen, von AirClic® angebotenen
Anwendung werden an Druckerzeugnissen angebrachte Strichcodes verwendet,
um den Benutzer zu einer Website zu bringen, die den Zugang zu aktualisierten
Informationen, Einkaufsmöglichkeiten
oder anderen Web-Merkmalen ermöglicht,
die mit dem Artikel zusammenhängen.
Es ist vorgesehen, diese Technik in handliche Geräte wie etwa
Mobiltelefone zu integrieren, so dass sich der Benutzer nicht in
der Nähe
eines Computers befinden muss, um sie zu benutzen.
-
Die
obigen Beispiele veranschaulichen verschiedenartige Versuche von
Herstellern, Verbraucheranwendungen für ihre Produkte zu finden.
Die meisten davon sind einmalige (spezialisierte) Ideen und bringen wenig
Vorteile gegenüber
den herkömmlichen
Wegen, die jeweiligen Aufgaben zu lösen. Die Wunschlisten-Anwendung
ist hoch spezialisiert, ebenso wie die Anwendung betreffs der Einkaufsliste
für das
Lebensmittelgeschäft
und die Anwendung betreffs des Heim-Bestandsverzeichnisses. In Anbetracht
der weiten Verbreitung von Strichcodes ist es überraschend, dass noch niemand
wirklich nützliche
Möglichkeiten
ersonnen hat, wie sie verwendet werden könnten, zumindest für Verbraucher.
Wie oben erörtert,
kann ein Element eines Durchbruchs darin bestehen, die Datenmenge
zu vergrößern, welche
auf Strichcode- oder anderen Typen von Datenspeicherträgern gespeichert
werden können.
Obwohl dies für
sich allein noch nicht bewirken wird, dass den Köpfen der Konstrukteure "Killerapplikationen" entspringen, ergeben
sich viele Vorteile in Verbindung mit der erhöhten Datenkapazität von RFID-Tags
und anderen Technologien zum Speichern größerer Datenmengen, als mit
herkömmlichen
Strichcodes.
-
Im
Unterschied zu Strichcodes, welche lediglich genug Daten codieren
können,
um eine kleine Menge an Informationen zu zueinander in Beziehung
zu setzen, können
manche maschinenlesbaren Etiketten-Mittel (Machine-readable Label
Devices, MRL-Mittel)
genug Informationen speichern, um einige sehr interessante Dinge
zu vollbringen. Zum Beispiel kann ein solches Etikett, wenn es an
einem Produkt angebracht ist, das betreffende Produkt eindeutig
identifizieren, welches in einer zentralen Datenbank verknüpft sein
könnte
mit seinem Herstellungsdatum, dem Transportmittel, in dem es transportiert
wurde, seinem Versanddatum, dem Einzelhändler, an den es versendet
wurde, damit, an wen es verkauft wurde, wie es hergestellt wurde,
wann, usw. Außerdem
können
manche MRL-Mittel
auch so programmiert sein, dass sie die in ihnen gespeicherten Daten
verändern,
wie es zum Beispiel bei der oben erwähnten, Lieferketten-Anwendung
mit Temperaturmessung der Fall ist. Ein anderer Vorteil ist, dass
manche von ihnen gescannt werden können, indem ein Lesegerät in einem
gewissen Abstand von ihnen gehalten wird, ohne mit dem Lesegerät genau
bezüglich
des MRL-Mittels zu zielen. Manche Lesegeräte sind in der Lage, viele
MRL-Mittel auf einmal zu lesen, zum Beispiel RFID-Lesegeräte.
-
Im
Allgemeinen waren MRL-Mittel recht teuer, so dass wenig Anwendungen
für den
Verbrauchermarkt entwickelt worden sind. Ein Beispiel eines auf
Verbraucher ausgerichteten Systems, welches nicht stark durch die
Kosten beeinträchtigt
wird, ist ein Supermarkt-System für die Werbung für Produkte.
In diesem System nimmt sich ein Benutzer eine Einkaufskarte, die
mit einem tragbaren Funkendgerät
ausgestattet ist. Wenn der Benutzer durch die Regalreihen geht,
kommt er an gewissen Funksendestationen vorbei, welche so eingerichtet
worden sind, dass sie für
Produkte werben, die sich in der Nähe dieser Stationen in den
Regalen befinden. Wenn sich der Benutzer einer solchen Station nähert, empfängt das
tragbare Funkendgerät
eine Nachricht von der Station und beginnt, eine Werbegrafik anzuzeigen
und/oder eine Textnachricht mit begleitendem Ton abzuspielen. Die
Grafik und die Text-/Audionachricht stammen von irgendeiner anderen
Quelle, wie etwa einem Netzserver, mit welchem das Endgerät drahtlos
verbunden ist. Die Station sendet eine eindeutige Kennung, welche
das Endgerät
auffordert, die Grafik und die Text-/Audionachricht wiederzugeben, die der
Kennung entspricht. Es ist zu erwarten, dass ähnliche Anwendungen in einem
größeren Spektrum
von Kontexten erfolgen werden, wenn die Kosten von MRL-Mitteln mit
hoher Dichte sinken.
-
In
Forschungsprojekten, wie etwa im Media Lab des Massachusetts Institute
of Technology (MIT), wurde die Verwendung von RFID-Tags zur Automatisierung
vieler Tätigkeiten
untersucht. Zum Beispiel hatte ein Projekt die Konstruktion einer
Kaffeemaschine zum Ergebnis, welche die Identität des Besitzers eines zum Einfüllen von
Kaffee in die Maschine gestellten Kaffeebechers lesen konnte. Unter
Verwendung dieser Information bereitete die Maschine die bestimmte
Art von Kaffee zu, die von dem Besitzer des Bechers vorgezogen wurde, und
spielte die Musik, die er bevorzugte. Eine andere von dem Media
Lab vorgeschlagene Anwendung ist ein Kühlschrank, welcher den Inhalt
aus den RFID-Tags
ausliest und dabei ein Bestandsverzeichnis führt. Ein anderes Beispiel war
ein Mikrowellenherd, welcher dem Benutzer Anweisungen gab und sich
selbst für
den Typ von Lebensmitteln (der von einem RFID-Tag angegeben wird)
programmierte, welche zuzubereiten waren. Man stellt sich vor, dass
diese Systeme Bestandteile eines Haushaltnetzes mit allen möglichen
Arten von Ein- und Ausgabevorrichtungen werden, die alle intelligent
sind und auf die Umwelt reagieren. Der Kühlschrank weiß, was der
Herd macht. Herde, Spülen
usw. kennen alle ihren Inhalt und Zustand und sind in der Lage,
auf Objekte sowohl physisch als auch digital einzuwirken. Die Schränke können einen
Benutzer beraten, ob er über
sämtliche
Zutaten verfügt,
die man für
ein Rezept benötigt.
Die Küche
beobachtet den Benutzer, der nach dem Rezept kocht, und gibt Hinweise,
die mit der Tätigkeit
des Benutzers synchronisiert sind.
-
Ein
White Paper, das von Joseph Kaye vom MIT Media Lab verfasst wurde,
bot eine Reihe von Konzepten an, welche das die vorliegende Erfindung
umfassende Gebiet betreffen. Ein Konzept beinhaltet, das alles miteinander
verbunden ist. Zum Beispiel informiert das RFID-Tag an einem Tupperware-Behälter ein
Lesegerät
in der Spüle,
dass der Behälter
gerade gewaschen wird und daher leer ist. Die Lebensmittel, die
in dem Behälter
aufbewahrt worden waren, wurden entnommen, und der Behälter wurde
geleert. Zuvor war ein bestimmtes Nahrungsmittel mit dem RFID-Tag
des Behälters
durch den Kühlschrank
verknüpft
worden, welcher, als der Behälter
in den Kühlschrank
gestellt wurde, nach Informationen über den Inhalt des Behälters "fragte". Der Inhalt war
danach Teil des Lebensmittel-Bestandsverzeichnisses, bis der Behälter geleert
wurde. Eine intelligente Küche,
wie sie dem MIT Media Lab vorschwebt, hilft einem Benutzer zu kochen,
indem sie den Benutzer durch ein Rezept führt, dabei Ersatzmöglichkeiten
empfiehlt und dem Benutzer sagt, wo er Zutaten findet. Herr Kaye
schlägt
außerdem
vor, alle Produkte eindeutig zu kennzeichnen und jedes mit einer
individuellen Webseite auszustatten, von der aus jede Einzelheit
der Vorgeschichte dieses bestimmten Produkts erhältlich ist.
-
Beim
gegenwärtigen
Stand der Technik besteht Bedarf an Anwendungen für Codeleseeinrichtungen, welche
reale Vorteile bieten, die Verbraucher wünschen werden, und daran, diese
Vorteile möglichst
problemlos bereitzustellen, so dass Verbraucher die Anwendungen
akzeptieren werden.
-
Im
Dokument US-B1-6199048 wird ein Verfahren zum Anzeigen einer Nachricht,
die mit Daten verknüpft
ist, die auf einem maschinenlesbaren Etiketten-Mittel gespeichert
sind, unter Verwendung eines einen Scanner umfassenden Computers,
der an einen Netzserver angeschlossen ist, offenbart.
-
KURZDARSTELLUNG
DER ERFINDUNG
-
Die
Ansprüche
1, 6, 10 offenbaren die Erfindung. Bevorzugte Ausführungsformen
sind in den Ansprüchen
2-5, 7-9 offenbart.
-
Die
Erfindung ist für
eine Umgebung bestimmt, in welcher kostengünstige maschinenlesbare Etiketten-Mittel
(Machine-readable Label Devices, "MRL-Mittel") in sehr vielfältigen Kontexten in Erscheinung
treten, so wie gegenwärtig
Strichcodes. In der Zukunft können
MRL-Mittel mit hoher Datendichte auf käuflich zu erwerbenden Produkten,
Ticketabschnitten, Werbemedien, Versandbehältern, Feinkostbehältern usw.
erscheinen. Lesegeräte
von MRL-Mitteln können
ebenfalls weite Verbreitung finden. Zum Beispiel können sie
in solchen tragbaren Geräten
zu finden sein, wie persönlichen
Informationsplanern (Personal Information Managers, PIMs), Mobiltelefonen
oder Cross-over-Einrichtungen.
Sie können
auch eingebaut in viele gewöhnliche feststehende
Geräte
zu finden sein, wie etwa Registrierkassen, öffentlich zugängliche
Verkaufsstände,
Haushaltsgeräte,
TV-Fernbedienungen usw.
-
Obwohl
von vielen Beobachtern der technischen Entwicklung eine Welt voller
MRL-Mittel mit hoher Datendichte und Lesegeräte vorhergesagt wird, wird
dies nur dann geschehen, wenn derartige Mittel den Benutzern einen
realen Wert liefern. Die vorliegende Erfindung betrifft verschiedene
Hindernisse für
das Erreichen dieses Ziels. Ein Hindernis sind die Anforderungen,
die jede neue Technologie an Benutzer stellt. Benutzer eignen sich
nicht gern neue Arten an, Dinge zu tun, sofern es sich nicht sehr
gut auszahlt. Das Herstellen von Technik, die sowohl leicht zu verwenden
als auch nützlich
ist, bedeutet oft eine komplexe Programmierung. Ein anderes Hindernis
für eine
umfassende Akzeptanz ist die Schwierigkeit, Informationen und/oder
Dienste anzubieten, die für
die Benutzer tatsächlich
in einem breiten Spektrum von verschiedenen Kontexten von Nutzen
sind, und nicht nur in einer kleinen Anzahl eng begrenzter Kontexte.
-
Ein
Weg, MRL-Anwendungen benutzerfreundlich zu machen, besteht darin
sicherzustellen, dass sie dem Benutzer nur diejenigen Informationen
und Dienste präsentieren,
welche für
den Benutzer relevant sind. Auf diese Weise ist der Benutzer nicht
gezwungen, durch Menüs
zu navigieren oder zusätzliche
Informationen einzugeben, um zu etwas Nützlichem zu gelangen. Zu diesem
Zweck müssen
vorzugsweise die unmittelbaren Umstände und Präferenzen des Benutzers berücksichtigt
werden. Die meisten drahtlosen Anwendungen sind mit sehr wenig Kapazität für eine Personalisierung
aufgebaut, obwohl dies ein wichtiges Designelement für Webportale
ist, zu denen Benutzer immer wieder zurückkehren. Das Ziel der vorliegenden
Erfindung ist es, ein System bereitzustellen, welchem sich Benutzer
wiederholt in vielen Kontexten zuwenden werden, darunter auch in
neuen, weil sie die Erfahrung gemacht haben, dass das System gewöhnlich wertvolle
Informationen und/oder Dienste mit einem Minimum an Aufwand für sie zur
Verfügung
stellt. Andererseits besteht ein weiteres Ziel des Systems darin,
diesen Nutzen mit einem Minimum an Schwierigkeiten für Programmierer
beim Anbieten der Dienste zu liefern.
-
Die
Erfindung stellt Mechanismen bereit, mittels derer ein MRL-Lesegerät hochrelevante
Informationen oder Prozesse liefern kann, die auf eine bestimmte
Weise mit einem Artikel zusammenhängen, an welchem ein MRL-Mittel
angebracht ist, unter Berücksichtigung
anderer Umstände,
die den Benutzer betreffen, wie etwa der persönlichen Präferenzen des Benutzers, der
Umgebung des Benutzers usw. Die Erfindung stellt außerdem Mechanismen
bereit, um die große
Menge an potentiell relevanten Informationen oder Anzahl von Ressourcen
durchzugehen und diejenigen zu identifizieren, welche mit größter Wahrscheinlichkeit
die beste Auswahl für
den Benutzer darstellen, wodurch Nachfragen beim Benutzer vermieden
werden. Ferner stellt die Erfindung Mechanismen bereit, um sicherzustellen,
dass das Lesegerät
niemals nutzlose Antworten erzeugt, selbst dann, wenn es mit Anfragen
konfrontiert wird, welche unmöglich
vorhergesagt werden können,
etwa wenn ein Benutzer eine Packung Cerealien mit einem Lesegerät für Tischsägen scannt.
Ferner stellt die Erfindung Mechanismen bereit, mittels derer ein
tragbares Lesegerät
selbst dann noch Nutzen bringen kann, wenn es nicht an eine Datenbank
angeschlossen ist, welche die MRL-Daten decodieren kann.
-
Die
intelligente Nutzung vieler verfügbarer
Quellen von Informationen über
den Benutzer und seinen Status und Kontext der Verwendung zu dem
Zeitpunkt, zu dem eine Anfrage erfolgt (kurz gesagt, den "Benutzerzustand") ist aufgrund der
vielen möglichen
Systemantworten eine mühsame
Programmieraufgabe. Hinzu kommt, dass es selbst ohne das Problem,
wie die vielen möglichen
Benutzerzustände
mit vielen möglichen Antworten
zu verbinden sind, bereits an sich schwierig sein kann, die großen Anzahlen
von Antworten bereitzustellen, welche mit den möglichen Benutzerzuständen verknüpfbar sind.
-
Zu
diesem Zweck nutzt die Erfindung Fortschritte in der Suchmaschinentechnik.
Neue Suchmaschinentechniken ermöglichen
Benutzern, Anfragen in natürlicher
Sprache zu formulieren, um auf große unorganisierte Datenkörper (Webseiten)
zuzugreifen. Diese Techniken weisen das Potential auf, an eine Verwendung in
MRL-Systemen angepasst zu werden. Dies ermöglicht es, Antwortdaten in
einem relativ unstrukturierten Format zu erzeugen, indem man sich
auf eine anspruchsvolle Suchmaschinentechnik stützt, um zu bestimmen, wie Anfragen
mit den am besten geeigneten Informationen oder Diensten in einer
Ressourcendatenbank zu verbinden sind.
-
Mit
einer implementierten robusten und flexiblen Strategie zur Nutzung
aller verfügbaren
Informationen über
den Benutzerzustand ist es leichter, neue Funktionalität hinzuzufügen. Zum
einen muss ein Diensteanbieter, welcher eine Ressourcendatenbank
erstellt, keine Antwort für
jede vorhersehbare Situation ausarbeiten. Dies macht die Aufgabe
des Hinzufügens
neuer Antworten zu einer Antwortdatenbank weniger mühevoll.
Zum anderen kann eine einzige Situation vielfältige verschiedene Antworten
zulassen. Der übliche Weg,
dies zu handhaben, besteht darin, dem Benutzer eine Auswahl zu ermöglichen.
Indem die hier vorgeschlagene robuste Strategie angewendet wird,
kann das System die Vielzahl potentiell zutreffender Antworten filtern,
wodurch für
den Benutzer die Notwendigkeit entfällt, die Auswahl in aufeinander
folgenden Schritten zu treffen. Der Benutzer erhält die gewünschte Antwort schneller und
mit weniger Aufwand. Lesegeräte,
die einem bestimmten Objekt beigefügt sind, wie etwa einem Haushaltgerät, können Informationen,
die das bestimmte Objekt kennzeichnen, an die Informationsressource übermitteln.
Zum Beispiel kann der Mikrowellenherd seine Marke und Modellnummer
an die Informationsressource übermitteln,
bevor er Programmieranweisungen empfängt. Indem dar Informationsressource
spezifische Einzelheiten über
den Kontext der Anforderung von Informationen zur Verfügung gestellt
werden (z.B. "Ich
bin ein Mikrowellenherd, der sich in einer Wohnung befindet, und
ich fordere Informationen über
dieses bestimmte Tiefkühlgericht an."), kann die Informationsressource
ihre Antwort so sachdienlich wie möglich gestalten ("Du musst Programmieranweisungen
wünschen."). Ohne die Einzelheiten
des Kontextes könnten
mehrere Austauschvorgänge
zwischen einem Benutzer und der Informationsressource erforderlich
sein, bevor die relevanten Informationen zur Verfügung gestellt
würden.
Zum Beispiel könnte
der Benutzer gerade beim Einkaufen sein und etwas über das
Produkt wissen wollen, bevor er es kauft. Ohne den Kontext ist die
Situation sehr ähnlich
wie die, wenn man heute eine Website des Worldwide Web (WWW) besucht,
wo es erforderlich ist, durch einen Menübaum zu navigieren, bevor die
gewünschte
Information gefunden werden kann.
-
In
Anbetracht dessen, dass zusätzliche
Informationen, die der Informationsressource geliefert werden, die
Sachdienlichkeit von Antworten erhöhen können, können Lesegeräte so programmiert
werden, dass sie Informationen bezüglich des anfragenden Benutzers
liefern. Zum Beispiel kann ein persönliches Lesegerät ein Benutzerprofil
speichern oder auf ein Benutzerprofil zugreifen, das in einem Netz
(oder dem Internet) gespeichert ist. Der Vorteil des Letzteren ist,
dass es ferner dem antwortenden Informationsanbieter ermöglicht,
seine Antwort zu personalisieren, was die Chance erhöht, dass
sich der Benutzer nach der gelieferten Information richten wird.
Diese Personalisierungsdaten können
von dem Lesegerät übertragen
werden, oder der Informationsanbieter kann sie von einem anderen
Server beziehen, der solche Daten entsprechend einer eindeutigen Kennung
für die
Personalisierungsdaten speichert.
-
Zu
den anderen Quellen von Informationen, welche verwendet werden können, um
die Sachdienlichkeit von Antworten zu erhöhen, gehören gespeicherte historische
Nutzungsmuster/Präferenzen,
allgemeine Daten wie etwa Nachrichten, Wetter, Tageszeit, Jahreszeit
sowie Informationen von anderen Ressourcen wie etwa aus einem Bestandsverzeichnis,
das auf einem lokalen Netzserver gespeichert ist. Es folgt ein Beispiel, wie
solche Daten verwendet werden könnten.
Eine Person scannt ein MRL-Mittel, das an einem Tiefkühlgericht angebracht
ist, mit einem Lesegerät
eines Mikrowellenherdes ein. Es ist 8.00 Uhr morgens Ortszeit, so
dass es weniger wahrscheinlich ist, dass der Benutzer beabsichtigt,
das Tiefkühlgericht
zu dieser Zeit zuzubereiten. Historische Nutzungsmuster zeigen,
dass der Benutzer noch niemals am Morgen den Mikrowellenherd programmiert
hat, um Tiefkühlgerichte
zuzubereiten. Aus dem Haushalts-Bestandsverzeichnis, das auf einem Server
gespeichert ist, mit welchem das Lesegerät des Mikrowellenherdes über ein
Netz verbunden ist, geht hervor, dass der aktuelle Bestand an Tiefkühlgerichten
ein Stück
be trägt.
Gegenwärtig
ist Winter, und aus historischen Nutzungsmustern geht hervor, dass
Tiefkühlgerichte
häufig
während
der Wintermonate zubereitet werden. Das Lesegerät des Mikrowellenherdes sendet
die relevanten Informationen an eine Informationsressource, in diesem
Falle an einen in dem MRL-Mittel angegebenen Internetserver, und
empfängt
ein Menü mit mehreren
Optionen, wobei die Antworten auf die einzelnen Optionen in der
Sendung enthalten sind. Die Optionen beinhalten eine Bezeichnung
eines lokalen Geschäftes,
in dem Tiefkühlgerichte
verkauft werden, ähnliche
Produkte, die der Benutzer vielleicht ausprobieren möchte, und
Anweisungen, wie eine große
Anzahl von Tiefkühlgerichten
für eine
Dinnerparty zu erwärmen
ist. Wäre
es Mittagszeit gewesen, hätte
die Informationsressource eventuell einfach nur Zubereitungshinweise
zurückgesendet.
-
Ein
anderes Problem, das mit den Chancen für eine breite Akzeptanz von
MRL-Mitteln zusammenhängt,
besteht darin, dass es weniger wahrscheinlich ist, dass die Leute
sich an die Verwendung einer neuen Technik gewöhnen, besonders wenn deren
Verwendung eine Anpassung erfordert, wenn die Technik nur unter gewissen
Umständen
verwendbar ist. So würden
zum Beispiel, wenn nur einige Produkte, die in einem Supermarkt
käuflich
erworben werden können,
mit MRL-Mitteln ausgestattet wären
und andere nicht, die Verbraucher zwei verschiedene Verfahrensweisen
benötigen,
um die Aufgaben auszuführen,
welche die MRL-Mittel andernfalls automatisieren: eine für Artikel,
die mit MRL-Mitteln
ausgestattet sind, und eine für
Artikel, die nicht damit ausgestattet sind. So bieten zum Beispiel
MRL-Mittel die Möglichkeit,
das Führen
eines Lebensmittel-Bestandsverzeichnisses,
die Erstellung von Einkaufslisten und die Bestimmung, ob die verfügbaren Lebensmittel
ausreichend für
die Zubereitung eines Rezeptes sind, zu automatisieren. Wenn jedoch
nur ein Teil einer Einkaufsliste erstellt werden kann oder nur die
Hälfte
der Anforderungen für
ein Rezept automatisch bestimmt werden kann, wird der Nutzen einer
solchen Automatisierung stark vermindert. Daher können gemäß gewissen
Merkmalen der Erfindung MRL-Mittel für Artikel vorgesehen werden,
welche nicht abgepackt sind, wie etwa solche Verbrauchsgüter wie
Feinkostwaren, landwirtschaftliche Erzeugnisse, Fleisch usw.
-
Obwohl
vorgeschlagen worden ist, MRL-Mittel und Strichcodes zu verwenden,
um Benutzer mit Websites für
den Einkauf von Waren zu verbinden, wird durch diesen Grad einer
Automatisierung lediglich die Notwendigkeit vermieden, dass der
Benutzer eine Webadresse eingeben muss. Diese Idee ist im Grunde
genommen dieselbe wie beim Cue Cat® System.
Da maschinenlesbare Symbole wie MRL-Mittel Benutzer schnell zu einer
Website bringen können,
besitzen sie das Potential, Spontankäufe zu erleichtern. Es besteht
eine viel größere Wahrscheinlichkeit
eines Verkaufs, wenn einem Benutzer die Gelegenheit gegeben wird,
einen Filmsoundtrack sofort zu kaufen, wenn der Benutzer das Kino
verlässt
und die Musik noch frisch in Erinnerung hat. Dies könnte geschehen,
indem ein Internetterminal in einem Selbstbedienungsstand am Filmtheater
eingerichtet wird. Je kleiner die Anzahl der erforderlichen Schritte
ist, desto wahrscheinlicher kommt es zu einem Kauf. Bei einer Ausführungsform
der Erfindung ist ein MRL-Mittel an einem Ticketabschnitt angebracht.
Das Mittel kann eine Adresse enthalten, bei welcher der Filmsoundtrack
gekauft werden kann. Außerdem
enthält
das Mittel eine ausreichende Datendichte, um Konto-, Autorisations-,
Versand- und Authentifizierungsinformationen zuzuordnen oder zu
speichern, um den Abschluss des Kaufs zu ermöglichen, ohne von dem Benutzer
irgendetwas anzufordern, außer
der Auswahl und Bestätigung
eines Artikels, der gekauft werden soll. Wenn ein Kinobesucher Tickets
unter Verwendung einer Kreditkarte kauft, kann das Konto zeitweilig
mit Daten auf dem MRL-Mittel auf dem Ticketabschnitt verknüpft werden.
Diese Daten können
ferner einen Bestellvorgang mit Präferenz-Informationen verknüpfen, die
in einer Benutzerprofil-Datenbank enthalten sind, und der Kauf kann verwendet
werden, um diese Datenbank zu vergrößern. Um das Konto des Benutzers
zu schützen,
kann für die
Verbindung zwischen dem Kreditkartenkonto des Benutzers und den
Ticketdaten eine bestimmte Ablauffrist vorgegeben sein, zum Beispiel
2 Stunden nach dem Ende des Films oder anderen Ereignisses. Als
Anreiz für
den Benutzer, am Kino zu kaufen, kann dem Benutzer ein finanzieller
Anreiz gewährt
werden, wie etwa ein niedrigerer Preis bei seinem nächsten Ticketkauf,
ein Preisnachlass für
die bestellten Waren oder ein Werbegeschenk. Genau dieselben Funktionen
können über ein
tragbares Endgerät
anstelle eines Terminals in einem Kiosk gewährleistet werden, oder über einen
Heimcomputer, der an das Netz angeschlossen ist; oder sogar über einen
tragbaren Computer oder ein tragbares Endgerät.
-
Die
Erfindung wird in Verbindung mit gewissen bevorzugten Ausführungsformen
beschrieben, unter Bezugnahme auf die folgenden beispielhaften Figuren,
so dass ein umfassenderes Verständnis
der Erfindung ermöglicht
wird. Was die Figuren anbelangt, so wird betont, dass die abgebildeten
Einzelheiten nur als Beispiel und zum Zwecke der anschaulichen Erläuterung
der bevorzugten Ausführungsformen
der vorliegenden Erfindung dienen und dargestellt sind, um das zu
liefern, was nach unserer Ansicht die nützlichste und am leichtesten
verständliche
Beschreibung der Prinzipien und konzeptionellen As pekte der Erfindung
ist. In dieser Hinsicht wird nicht der Versuch unternommen, konstruktive
Einzelheiten der Erfindung detaillierter zu zeigen, als es für ein grundsätzliches
Verständnis
der Erfindung notwendig ist, da die Beschreibung in Verbindung mit
den Zeichnungen es für
Fachleute offensichtlich macht, wie die verschiedenen Formen der
Erfindung in die Praxis umgesetzt werden können.
-
KURZBESCHREIBUNG
DER ZEICHNUNGEN
-
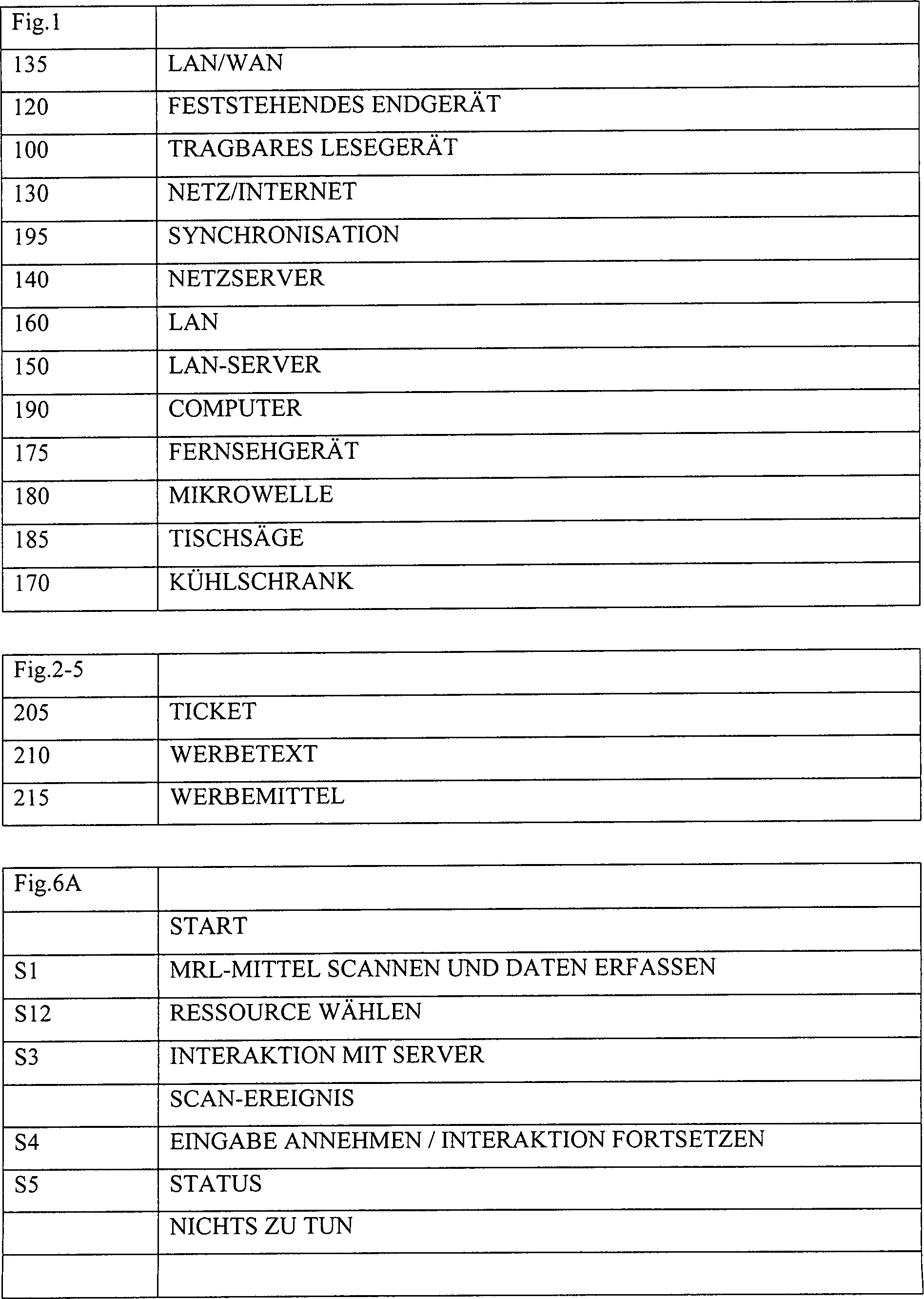
1 ist
ein Bildschema einer Hardwarekonfiguration zur Implementierung eines
Offline-Datenübertragungsvorgangs
gemäß verschiedenen
Ausführungsformen
der Erfindung.
-
2 ist
eine symbolische Darstellung eines beliebigen Produktes oder einer
Produktverpackung mit einem daran angebrachten MRL-Mittel.
-
3 ist
eine symbolische Darstellung der Vorderseite eines Ticketabschnitts
mit einem daran angebrachten MRL-Mittel.
-
4 ist
eine symbolische Darstellung der Rückseite des Ticketabschnitts
mit einem daran angebrachten MRL-Mittel.
-
5 ist
eine symbolische Darstellung einer Werbeanzeige (Zeitschrift, Plakattafel,
Poster usw.) mit einem daran angebrachten MRL-Mittel.
-
6A ist
ein Flussdiagramm, das einen Prozess darstellt, der von einem MRL-Mittel-Scanner
zur Online-Datenübertragung
gemäß einer
Ausführungsform
der Erfindung ausgeführt
wird.
-
6B ist
ein Flussdiagramm, das einen Prozess darstellt, der von einem Server
zur Online-Datenübertragung
gemäß einer
Ausführungsform
der Erfindung ausgeführt
wird.
-
7 ist
eine Darstellung eines Systems, mit dessen Hilfe ein MRL-Lesegerät gleichzeitig
eine Suche in einer strukturierten Ressourcenbank und eine Fuzzy-Suche in einer unstrukturierten
Ressourcenbank durchführen
kann, um Ergebnisse zu erhalten, welche für die Anzeige durch eine Benutzeroberfläche (User Interface,
UI) kombiniert werden können,
gemäß einer
Ausführungsform
der Erfindung.
-
8 ist
eine Darstellung eines Systems, mit dessen Hilfe ein MRL-Lesegerät gleichzeitig
eine Suche in einer strukturierten Ressourcenbank und eine Fuzzy-Suche in einer unstrukturierten
Ressourcenbank durchführen
kann, um Ergebnisse zu erhal ten, welche für die Anzeige durch eine Benutzeroberfläche kombiniert
werden können,
gemäß einer
anderen Ausführungsform
der Erfindung, bei welcher Begriffe in einer Anfrage unbedingt erweitert
werden.
-
9 zeigt
ein Benutzeroberflächen-Element
zur Anzeige von Ergebnissen, die durch die Systeme von 7 und 8 erhalten
wurden.
-
10 ist
eine Darstellung eines Systems zum Durchsuchen einer Ressourcenbank,
welches einen Parser für
natürliche
Sprache verwendet, um einen Index zum Anpassen von Ressourcen an
die Ergebnisse von MRL-Scans und begleitende Kontexte zu erzeugen.
-
11 ist
eine Darstellung eines Systems, mit dessen Hilfe ein MRL-Lesegerät gleichzeitig
eine Suche in einer strukturierten Ressourcenbank und eine Fuzzy-Suche in einer unstrukturierten
Ressourcenbank durchführen
kann, um Ergebnisse zu erhalten, welche für die Anzeige durch eine Benutzeroberfläche kombiniert
werden können,
gemäß einer
anderen Ausführungsform
der Erfindung, bei welcher Begriffe in einer Anfrage bedingt erweitert
werden.
-
12 ist
ein Flussdiagramm eines Prozesses zum Einleiten einer verzögerten Interaktion
mit einem Server gemäß einer
Ausführungsform
der Erfindung.
-
13 ist
ein Ablaufdiagramm, das ein Beispiel einer Interaktion zwischen
einem Server und einem Scanner-Terminal zeigt, bei welcher der Scanner
und der Server eine Transaktion durchführen, welche die Übertragung
von Informationen zu dem Terminal beinhaltet.
-
14 ist
ein Ablaufdiagramm, das ein Beispiel einer Interaktion zwischen
einem Server und einem Scanner-Terminal zeigt, bei welcher der Scanner
und der Server die Transaktion nicht durchführen, sondern die Übertragung
von Informationen zu dem Terminal auf einen späteren Zeitpunkt verschieben.
-
15 ist
ein Ablaufdiagramm, das ein Beispiel einer Interaktion zwischen
einem Server und einem Scanner-Terminal zeigt, bei welcher der Scanner
und der Server eine Transaktion durchführen, welche die Übertragung
von Informationen zu dem Terminal zu einem Zeitpunkt, nachdem das
Scannen erfolgt ist, beinhaltet.
-
16 ist
ein Ablaufdiagramm, das ein Beispiel einer Interaktion zwischen
einem Server und einem Scanner-Terminal zeigt, bei welcher der Scanner
und der Server eine Transaktion durchführen, welche die Übertragung
von Informationen beinhaltet, wobei die Informationen auf eine andere
Art und Weise als direkt zu dem Terminal geroutet werden.
-
17 ist
ein Flussdiagramm, das eine Prozedur darstellt, bei der auf ein
Ereignis gewartet wird, das anzeigt, dass dies ein guter Zeitpunkt
ist, um eine verzögerte
Transaktion durchzuführen,
oder auf ein Ereignis, das anzeigt, dass eine potentielle Transaktion
gelöscht
oder umgeleitet werden sollte, gemäß einer Ausführungsform
der Erfindung.
-
18 und 19 zeigen
ein über
ein Verbindungsglied zusammenhängendes
Flussdiagramm, das eine Prozedur zur Bereitstellung verschiedener
Optionen für
verschiedene Ergebnisse einer Suche auf der Basis eines Scans eines
MRL gemäß einer
Ausführungsform
der Erfindung darstellt.
-
20 ist
ein Flussdiagramm, das eine Prozedur zum passiven Scannen von MRLs
und bedingten Empfangen von Nachrichten gemäß einer Ausführungsform
der Erfindung aufzeigt.
-
21 ist
ein Flussdiagramm, das eine Prozedur aufzeigt, um einem Benutzer
zu ermöglichen,
eine neue Antwort zur Verwendung bei einem Gerät und Artikel, die durch ein
MRL-Mittel angegeben sind, zu definieren, gemäß einer Ausführungsform
der Erfindung.
-
22 ist
ein Flussdiagramm, das eine Prozedur zum Herstellen einer Verbindung
zwischen einem Konto und einem MRL auf einem Ticket oder anderen
Dokument aufzeigt, um einem Benutzer zu ermöglichen, mit dem Ticket zu
kaufen oder einer jugendlichen Person eine begrenzte Möglichkeit
einzuräumen,
Einkäufe zu
tätigen,
und um Präferenzen
und Einschränkungen
in einer Datenbank zu speichern, gemäß einer Ausführungsform
der Erfindung.
-
23 zeigt
einen einfachen Prozess zum Empfangen von Empfehlungen in Reaktion
auf die Identifizierung des Benutzers.
-
24 ist
ein Flussdiagramm, das eine Prozedur aufzeigt, um ein Suchergebnis
mit Eingabe von dem Benutzer und automatischer Identifizierung der
wesentlichsten Unterscheidungsmerkmale in dem Suchergebnis eindeutig
zu machen, gemäß einer
Ausführungsform
der Erfindung.
-
25 ist
ein Flussdiagramm, das einen Prozess zur Erweiterung von Suchbegriffen
gemäß einer Ausführungsform
der Erfindung zeigt.
-
26 ist
ein Flussdiagramm, das einen Prozess zur Erweiterung von Anfragen
gemäß einer
Ausführungsform
der Erfindung zeigt.
-
27 ist
eine Benutzeroberfläche
zum Anfordern von Informationen über
Artikel, die mit einem gescannten Artikel zusammenhängen, gemäß einer
Ausführungsform
der Erfindung.
-
28 ist
ein Flussdiagramm, das eine Prozedur zum passiven Scannen von Artikeln
aufzeigt, bei welcher ein Benutzer nur dann alarmiert wird, wenn
festgelegte Kriterien erfüllt
sind, gemäß einer
Ausführungsform
der Erfindung.
-
29 ist ein Flussdiagramm für eine Prozedur zum Verwalten
von Verbrauchsgütern,
an denen MRL-Mittel angebracht sind, gemäß einer Ausführungsform
der Erfindung.
-
30 ist eine Darstellung einer intelligenten Waage
mit einem MRL-Lesegerät und einer
Benutzeroberfläche,
welche verwendet wird, um die Menge eines verbrauchbaren Artikels
zu aktualisieren, indem die verbleibende Menge in einer Datenbank
mit einem MRL, das mit ihm verknüpft
ist, in Einklang gebracht wird, gemäß einer Ausführungsform
der Erfindung.
-
AUSFÜHRLICHE
BESCHREIBUNG DER BEVORZUGTEN AUSFÜHRUNGSFORMEN
-
Es
wird auf 1 Bezug genommen; ein MRL-Mittel
T erhält
eine Anforderung von und überträgt Daten
zu einem tragbaren Lesegerät 100 oder
einem feststehenden Endgerät 120 mit
einer integrierten Lesevorrichtung. Es ist anzumerken, dass das
Lesegerät 100 in
ein anderes Gerät
integriert sein kann, wie etwa einen persönlichen digitalen Assistenten
(PDA) oder ein Mobiltelefon oder ein anderes Gerät. Bei einer Ausführungsform
ist das MRL-Mittel T ein Radiotransponder, welcher HF-Verbindungen 110 zu
den Lesegeräten 100/120 herstellt.
Die HF-Verbindungen 110 können kurzzeitige Verbindungen
gemäß einer
bekannten Transpondertechnik sein. Stattdessen können die Verbindungen 110 auch
eine Datenübertragung
darstellen, die irgendeinem Übertragungsverfahren
mit hoher Datendichte entspricht, einschließlich des Scannens von gedruckten Symbolen
wie etwa zweidimensionalen Strichcodes, des Kontaktlesens eines
Memory Tokens wie etwa eines iButton® oder
von Chipkarten, oder des Lesens eines Magnetstreifens auf einer
Oberfläche.
-
Das
spezielle Medium ist unabhängig
von einigen Aspekten der Erfindung.
-
Das
tragbare Lesegerät 100 und
das feststehende Endgerät 120 können mit
einem Netz oder dem Internet 130 über drahtlose Verbindungen
und/oder Drahtverbindungen 112 bzw. 114 verbunden
sein. Ebenfalls mit dem Netz/Internet 130 verbunden ist
ein oder sind mehrere Netzserver 140, welche durch kommerzielle Dienste
betrieben sein können.
Ein lokales Netz (Local Area Network, LAN) 160 ist über einen
LAN-Server 150 mit dem Netz/Internet 130 verbunden.
Das LAN 160 verbindet den LAN-Server 150 mit verschiedenen
Geräten,
darunter einem Computer 190, und verschiedenen intelligenten
Haushaltsgeräten 170-185,
darunter einem Fernsehempfänger 175,
einem Mikrowellenherd 180, einer Tischsäge 185 und einem Kühlschrank 170.
-
Die
intelligenten Haushaltsgeräte 170-185 sind
alle netzfähig,
was bedeutet, dass jedes von ihnen einen Mikroprozessor und wenigstens
eine Eingabe- oder Ausgabevorrichtung aufweist, um mit einem Benutzer zu
kommunizieren. Zum Beispiel kann die Tischsäge 185 über die
Möglichkeit
verfügen,
Software aus dem Internet zu empfangen, die es ihr ermöglicht,
ein Sicherheitsmerkmal zu implementieren, oder der Mikrowellenherd 180 kann
ein Terminal aufweisen, das eine Anzeige und eine Tastatur umfasst,
zum Anzeigen von Rezepten, die aus dem Internet heruntergeladen
wurden. Intelligente Haushaltsgeräte werden in der veröffentlichten
Literatur umfassend erörtert
und werden hier nicht noch ausführlicher
erläutert.
Jedes der intelligenten Haushaltsgeräte 170-185 kann
mit einem stationären
Lesegerät
(nicht separat dargestellt) ausgestattet sein, das in der Lage ist,
das MRL-Mittel T zu lesen. Daten können auch von dem tragbaren
Lesegerät 100 zu
einem Gerät
wie etwa einem Computer 190 mittels einer zeitweiligen
Drahtverbindung oder drahtlosen Verbindung 195, wie sie
zu Synchronisieren von Daten auf persönlichen digitalen Assistenten
und Notebook-Computern verwendet wird, übertragen werden. Wenn das
Lesegerät
eines intelligenten Haushaltsgeräts 170-185 oder Heimcomputers 190 ein
MRL-Mittel T liest,
kann es mit dem Benutzer in Reaktion auf Daten in dem MRL-Mittel und
auf verschiedene Daten, die auf dem LAN-Server 150, dem
Computer 190 oder auf dem Netzserver 140 gespeichert
sind, interagieren.
-
Es
wird auf 2 Bezug genommen; das MRL-Mittel
T kann an einem beliebigen Artikel angebracht sein, zum Beispiel
an einer Produktpackung 225. Stattdessen kann das MRL-Mittel
T auch an einer Regaleinheit oder einer Kiste (nicht dargestellt)
in der Nähe
der Produktpackung 225 befestigt sein. Das wesentliche Merkmal
ist, dass irgendeine physische oder abstrakte Verbindung zwischen
einem Artikel und einem MRL-Mittel
vorhanden ist. Ein Verbraucher, der auf das Produkt stößt, kann
das tragbare Lesege rät 100 nahe an
das MRL-Mittel T der Produktpackung 225 halten und das
Lesegerät 100 aktivieren,
um das MRL-Mittel T zu lesen. Daraufhin überträgt das MRL-Mittel T Daten,
die in dem MRL-Mittel T der Produktpackung 225 gespeichert
sind, zu dem Lesegerät 100.
Das Lesegerät 100 kann
dann die Daten, die es von dem MRL-Mittel T erlangt hat, zusammen
mit anderen Daten in seinem Speicher M über das Netz/Internet 130 zu
dem Netzserver 140 und/oder dem LAN-Server 150 übertragen.
Stattdessen kann auch ein Verbraucher oder Kassierer während des
Kaufs das MRL-Mittel T der Produktpackung 225 scannen,
indem er das feststehende Endgerät 120 auf
eine ähnliche
Art und Weise verwendet. Das feststehende Endgerät 120 kann dann die
Daten, die es von dem MRL-Mittel T erlangt hat, zusammen mit anderen
Daten, die in dem feststehenden Endgerät 120 oder, was wahrscheinlicher
ist, in einem über
das LAN/WAN 135 angeschlossenen Server (nicht dargestellt,
z.B. Server des Einzelhändlers)
gespeichert sind, über
das Netz/Internet 130 zu dem Netzserver 140 und/oder
dem LAN-Server 150 übertragen.
-
Es
ist anzumerken, dass, wenn ein MRL-Mittel mit mehreren Einheiten
verknüpft
ist, es praktischer sein kann, wenn es aus einem Abstand funktioniert.
Zum Beispiel würde
das tragbare Lesegerät
eines Käufers beim
Passieren einer Regaleinheit mit 40 Dosen, von denen jede mit einem
MRL-Mittel T versehen ist, einen Schwall von Daten empfangen. Wenn
jedoch ein einziges MRL-Mittel auf einem Regal für eine ganze Gruppe "sprechen" würde, wäre es zweckdienlich,
wenn das Lesegerät
des Käufers
Daten kontinuierlich und aus einer gewissen Entfernung empfangen
würde.
In einem solchen Falle kann die Programmierung des Lesegerätes ein
passives Scannen gestatten und einem Benutzerprofil ermöglichen
zu bestimmen, ob der Benutzer benachrichtigt werden sollte. Siehe
Erläuterung
in Bezug auf 28 weiter unten.
-
Es
wird nun auf 3 und 4 Bezug
genommen; ein MRL-Mittel T kann, außer an gekauften oder käuflich zu
erwerbenden Waren, auch an vielfältigen
anderen Artikeln angebracht sein. Zum Beispiel kann das MRL-Mittel
T an einer Seite eines Tickets 205 angebracht sein, wie
etwa eines Zug-, Kino-, Veranstaltungs-, Flugtickets oder Tickets
anderer Art. Stattdessen kann das Ticket auch ein Gutschein, eine
Quittung oder irgendeine andere Art von Artikel sein, der mit einer
Dienstleistung oder einem Produkt zusammenhängt. Auf dem Ticket, der Quittung
usw. 205 kann sich ein Text 210 befinden, der
zum Beispiel ein Werbeangebot erläutert, von welchem der Benutzer
profitieren kann, indem er das MRL-Mittel T scannt und dementsprechend
irgendeine Handlung ausführt.
Es wird auf 5 Bezug genommen; in ähnlicher
Weise kann an einem Werbemittel 215 wie etwa ei ner Plakattafel,
einem Poster, einer Werbung in einer Zeitschrift oder einem anderen
derartigen Medium ein MRL-Mittel T für denselben Zweck angebracht
sein.
-
Es
wird auf 1 und 6A Bezug
genommen; ein Prozess, welcher auf der Basis der Hardwareumgebung
von 1 implementiert sein kann, ermöglicht einem Benutzer, über ein
feststehendes Endgerät 120 oder
ein tragbares Lesegerät 100 gezielte
Werbeinformationen zu empfangen, zum Beispiel während des Einkaufens. Angenommen,
der Benutzer stößt zufällig auf
eine Auslage, eine Werbung oder ein käuflich zu erwerbendes Produkt
und ist daran interessiert, es zu kaufen oder mehr darüber zu erfahren.
Zum Beispiel könnte
das Objekt ein Filmplakat sein, und der Benutzer möchte ermitteln,
wo und wann der Film zu sehen ist, oder eine Rezension lesen. Oder
das Objekt kann zum Beispiel ein Lebensmittelprodukt sein, und der
Benutzer möchte
weitere ernährungswissenschaftliche
Informationen darüber
erhalten oder erfahren, wie es zubereitet werden kann. In Schritt
S1 scannt der Benutzer das MRL-Mittel T und bewirkt damit, dass
das Lesegerät 100/120 Daten
von dem MRL-Mittel T erfasst.
-
In
Schritt S2 kann eine Interaktion zwischen dem Lesegerät 100/120 und
dem LAN-Server 150 oder Netzserver 140 eingeleitet
werden, die mit der Übertragung
von Daten zum Netzserver 140 beginnt. Die übertragenen
Daten können
zum Beispiel Daten vom MRL-Mittel T sowie andere Informationen umfassen,
wobei die anderen Informationen zum Beispiel die Kennung des Benutzers
und/oder gewisse Profildaten, die den Benutzer charakterisieren,
beinhalten. In den Informationen vom MRL-Mittel T kann eine Netzadresse
enthalten sein, zu welcher das Lesegerät 100/120 eine
Verbindung herstellen kann, um den Informationsaustausch durchzuführen. In
Schritt S3 wird die Interaktion fortgesetzt, so wie es durch einen
Interaktionsprozess definiert ist, der auf dem Server 140 ausgeführt wird.
Die bei der Interaktion ausgetauschten Daten können Daten umfassen, die mit
den erfassten Daten im Zusammenhang stehen, ferner eine Benutzereingabe
S4 und/oder Daten, die auf dem Netzserver 140 gespeichert
sind. Im Allgemeinen ist es denkbar, dass die Interaktion gemäß einem
und mittels eines Client-Server-Prozesses durchgeführt wird,
zum Beispiel unter Verwendung von HDML (Handheld Device Markup Language),
einer Auszeichnungssprache für
kleine drahtlose Geräte,
oder von HTML (Hypertext Markup Language).
-
Profildaten,
die den Benutzer charakterisieren, können von den Servern 140/150 auf
verschiedene Weise erhalten werden. Das Lesegerät 100/120 kann
diese Informationen speichern. Stattdessen kann der Benutzer auch
eine eindeutige Kennung haben, welche zu Profildaten in Beziehung
steht, die auf dem Netzserver 140 gespeichert sind, der
dem Inhaber der Netzadresse gehört,
die in dem MRL-Mittel T gespeichert ist. Eine weitere Möglichkeit
besteht darin, dass die Profildaten auf einem Netzserver 140 eines
Dritten gespeichert sind, zu welchem der Besitzer des adressierten
Netzservers 140 in einer Beziehung steht.
-
Um
ein Beispiel eines Austausches anzugeben, stelle man sich vor, dass
ein Käufer
in einem Warenhaus ein Paar Tennisschuhe scannt. Das Lesegerät 100 des
Benutzers erfasst eine eindeutige Kennung von dem MRL-Mittel T,
eine eindeutige Kennung, die den Besitzer des Lesegerätes 100 angibt,
und eine Adresse, die dem Netzserver 140 entspricht. Das
Lesegerät 100 überträgt dann
diese Daten zu dem Netzserver 140. Der Netzserver 140 führt einen
Interaktionsprozess aus, welcher diese Daten empfängt, und
identifiziert einen Subprozess, welcher den empfangenen Daten entspricht.
Zum Beispiel könnte
der Netzserver 140 dem Hersteller der Tennisschuhe gehören. Der
Interaktionsprozess kann Informationen über das spezielle Paar von Tennisschuhen
nachschlagen, dessen MRL-Mittel
T der Benutzer gescannt hat, das Herstellungsdatum, den Stil, das
Geschäft,
zu welchem es versendet wurde, und so weiter. Der Interaktionsprozess
kann auch persönliche
Profilinformationen über
den Benutzer aus seiner eigenen internen Datenbank oder einem Abonnement bei
einer Datenbank eines Dritten, die auf einem weiteren Netzserver 140 gespeichert
ist, erfassen. Die persönlichen
Profilinformationen können
solche Daten enthalten, wie den Stil (zeitgemäß oder traditionell), Zugänglichkeit
für Teilnehmersport
und Sportarten, Farbpräferenzen
usw. Zu den Informationen über
das spezielle Paar Schuhe kann zum Beispiel gehören, dass sie von einer Partie
stammen, welche zurückgerufen
worden ist. Der Interaktionsprozess kann auch Informationen auslesen,
aus denen hervorgeht, dass die Qualität der Schuhe nicht mit früheren Kaufmustern
des Benutzers konsistent ist. Der Interaktionsprozess kann auch Informationen
auslesen, aus denen hervorgeht, dass der Benutzer andere Sportarten
als Tennis treibt. In Reaktion auf alle diese Daten kann der Interaktionsprozess
derart definiert sein, dass eine Upselling-(Hochverkaufs-) Empfehlung
generiert wird, indem ein Schuhtyp von höherer Qualität empfohlen
wird. Ferner kann der Interaktionsprozess so beschaffen sein, dass
eine Cross-Selling-(Kreuzverkaufs-) Werbung generiert wird, die den
Benutzer darauf hinweist, dass das spezielle Geschäft, an das
die Schuhe geliefert wurden, auch Tennisschläger verkauft (wobei die Überlegung,
die der Programmierung des Interaktionsprozesses zugrunde liegt, die
Schlussfolgerung ist, dass der Benutzer ein Neuling beim Tennis
ist und eventuell die Ausrüstung
benötigt).
-
Der
Interaktionsprozess kann ein sehr einfacher Prozess sein, der aus
der Erzeugung einer einzigen Nachricht besteht, die zum Beispiel
für ein
Produkt wirbt. Stattdessen kann der Interaktionsprozess auch ein Feedback
von dem Benutzer anfordern, wie in Schritt S4. Zum Beispiel kann
er ein Menü mit
einer Anzahl von Optionen zur Verfügung stellen, welches auf dem
Display des Lesegerätes 100/120 generiert
werden kann. Der Einfachheit halber kann dem Benutzer die Option
zur Verfügung
gestellt werden, sofort oder im Verlaufe des Dialogprozesses gewisse
Informationen oder sogar den gesamte Interaktionsprozess zwecks
späterer Durchsicht
und Vervollständigung
zu markieren. Stattdessen kann dem Benutzer auch die Option zur
Verfügung
gestellt werden, die Daten per E-Mail zu empfangen oder sie lokal
auf dem Lesegerät 100/120 speichern zu
lassen, zwecks späterer
Durchsicht und Interaktion, in der Weise, wie man gegenwärtig eine
HTML-Datei lokal speichern kann und mit Links innerhalb derselben
interagieren kann, wenn man verbunden ist. Nachdem das Lesegerät in Schritt
S4 die Eingabe akzeptiert, kann es eine Interaktion in Abhängigkeit
vom Eintreten von Scan-Ereignissen in einer Statusüberwachungs-Schleife
in S5 iterativ fortsetzen, bis sie abgeschlossen ist.
-
Es
wird nun auf 6B Bezug genommen; auf der Serverseite
beginnt die Interaktion in Schritt S55 mit dem Empfang von Daten
vom Lesegerät 100/120.
Der entsprechende Dialogprozess wird in Schritt S60 ausgewählt und
beginnt dementsprechend in Schritt S65. Die Daten, die in Schritt
S55 empfangen werden, können
Anweisungen vom Benutzer enthalten, wie etwa eine Präferenz,
dass irgendwelche Verkaufsinformationen an ihn per E-Mail zu senden
oder einfach zu verwerfen sind.
-
Eingaben
können
an Antworten unter Anwendung verschiedener Verfahren des Informationsabrufs angepasst
werden, die verwendet werden, um Suchtemplates an Informationsressourcen
wie etwa Dokumente oder Interaktionsprozesse anzupassen. Das Gebiet
des Informationsabrufs ist ein weites und in raschem Wachstum begriffenes
technisches Gebiet, dessen ausführliche
Erörterung
nicht Gegenstand der vorliegenden Beschreibung ist, außer in dem
hier angegebenen Umfang. Es ist anzumerken, dass der Begriff "Ressourcenabruf" besser geeignet
sein könnte,
um die Erfindung zu beschreiben, da die gewünschte Antwort möglicherweise
nicht einfach ein statisches Stück
Information ist, sondern ein Prozess, wie etwa eine Interaktion
mit dem Benutzer oder eine Steuerungsfunktion, wie sie etwa zum
Programmieren eines Mikrowellenherdes verwendet wird. Das WWW liefert
heutzutage reichlich Beispiele von Prozessen, welche durch Suchvorgänge abrufbar
sind, wie etwa Ausrüstungssteuerung,
Transaktion, Überwachung
usw., so dass auf diesen Punkt nicht näher eingegangen werden muss.
-
Bei
Strichcodelesern und RFID-Tag-Lesern nach dem bisherigen Stand der
Technik konzentriert sich der Prozess der Anpassung von in einem
Ressourcenraum gespeicherten Antworten an den Kontext eines Scan-Ereignisses
entweder auf den Artikel, an welchem der Strichcode oder das RFID-Tag
angebracht ist, oder auf das Gerät,
an welches der Leser angeschlossen ist. Anders ausgedrückt, in
keinem Falle offenbart sich die Fähigkeit eines Lesers, mehrere
Aufgaben auf der Basis der Kombination von Variablen auszuführen, welche
mindestens den Typ des Lesers und den Typ des Artikels, der durch
ein MRL-Mittel gekennzeichnet ist, umfassen. Diese Fähigkeit
kann als "Kontextvielseitigkeit" (Context Versatility)
bezeichnet werden. Es folgt eine repräsentative Liste von Beispielen
von Konzepten nach dem Stand der Technik. Bei den meisten von ihnen
wird eine Ressource wie etwa eine Website aufgerufen, und danach
ist es erforderlich, dass das Lesegerät durch einen Menübaum navigiert,
um zu dem gewünschten
Ergebnis zu gelangen.
- – Tragbare Strichcodeleser,
die verwendet werden, um ein Produkt zu bestellen, eine Wegbeschreibung
zu einem Geschäft
zu bekommen oder Reservierungen vorzunehmen, indem ein Strichcode
in einer Zeitschrift, Zeitung, Broschüre oder anderen gedruckten
Werbung gescannt wird.
- – Scannen
von Strichcodes in einem Katalog, um einen Online-"Warenkorb" zu füllen.
- – Einen
Strichcode scannen und sich weitere Informationen per E-Mail zukommen
lassen.
- – Soundtracks
von Filmen, Sport-Erinnerungsstücke
(Memorabilia) usw. anhand eines Strichcodes bestellen, der auf einen
Ticketabschnitt gedruckt ist.
- – Wettbewerbsfähige Preise
nach dem Scannen einer SKU (Bestandseinheit) erhalten oder Artikel
bestellen, die mit dem durch die SKU gekennzeichneten Artikel zusammenhängen.
- – Cue
Cat® – Ein Etikett
scannen, und ein Server verbindet einen Webbrowser direkt mit einer
Website, die dem Etikett entspricht. Keine Kontextsensibilität.
-
Die
obigen Beispiele sind alle vollständig von dem Strichcode, der
von einem Benutzer gescannt wurde, und von den Daten, die von ihm
eingegeben wurden (z.B. einem Menü), abhängig. Dies entspricht einfach der
automatischen Verlinkung eines End gerätes mit einer bestimmten Website.
Die nächsten
Beispiele gewährleisten
zwar eine Kontextsensibilität
in einem gewissen Sinne, da in jedem Falle von einem speziellen
Lesegerät
eine spezielle Antwort generiert wird. Doch dies sind Vorschläge, die "Luftschlösser" sind, oder Forschungsprojekte,
und die Arbeiten zu diesen Themen liefern ungenügende Informationen darüber, wie
die Ergebnisse erreicht werden könnten,
oder über
Kontextvielseitigkeit.
-
- – Den
Inhalt eines Kühlschranks
mit einem Kühlschrank-Lesegerät scannen,
um das Lebensmittel-Bestandsverzeichnis eines Haushalts zu aktualisieren.
- – Den
Inhalt von Schränken
in einer Küche
durch Scannen von RFID-Tags von Gegenständen wie Töpfen usw. bestimmen.
- – Eine
Kaffeetasse in eine Kaffeemaschine stellen, und die Kaffeemaschine
spielt die Musik und bereitet die spezielle Art von Kaffee zu, die
von dem Benutzer bevorzugt wird, der durch ein in die Tasse eingebautes
RFID-Tag bezeichnet ist.
- – Ein
System, welches Anweisungen für
ein Rezept gibt, während
der Benutzer nach dem Rezept zubereitet. Das System gibt Ratschläge zu Ersatzmöglichkeiten
auf der Basis von persönlichen
Präferenzen
des Benutzers oder der Verfügbarkeit
von Zutaten im Bestandsverzeichnis des Haushalts.
-
In
diesen Beispielen ist die Reaktion eines Systems nicht vom Inhalt
des MRL-Mittels abhängig,
sondern vom Typ des Lesegerätes.
Zum Beispiel würde
ein Küchenschrank-Lesegerät das Bestandsverzeichnis des
Haushalts aktualisieren, doch vermutlich würde ein Registrierkassen-Lesegerät einen
Kassenbon erzeugen und ein Konto belasten, wobei beide dasselbe
MRL-Mittel verwenden. Jedoch ist bei diesen Systemen nach dem Stand
der Technik die Reaktion des Lesegeräts durch seine Programmierung
vorherbestimmt. Ein gegebenes Lesegerät ist so programmiert, dass
es auf ein bestimmtes MRL-Mittel
auf eine bestimmte Art und Weise reagiert.
-
Es
werden nun die ökonomischen
Aspekte der Gewährleistung
einer größeren Vielseitigkeit
betrachtet. Ein Hersteller des Artikels, an welchem das MRL-Mittel
angebracht ist, würde
es unrentabel finden, so zu programmieren, dass Einzelantworten
für ungewöhnliche
Szenarien mit aufgenommen werden. Zum Beispiel würde sich ein Hersteller von
Cerealien wahrscheinlich nicht die Mühe machen, eine einmalige und
nützliche Antwort
für ein
Ereignis zu entwerfen, wie das Scannen einer Packung Cerealien mit
einem Tischsägen-Lesegerät. Die Anzahl
solcher Anforderungen würde
die Kosten der Erzeugung einer Einzelantwort für solch ein seltenes Ereignis
nicht rechtfertigen.
-
Die
Prozesse des Informationsabrufs nach dem Stand der Technik sind
Nischenprozesse, die für
ein bestimmtes MRL-Mittel oder einen bestimmten Strichcode und Typ
von Lesegeräten
bestimmt sind. Solche seltenen Ereignisse könnten jedoch einen großen Anteil
von Scan-Ereignissen umfassen, wenn von dem System intelligente
Antworten generiert würden.
Zum Beispiel, angenommen, dass der Benutzer in dem vorhergehenden
Beispiel eine Regaleinheit bauen wollte, auf der Schachteln mit
Cerealien abgestellt werden können?
Oder angenommen, der Benutzer aß gerade
Cerealien als Zwischenmahlzeit, während er in seiner Werkstatt
arbeitete? Im erstgenannten Falle sind Informationen in der Cerealienpackung
vorhanden, welche verwendet werden könnten, um eine Antwort maßzuschneidern,
nämlich,
dass die Cerealienpackung gewisse Abmessungen hat. Im zweiten Falle
sind Informationen im Typ des Lesegerätes enthalten, zum Beispiel
die Angabe, dass sich der Benutzer wahrscheinlich in einer Werkstatt
und nicht irgendwo anders befindet. Diese verborgenen Informationen
könnten
verwendet werden, um eine zweckdienliche Antwort auszuwählen. Im
ersten Falle könnte
der Tischsägen-Hersteller
eine genügend
große
Nachfrage nach Plänen
für Regaleinheiten
haben, damit es Sinn machen würde,
eine Anzahl von Plänen
zur Verfügung
zu stellen. Ebenso würde
ein Hersteller von Cerealien wahrscheinlich Informationen über Cerealien
(oder andere Produkte, die im Cross-Selling verkauft werden könnten) haben,
welche besonders wichtig für
Benutzer sind, die gern Cerealien als Zwischenmahlzeit zu sich nehmen.
-
Wie
oben erläutert
wurde, bringt es Vorteile, wenn man einen hohen Grad an Vielseitigkeit
gewährleistet.
Die Motivation dafür,
dies zu tun, besteht darin, dass ungewöhnliche Szenarien wie das Scannen
einer Cerealienpackung mit einem Lesegerät, das in eine Tischsäge eingebaut
ist, zu etwas Alltäglichem
werden könnten,
wenn nützliche
Ergebnisse erhalten werden könnten.
Zum Beispiel würden
Benutzer ein System eher anwenden, wenn seine Ergebnisse für sie sachdienlicher
wären,
wodurch sich die Wahrscheinlichkeit seiner Anwendung exponentiell
erhöhen
würde.
Die Verwendung verborgener Informationen ermöglicht dem System auch, automatisch
zu reagieren, wodurch die Notwendigkeit von Benutzereingaben (wie
etwa zum Navigieren durch Menüs)
vermieden wird oder die Notwendigkeit solcher Angaben zumindest
verringert wird. Außerdem können Lieferanten
von Inhalt für
Lesegeräte
die "verborgenen" Informationen in
Anforderungen von Informationen für ein gezieltes Marketing ausnutzen.
-
Zusätzlich zur
Verwendung des Kontextes, um eine große Anzahl von Optionen durch
Filterung zu reduzieren, ist mit der Erfindung auch beabsichtigt,
eine Infrastruktur zur Verfügung
zu stellen, die in der Lage ist, diese Art von Vielseitigkeit auf
eine wirtschaftliche Weise zu gewährleisten. Die Herangehensweise
besteht darin, bekannte Komponenten der Ressourcenabrufs-Technik
in einer neuartigen Kombination für das Abrufen von Ressourcen
in der Domäne
der MRL-Lesegeräte
zu verwenden. Auf den ersten Blick erscheint es seltsam, dass jemand
ein Tischsägen-Lesegerät herstellt,
sofern nicht eine attraktive Verwendung für MRL-Mittel in Verbindung
mit Tischsägen
gefunden werden könnte.
Die offensichtliche Herangehensweise gemäß dem Modell nach dem Stand
der Technik besteht darin, das Lesegerät so zu konzipieren, dass es
Anleitungen des Tischsägen-Herstellers
für verschiedene
Arten von Werkstücken
liefert, für
welche die Tischsäge
verwendet werden könnte,
oder dass es dasselbe für
den Cerealien-Hersteller tut. Ein Tischsägen-Hersteller könnte solche
Informationen zur Verfügung
stellen, wie die Art des Sägeblattes,
welches bei einem Teil aus Kunststoff verwendet werden kann, das
mit einem MRL-Mittel etikettiert ist, oder Anweisungen dazu, wie
ein Dado-Sägeblatt
einzusetzen und einzustellen ist. Dieses monolithische Modell, bei
welchem ein Hersteller oder Lieferant genau vorhersehen muss, wie
Produkte verwendet werden, um in Reaktion auf einen Scan nützliche
Ressourcen zur Verfügung
zu stellen, ist jedoch in hohem Maße begrenzt und unflexibel.
So ist etwa in dem Beispiel das Tischsägen-Lesegerät wahrscheinlich nicht in der
Lage, mit mehr als einer allgemeinen Antwort zu reagieren, die allein
auf dem MRL-Mittel
der Cerealienpackung basiert.
-
Es
wird auf 7 Bezug genommen; ein System
zum Herstellen der Verbindung zwischen Ressourcen und einem Lesegerät verwendet
Komponenten der modernen Technik des Informationsabrufs, um Flexibilität zu gewährleisten.
Ein Lesegerät 609 empfängt Daten
von einem MRL-Mittel T und sendet diese Daten zusammen mit einer
Kennung eines Benutzers (oder Benutzerprofil-Daten von einer Präferenzen-Datenressource 611)
und einer Kennung des Lesegerätes
an Suchmaschinen 603 und 607. Die Suchmaschine 607 ist so
programmiert, dass sie eine oder mehrere Ressourcenbanken durchsucht,
die symbolisch in 605 dargestellt sind, zum Beispiel eine
Ressourcenbank, die von dem Hersteller des mit dem MRL-Mittel gekennzeichneten Produktes
oder dem Hersteller des Lesegerätes 609 unterhalten
wird. Es wird angenommen, dass die Suchmaschine 607 so
programmiert ist, dass sie die angegebenen Eingabedaten akzeptiert,
und dass typische Formatierungsschritte angewendet werden, um eine
Anfrage zu formulieren und Ergebnisse zu erhalten, welche der Ausgang
zu einem Formatierer 613 sind. Dieser Typ von Suchprozess
ist im Wesentlichen derselbe wie bei den betrachteten Systemen nach
dem Stand der Technik.
-
Die
Suchmaschine 603 durchsucht das Internet 601.
Zum Beispiel könnte
die Suchmaschine 603 eine Suchmaschine wie Google® einbeziehen.
Die zum Suchen verwendete Anfrage wird vorzugsweise aus dem Inhalt
des MRL-Mittels T entweder direkt oder indirekt generiert. Wenn
zum Beispiel das MRL-Mittel nur eine Seriennummer enthält, kann
es für
irgendeinen Prozess (nicht dargestellt) erforderlich sein, sie auf
einem entfernten Server oder vielleicht in einer Datenbank im Lesegerät 609 nachzuschlagen,
um zu bestimmen, womit das MRL-Mittel verbunden ist. Stattdessen
kann das MRL-Mittel auch eine oder mehrere Charakterisierungen des
Artikels speichern, mit dem es verbunden ist. Zum Beispiel könnte es
das Etikett "Süße Frühstücks-Cerealien" und/oder "Cap'n Crunch®" enthalten. Sobald
die Art des in dem MRL-Mittel gekennzeichneten Artikels bestimmt
worden ist, kann er von der Suchmaschine 603 in eine Suchanfrage
einbezogen werden. Eine Charakterisierung des Lesegerätes kann
auf dieselbe Weise erfolgen. Das Lesegerät kann so programmiert sein, dass
es einen eindeutigen Kennungscode sowie eine Charakterisierung (oder
mehrere zur Auswahl stehende Charakterisierungen) von sich selbst
zum Zwecke des Formulierens einer Anfrage für eine Internet-Suchmaschine
zur Verfügung
stellt. Die Charakterisierung des Lesegerätes kann ebenfalls in die Anfrage
integriert sein. Dasselbe kann mit beliebigen Profildaten geschehen.
Zum Beispiel könnte
die Anfrage eine bestimmte Menge von Profildaten enthalten, welche
speziell für
Internetsuchen reserviert ist. Stattdessen können die Profildaten auch von
der Suchmaschine 603 für
die Internetsuche weggelassen werden. Die Anfrage kann ein Template
(Schablone) oder eine Menge von Templates für verschiedene mögliche Anfragen
verwenden, mit Platzhaltern für
die Charakterisierung des Lesegerätes und Platzhaltern für die Charakterisierung
des etikettierten Artikels. Zum Beispiel "Verwende [Lesegerät] mit [Artikel]" oder einfach "[Lesegerät] UND [Artikel]". Die von der Suchmaschine 603 gefundenen
Ergebnisse können
dann an den Formatierer 613 gesendet werden und zu einer
Ausgabe an das Lesegerät 609 über eine
in dieses eingebaute Benutzeroberfläche (UI) geordnet werden.
-
Es
ist anzumerken, dass der Begriff "Ressourcenbank" hier verwendet wird, um jede beliebige
Art von Datenraum zu kennzeichnen, welcher durch Computer adressierbar
ist, einschließlich
des World Wide Web, von Datenbanken, von Servern wie etwa News-Feeds,
Media-Feeds, mit Verbindungen über
Paketdienste und Wählvermittlungs dienste
wie etwa das Internet und reguläre
Telefon- und Mobiltelefondienste. Die Ressourcen in der Ressourcenbank
können
Daten oder Prozessobjekte sein, so dass die beim Durchsuchen des
Ressourcenraumes gefundenen Ressourcen die Einleitung eines Prozesses
zur Folge haben können,
wie etwa die automatische Steuerung eines entfernten Systems, die
automatische Einleitung oder Beendigung einer Transaktion wie etwa
einer Bankeinlage oder die Einleitung eines Dialoges mit einem Benutzer,
der das Lesegerät 609 verwendet.
Die Ressourcenbank kann von einer beliebigen Entität erstellt
und unterhalten werden und kann ein Conduit sein, wie etwa ein Web
Content Aggregator (Webinhalt-Sammler), welcher Ressourcen aus verschiedenen
Quellen kombiniert.
-
Das
System von 7 macht eine potentielle Unzulänglichkeit
deutlich. Die Internet-Suchmaschine 603 wird eine Anfrage
generieren, welche möglicherweise
zu eng gefasst ist, um aussagefähige
Ergebnisse zu liefern. Zum Beispiel gibt es eventuell wenig Ressourcen,
welche Text oder Meta-Tags mit "Cap'n Crunch®" und "Tischsäge" enthalten, oder
zumindest sind diese wahrscheinlich nur ein Bruchteil der Ressourcen,
welche potentiell von Bedeutung sein könnten. Es wird nun auf 8 Bezug
genommen; diesem Problem kann Rechnung getragen werden, indem eine
weitere Stufe im Prozess des Sammelns von Eingangsinformationen
vorgesehen wird. Bei der vorliegenden Ausführungsform werden Präferenzdaten
aus einem Präferenzspeicher 611,
MRL-Daten von einem MRL-Mittel T und Lesegerät-Daten von einem Lesegerät 609 erhalten,
wie in Verbindung mit der Ausführungsform
von 7 erläutert
wurde. Die charakterisierenden Begriffe werden jedoch durch ein
Begriffswörterbuch 607 gefiltert,
bevor sie von der Internet-Suchmaschine 603 in eine Anfrage
integriert werden. Das Begriffswörterbuch 607 stellt
Wörter
und Sätze
zur Verfügung,
welche irgendeine Beziehung zu kritischen Begriffen haben können, die
vom Lesegerät 609 geliefert
werden. Diese Beziehungen können
Synonyme sein, Hypernyme, Begriffe, die angegeben, wo oder wie ein
durch einen Suchbegriff charakterisiertes Ding normalerweise verwendet
wird, usw.
-
Die
Notwendigkeit des Wörterbuches 607 ergibt
sich daraus, dass der Benutzer in dem Szenarium der Verwendung eines
bestimmten Lesegerätes,
um einen bestimmten Artikel zu scannen, nicht in der Lage ist anzugeben,
was im Zusammenhang mit dem Artikel oder dem Lesegerät es ist,
was relevant ist. Wenn es zum Beispiel dem Benutzer darum ging,
mit der Tischsäge
eine Regaleinheit herzustellen, und die Cerealienpackung einfach äußere Abmessungen
für Artikel
lieferte, die darin abgestellt werden sollten, so würde der
Suchprozess zumindest dies aus den Umständen schließen. Daher kann die Ausführungsform
von 7 wesentlich verbessert werden, indem ein weiterer
Prozess hinzugefügt
wird, um Alternativbegriffe zu generieren, welche auf irgendeine
Weise mit den Begriffen verknüpft
sind, die das Lesegerät
und den Artikel, an welchem des MRL-Mittel angebracht ist, charakterisieren.
-
Ein
Beispiel eines Typs von Wörterbüchern, welcher
gegenwärtig
verwendet wird, um Suchanfragen ausgehend von einer eingegebenen
Suchanfrage zu formulieren, ist ein Synonym-Thesaurus. Für die vorliegende
Patentanmeldung wäre
ein Wörterbuch
am günstigsten,
welches die Arten von Beziehungen zwischen den Begriffen in einer
Anfrage zur Verfügung
stellt, welche es ermöglichen
können,
einen Kontext abzuleiten. Zum Beispiel kann der Begriff "Tischsäge" mit Oberbegriffen
(Hypernymen) wie "Werkzeug" oder mit seinen Teilen
wie "Sägeblatt" verknüpft sein,
oder mit Orten wie "Holzwarengeschäft" oder, allgemeiner, "Hobbyraum".
-
Ein
Beispiel eines Wörterbuches,
welches Begriffe zu anderen Begriffen in vielfältigen unterschiedlichen Dimensionen
in Beziehung setzt, ist WordNet, ein lexikalisches Wörterbuch,
das auf dem Gebiet der quantitativen Linguistik verwendet wird.
WordNet bringt Wörter
mit anderen Wörtern,
welche mit einem Subjekt-Wort zusammenhängen, entlang verschiedener
Dimensionen in Verbindung. Es liefert Hypernyme, Antonyme, Meronyme
(ein Meronym ist ein Wort, welches ein Teil eines gegebenen Wortes
bezeichnet), Holonyme (ein Holonym ist ein Wort, welches das Ganze
bezeichnet, von dem ein gegebenes Wort ein Teil ist), Attribute, Folgen,
Ursachen und andere Typen von verwandten Wörtern. Ein solches Wörterbuch
könnte
verwendet werden, um Alternativanfragen zu erzeugen, für welche
eine wesentlich höherer
Wahrscheinlichkeit bestehen würde,
dass sie unter gewissen Umständen,
wie etwa in dem Beispiel Tischsäge/Cerealienpackung,
nützliche
Ergebnisse liefern. Somit könnte
ein Wörterbuch
verwendet werden, welches Begriffe liefert, die einen Ort benennen,
wo sich ein Lesegerät
wahrscheinlich befindet. So könnte
der Suchprozess zum Beispiel "Tischsäge" mit "Keller" oder "Werkstatt" in Verbindung bringen,
als dem Ort, wo sich die Tischsäge
normalerweise befinden würde.
Da die Begriffe in vielen Fällen
sehr spezifisch mit einem Gegenstand identifiziert werden können, zum
Beispiel der konkreten Cerealienpackung, einschließlich ihres
Herstellungsdatums, der Art des Papiers, aus dem ihre Verpackung
hergestellt ist, und des auf der Verpackung aufgestempelten Verfallsdatums,
können die
zugehörigen
Informationen sehr präzise
sein. Somit kann ein "Wörterbuch" erzeugt werden,
das eine Anzahl von zusätzlichen
Begriffen liefert, wel che auf verschiedene Art und Weise mit Begriffen
verknüpft
sind, die unmittelbar aus dem Kontext generiert werden.
-
Zum
Beispiel können
die Beziehungen solcherart sein, wie:
- 1. wie
ein benannter Gegenstand verwendet wird,
- 2. wo ein benannter Gegenstand verwendet wird,
- 3. wann ein benannter Gegenstand verwendet wird,
- 4. die Sprache, die in einer Ziel-Stadt gesprochen wird,
- 5. physikalische Abmessungen eines bezeichneten Gegenstandes,
- 6. andere charakteristische Eigenschaften des benannten Gegenstandes,
usw.
-
Die
Liste ist bei Weitem nicht vollständig, sondern soll einfach
die Idee anhand von Beispielen veranschaulichen. Anstatt eine einzelne
Anfrage zu formulieren (oder mehrere auf der Basis von Synonymen
aus einem Thesaurus oder von Alternativbegriffen durch Stemming),
können
wesentliche Begriffe in der ursprünglichen Anfrage mittels eines
spezialisierten "Wörterbuches" selektiv erweitert
werden.
-
Der
Zweck des Wörterbuches 607 ist
es, die in einer Anfrage verfügbaren
Arten von Informationen auf der Basis von Substantiven, die den
Artikel charakterisieren, an welchem das MRL-Mittel angebracht ist,
des Lesegerätes,
von Begriffen, die Präferenzen
definieren, und beliebigen anderen Daten zu vervielfachen. Wie weiter
oben erwähnt,
können
jedoch viele verschiedene Arten von Informationen zu Beginn zur
Verfügung
gestellt werden, ohne dass ein separates Wörterbuch benötigt wird.
Zum Beispiel könnte
das MRL-Mittel T auf einen bestimmten Artikel mittels einer Datenressource
hinweisen, etwa einer Datenbank, die von dem Hersteller eines Artikels
unterhalten wird, an welchem das MRL-Mittel befestigt war. Diese
Datenbank kann eine Anzahl von Alternativbegriffen enthalten, welche
dazu dienen, den Gegenstand, die Orte, an denen er normalerweise
verwendet wird, Möglichkeiten,
wie er verwendet werden kann, seine physikalischen Abmessungen usw. zu
kennzeichnen. Das MRL-Mittel T könnte
diese Alternativbegriffe von Anfang an enthalten. Eine solche Gestaltung
setzt jedoch voraus, dass die Entität, welche Informationen über den
Artikel liefert, sich dafür
entschieden hat, sämtliche
Informationen über
den Artikel zur Verfügung
zu stellen, welche von Bedeutung sein könnten. Außerdem kann die Zusammenstellung
und die Aufrechterhaltung der Aktualität dieser Art von Daten zu mühsam sein,
sofern nicht ein wesentlicher Anreiz für die Entität mit Zugang zu den Daten besteht.
In manchen Fällen
ist dies praktisch unmöglich
(zum Beispiel der Standort eines tragbaren Lesegerätes zum
Zeitpunkt des Scans), und in der Praxis ist es wahrscheinlich sehr
schwierig, einfach weil nicht alle beteiligten Parteien (z.B. das
Feinkostgeschäft,
welches den Kartoffelsalat zubereitet hat) über die Ressourcen verfügen werden,
um sämtliche
erforderlichen Informationen zur Verfügung zu stellen. Die Alternative
besteht darin, dass das System über
ein allgemeines Wörterbuch
verfügt,
welches es verwenden kann, um beliebige Begriffe zu erweitern, und
die Ergebnisse auf der Basis der Qualität der erhaltenen Übereinstimmungen
filtert.
-
Es
folgt ein Beispiel, wie das Begriffswörterbuch helfen kann, einen
sinnvollen Kontext zuliefern. Wenn das Lesegerät 609 zu einem Zementtransporter
gehört
und die Anfrage das Lesegerät
als einen Zementtransporter kennzeichnet, kann das Begriffswörterbuch 607 ein
Hypernym für
den Zementtransporter liefern, indem er den Begriff "Fahrzeug" oder dessen standardisiertes Äquivalent
zurückgibt.
Bei einer Anfrage, in welcher eine Flasche Coke® mit
dem Lesegerät 609 eines
Zementtransporters gescannt wurde, ist es wahrscheinlicher, dass
in dem Ressourcenraum Antworten vorhanden sind, die zu Coke® und
Fahrzeugen gehören,
als dass er Cerealienpackungen und Zementtransporter enthält. Zum
Beispiel könnte
die Anfrage eine Antwort generieren, die angibt, wo das Produkt
in der Cerealienpackung gekauft werden kann. Nur um das Beispiel
zu vervollständigen,
kann man sich einen Arbeiter vorstellen, der auf seinem Weg zurück zu einem
Bahnhof einen Kasten Coca Cola® kaufen möchte, und
dass es für
ihn bequem ist zu halten, während
er sich in einem Zementtransporter befindet.
-
Wie
in dem System von 7 werden die Ausgänge der
beiden Suchmaschinen 603 und 607 einem gemeinsamen
Formatierer zugeführt,
zur Ausgabe über
eine Benutzeroberfläche
(UI) 615. Es ist anzumerken, dass die UI 615 ein
lokaler Prozess auf dem Lesegerät 609 oder
ein entfernter Prozess auf einem Server sein kann, und dasselbe
gilt für
den Formatierer 613. Es ist außerdem anzumerken, dass es
sich bei dem Begriffswörterbuch 607 um
mehrere separate Prozesse und nicht nur um einen handeln kann. Diese
können
lokale (in das Lesegerät 609 integrierte)
oder entfernte (durch das Lesegerät 609 adressierbare)
Prozesse sein. Vorzugsweise können
ein oder mehrere allgemeine Wörterbücher von
einem oder mehreren Diensteanbietern unterhalten werden.
-
Die
Eingabebegriffe können
Deskriptoren sein, die von den Autoren gewählt wurden und in MRL-Mittel oder
eine Datenbank, welche die MRL-Mittel-Kennung den Deskriptoren zuordnet,
integriert sind. In Situationen, in denen diese Deskriptoren nicht
im Voraus erweitert worden sind, werden sie vom Prozess des allgemeinen
Wörterbuches 607 gehandhabt.
Ein Beispiel für
seine Verwendung ist der Fall des Feinkostgeschäftes, das einen Kartoffelsalat
zubereitet. Die einzigen Informationen über den Artikel sind der Begriff "Kartoffelsalat", das Datum, an dem
er zubereitet wurde, das Datum, an dem die Kartoffeln gekocht wurden,
die Liste der Zutaten, das Gewicht der verkauften ursprünglichen
Menge und eine Kennung des Lieferanten, der ihn zubereitet und verkauft
hat. In diesem Falle sind die genaue Größe des Behälters, ein Ort, wo er normalerweise
zu finden ist (z.B. in einem Kühlschrank
oder in einem Speisesaal) und andere präzise Informationen über den
Artikel, das Lesegerät
oder andere Deskriptoren, welche in einer Anfrage erscheinen könnten, nicht
verfügbar.
Doch in solchen Fällen
kann für
solche Begriffe ein Wörterbuch,
das um die allgemein anerkannten Bedeutungen von Wörtern und
anderen Begriffen herum aufgebaut ist, verwendet werden, um die
Suchbegriffe zu erweitern.
-
Das
obige Beispiel eines Zementtransporters und eines Kastens Coke® mag
weit hergeholt erscheinen, doch eines der Ziele des erfindungsgemäßen Systems
ist es, einen Wert in seltenen Situationen bereitzustellen, für welche
es andernfalls zu teuer sein könnte,
Links zu bestimmten Ressourcen zu erzeugen. Wie bereits dargelegt,
können
solche seltenen Situationen einen erheblichen prozentualen Anteil
der Gelegenheiten ausmachen, bei denen das System verwendet wird.
Das Liefern aussagekräftiger
Antworten auf ungewöhnliche
Anfragen bringt einen synergistischen Nutzen. Es bedeutet, dass
Benutzer voraussehen können, dass
das System in den meisten Fällen
nützlich
ist, sogar dann, wenn die Umstände
nicht einem Muster entsprechen. Je öfter das System verwendet werden
kann, desto wahrscheinlicher wird der Benutzer es zu Hilfe nehmen,
wenn gewöhnlichere
Umstände
es erlauben. Es kann sich auch als unterhaltsam für einen
Benutzer erweisen, irgendeine ungeahnte Verbindung zwischen dem
Ort, wo er sich gegenwärtig
verbindet, dem, was er gerade tut, und irgendeinem mit einem MRL-Mittel
gekennzeichneten Gegenstand zu entdecken. Dies kann enorme Marketing-Chancen
erzeugen.
-
Eine
Möglichkeit,
wie der Suchprozess verbessert werden kann, besteht darin sicherzustellen,
dass Anfragen und die Indizes, die von den Suchmaschinen 603 und 607 verwendet
werden, die kanonische Form von Anfragebegriffen verwenden. Die
kanonischen Formen können
Stemming (Grundformenreduktion) und, falls erforderlich, das Ersetzen
durch einen ausgewählten
kanonischen Stammbegriff beinhalten, um vielfältige Synonyme des Wortstammes
zu ersetzen. Dies würde
mit Anfragebegriffen und beschreibendem Text (einschließlich von
Meta-Tags) in den Ressourcen geschehen. Dies ist in manchen Fällen möglicherweise
nicht erforderlich. Zum Beispiel kann ein Lesegerät stets
sich selbst unter Verwendung von standardmäßigen Begriffen und Varianten
charakterisie ren. Der Vorteil, wenn man gestattet, dass Ressourcen
auch andere Begriffe außer
standardisierten Begriffen verwenden, besteht darin, dass sie leichter
und von Personen mit einer geringeren technischen Versiertheit erzeugt
werden können.
Erzeuger von Ressourcen können
einfach deskriptive Sprache aus einer anderen Quelle ausleihen oder
sie ausarbeiten, ohne sich darum kümmern zu müssen, sie an ein Standardvokabular
anzupassen.
-
Es
wird nun auf 9 Bezug genommen; die UI 615 kann
ein Ergebnis von der Art anzeigen, wie es in einer Darstellung eines
Displays 642 angegeben ist. Es sind zwei Anzeigebereiche
dargestellt: ein erster Bereich 640 zum Anzeigen von Ergebnissen
aus der Suche mittels der Suchmaschine 607 und ein zweiter
Bereich 644, der Ergebnisse aus der Internetsuche mittels
der Suchmaschine 603 anzeigt. Im ersten Bereich 640 werden
Anweisungen zu Beginn eines automatischen Programmiervorgangs eines
Mikrowellenherdes angezeigt. Das Display 642 des Lesegerätes 609,
welches in den Mikrowellenherd eingebaut sein könnte, stellt ein Steuerelement 643 zur
Verfügung,
um den Kochvorgang zu beginnen, und ein weiteres Steuerelement 643, um
dem Benutzer zu ermöglichen,
das Fortsetzen des Kochens abzuwählen,
um zu einem Menü zu
gelangen, das weitere Optionen zur Verfügung stellt. Die reguläre Suchmaschine 607 hat
außerdem
ein Ergebnis zur Werbung für
einen Verkauf bei BuySmart und für
ein Cross-Selling eines anderen Produktes generiert, nämlich von
tiefgefrorenen Erbsen mit einem Bonusgutschein, welchen der Benutzer
auswählen
kann, um ihn per E-Mail oder auf irgendeine andere Weise zu erhalten.
Der zweite Bereich 644 enthält einen Bereich hoher Priorität 646 und
einen Bereich niedriger Priorität 648.
Suchtreffer, welche als Treffer von hoher Priorität angesehen
werden, zum Beispiel aufgrund des Konfidenzniveaus des Treffers,
das von den meisten Internet-Suchmaschinen
angegeben wird und verwendet wird, um die Rangfolge der Ergebnisse
festzulegen (z.B. TF*IDF), werden in dem Bereich hoher Priorität 646 angezeigt
und erweitert. Die Ergebnisse mit niedrigerer Rangordnung werden
in dem Bereich niedriger Priorität
angezeigt. Es können
auch andere Kriterien angewendet werden, um die Rangfolge der Ergebnisse
festzulegen, wie etwa das Vorhandensein eines Hinweises auf eine
Gesundheitswarnung in der Ressource.
-
Es
wird nun auf 10 Bezug genommen; die anspruchsvollste
Suchmaschinentechnik, die gegenwärtig
verfügbar
ist, verwendet die Verarbeitung natürlicher Sprache (Natural Language,
NL), um Suchanfragen, die von Benutzern generiert wurden, zu parsen.
Zum Beispiel kann ein Benutzer eine Suche formulieren, indem er
eine Frage in die Suchmaschine AskJeeves® eingibt.
Der von dem Benutzer eingegebene Satz wird ei nem Parsing unterzogen,
um die wichtigsten Begriffe zu ermitteln. Es können eine Substantivsatz-Identifizierung,
Stemming, Umwandlung in kanonische Begriffe usw. durchgeführt werden.
Anspruchsvollere Methoden können
eine bessere semantische Unterscheidung in der Suchanfrage ermöglichen.
Bei dem gegenwärtigen System
sind diese Methoden möglicherweise
in dem vorgeschalteten Prozess der Erzeugung eines Anfragevektors
nicht erforderlich, da das MRL-Mittel, das Lesegerät und das
Präferenzenmodell
des Benutzers so beschaffen sein können, dass die jeweiligen Begriffe,
die sie beisteuern, eindeutig "getagged" sind, um die Bedeutungen
der Begriffe anzuzeigen, die sie beisteuern. So kann zum Beispiel
das Lesegerät
sich selbst als ein Lesegerät
identifizieren, das an einer Tischsäge angebracht ist, und das
MRL als eine Kennung einer bestimmten Marke und Sorte von Cerealien,
die an einem bestimmten Tag an einem angegebenen Ort hergestellt
wurden, usw. Es ist anzumerken, dass, wie bereits an anderer Stelle
erwähnt,
diese Informationen jedoch einfach einer eindeutigen Kennung zugeordnet
sein können,
die in dem MRL-Mittel gespeichert ist. Daher besteht keine Notwendigkeit
einer Extraktion von Informationen unter Anwendung von NL-Methoden
zur Bestimmung der semantischen Struktur der Daten, die in der Anfrage
enthalten sind. Solche NL-Methoden können jedoch sehr nützlich sein,
um die semantischen Strukturen von unstrukturierten Antworten-Datenbanken
wie etwa dem WWW zu bestimmen.
-
Relativ
unstrukturierte Antworten-Datenbanken lassen sich wesentlich leichter
erzeugen und erweitern als hochstrukturierte. Dies kann entscheidend
für die
Entwicklung von reichhaltigen Datenressourcen sein, welche zu der
Vision einer Zukunft beitragen werden, in welcher Benutzer so ungefähr alles überall scannen können, um
Antworten zu erhalten, die sie wirklich schätzen. Tatsächlich können Beiträge von den Benutzern selbst
kommen, da Benutzer zum WWW beitragen. Da in manchen Fällen ein
Scan-Ereignis sehr gut vorhersagbar sein kann, zum Beispiel das
Scannen des MRL-Mittels eines Tiefkühlgerichtes mit dem Scanner
eines Mikrowellenherdes, ist es für manche Antworten unter solchen
Umständen
wünschenswert,
dass sie direkt abgerufen werden können, ohne dass eine Filterung
großer
Mengen von unstrukturierten Ressourcen durchgeführt werden muss. Somit ist
es wünschenswert,
das strukturierte Datenbanken Seite an Seite mit unstrukturierten
existieren, oder dass die Suchmechanismen, die zum Durchsuchen unstrukturierter
Ressourcen angewendet werden, vorhersagbare Ergebnisse liefern.
Zum Beispiel könnte
ein Hersteller eindeutige Metadaten auf seinen Websites platzieren,
welche gewissen MRL- und
Lesegerät-Daten
zugeordnet sind, um zu garantieren, dass der Suchprozess die ge wünschte Ressource
mit einem hohen Konfidenzniveau abruft (d.h., die gewünschte Antwort
wird relativ zu allen anderen hoch gewichtet, und es wird dadurch
garantiert, dass sie in der Shortlist der zurückgegebenen Ergebnisse enthalten
ist).
-
Die
Erfindung und Suchverfahren nach dem Stand der Technik können eine
bestimmte Ressource identifizieren und stets eine Angabe der Güte der Anpassung
generieren, d.h. ein Maß dafür, wie geeignet
die jeweilige Antwort für
die gegebene Menge von Eingabedaten ist. Die Antworte(en) wird (werden)
dann ausgehend davon ausgewählt,
welche die beste Anpassung an die Eingabedaten geliefert hat (haben).
Angenommen, die Eingabedaten enthalten ein Substantiv, welches den
Typ des Lesegerätes
charakterisiert (z.B. "Mikrowellenherd" oder "Zementtransporter"), und ein Substantiv,
welches den Gegenstand charakterisiert, zu dem das MRL-Mittel gehört (z.B. "Tiefkühlgericht" oder "Dose Motoröl"). Um ein einfaches
Beispiel zur Veranschaulichung anzugeben, könnte der Server des Informationsanbieters
beispielsweise drei Antworten haben, (1) eine für das Programmieren eines Mikrowellenherdes
für ein
Tiefkühlgericht,
(2) eine, die Anweisungen gibt, wie bei einem Zementtransporter Ölnachzufüllen ist,
und (3) eine, die Navigationshinweise gibt, wo Tiefkühlgerichte
gekauft werden können.
Jede Antwort hat ein entsprechendes Template, das einen Eingabevektor angibt,
der zu der jeweiligen Antwort passt. In diesem Beispiel könnte das
Template für
Antwort (1) [Lesegerät =
Mikrowellenherd, MRL-Mittel = Tiefkühlgericht] sein; das Template
für Antwort
(2) könnte
[Lesegerät
= Zementtransporter, HDRM-Mittel = Dose Motoröl] sein, und das Template für Antwort
[3] könnte
[Lesegerät
= Auto oder tragbares Lesegerät,
MRL-Mittel = Tiefkühlgericht]
sein. Die Faktoren des Templates könnten auch gewichtet sein (in
der Art eines Bayesschen Netzes). Ein Eingabevektor, der mit irgendeinem
dieser Templates perfekt übereinstimmt,
würde bewirken,
dass der Server des Informationsanbieters einen sehr hohen Wert
für die
Anpassungsgüte
("Konfidenz") für eine der
Antworten und einen niedrigen für
die anderen generiert. Ein Template, das nur mit einer Komponente
des Eingabevektors übereinstimmt,
würde zu
einer niedrigeren Bewertung führen.
Wenn keine andere Übereinstimmung
mit dieser niedrigeren Bewertung konkurrieren würde, könnte die entsprechende Antwort
von dem Server generiert werden. Die letztere Situation würde mehrere gute
Anpassungen zur Folge haben und könnte eine Anforderung weiterer
Informationen erfordern, um die korrekte Auswahl klarer zu treffen.
-
Die
obigen Beispiele sind trivial. In großen Datenbanken erfolgt die
Anpassung zwischen Eingabevektoren und Antworten möglicherweise
nicht mittels eines Templates mit Gewichtsfaktoren wie in einem
Bayesschen Netz (oder Neuralnetz oder bei einem anderen Maschinenintelligenz-Verfahren),
da es so zeitaufwendig ist, sie zu programmieren (zu "trainieren"). Ein praktischerer
Weg, eine Antworten-Datenbank zu erstellen, besteht darin, die Technologie
anzuwenden, die in Suchmaschinen- und Fragenbeantwortungssystemen
benutzt wird, wo die Kriterien für
die Auswahl und den Inhalt der Antworten Deskriptoren in natürlicher
Sprache sind. In Fragenbeantwortungssystemen (oder "Häufig gestellte Frage"; FAQ-Selektoren)
wird eine Frage in natürlicher
Sprache (Natural Language, NL) einem Parsing unterzogen, um die
wesentlichsten Begriffe zu identifizieren. Diese werden dann mit
Templates in der FAQ-Datenbank verglichen. Die Templates werden
aus den Fragen abgeleitet, welche von den entsprechenden Antworten
beantwortet werden. Eine Erweiterung dieser Technologie würde darin
bestehen, dass die Templates geordnete Mengen sind, wobei jedes
Element einem bestimmten Typ von Eingabe entspricht. Zum Beispiel
könnte
ein erstes Element dem "Wer" entsprechen und eine
oder mehrere Kennungen angeben, die sich auf die Art der Person
beziehen, welche eine Anfrage stellt, und wobei die Werte angeben:
männlicher
Erwachsener, weibliches Kind, ethnische Zugehörigkeit, Alter usw. Andere
Elemente könnten
dem Standort des Anfragenden entsprechen, zum Beispiel könnte ein
Wert angeben "in
einem Fahrzeug fahrend", "zu Hause", "auf Arbeit" usw. Ein anderes
Element bzw. andere Elemente könnten
sich auf den Typ des Lesegerätes
beziehen, das verwendet wird, wie etwa "Mikrowellenherd", "Tischsäge" oder "Verkaufsstand". Der Eingabevektor
könnte
auf dieselbe Weise geordnet sein. Eine Möglichkeit, um das Ordnen auszudrücken, besteht
im Data-Tagging, zum Beispiel unter Verwendung von XML.
-
In
der Praxis könnten
Prozesse zum Zuordnen von Eingaben zu Antworten unter Verwendung
von "Entweder-Oder"-Vergleichen zwischen
den Komponenten von Eingabe- und Template-Vektoren angewendet werden,
um Antworten in einem praktischen System recht effizient zuzuordnen,
selbst wenn die Anzahl der Kombinationen von Antworten und Eingaben
hoch sein kann. Gewöhnlich
würden
beim Programmieren eines solchen Systems viele Vektorkomponenten
ignoriert, wodurch sich die Größe des Eingabevektorraumes
verringert. Außerdem
kann der Anbieter die Arten von Anfragen, die zu empfangen sind,
klassifizieren und eine bestimmte Standardantwort vorsehen, wenn
kein Eingabevektor zu einem Antwort-Template passt. Es werde zum
Beispiel angenommen, dass der Informationsanbieter ein Hersteller
ist, welcher Informationen zur Verfügung stellt, um Käufer seiner
Produkte zu unterstützen.
Der Hersteller kann jede Anfrage, in der eines sei ner Produkte genannt
wird, einer entsprechenden Menge von Antworten zuordnen. Jede der
Antworten kann so erzeugt sein, dass sie auf ein bestimmtes Lesegerät zugeschnitten
ist, für
das erwartet wurde, dass es zum Scannen des angebrachten MRL-Mittels
verwendet wird. Zum Beispiel könnte
für Tiefkühlgerichte
die Lesegerät-Komponente
der Eingabe-Templates
verschiedene Modelle von Mikrowellenherden, gewöhnlichen Backöfen und
tragbaren Hand-Lesegeräten
beinhalten. Wenn das Produkt nicht zu einem der vorhergesehenen
Geräte
passt, die mit dem Lesegerät
verknüpft
sind, könnte
die Programmierung des Servers eine Standardantwort generieren.
-
In 10 ist
eine Konfiguration dargestellt, bei der auf der Ressourcenseite
des Systems ein Wörterbuch
verwendet wird. Ein MRL-Mittel 400 wird von einem Lesegerät 405 gelesen.
Das Lesegerät 405 speist relevante
Charakterisierungsbegriffe, die daraus resultieren, in einen Wörterbuch-Prozess 410 ein.
Der Wörterbuch-Prozess 410 generiert
alternative Begriffe, wie oben erläutert, und speist diese in
einen Ressourcensuchmaschinen-Prozess 425 ein. Der Ressourcensuchmaschinen-Prozess
kann optional allgemeine Daten 415 und Profildaten 430,
wie etwa Präferenzen
und charakteristische Eigenschaften, die den Benutzer betreffen,
empfangen. Der Ressourcensuchmaschinen-Prozess 425 generiert
anschließend
eine Menge von alternativen Suchanfragen, mit welchen er einen Index 435 durchsucht.
Der Index wird allgemein als ein Datenobjekt betrachtet, das Teil
des Suchmaschinen-Prozesses ist, ist hier jedoch separat dargestellt,
um die Erläuterung
der Ausführungsform
zu erleichtern.
-
Auf
der Ressourcenseite des Systems wird der Index durch eine Indexiermaschine 445 bestückt, welche
Ressourcen-Templates 460 durch einen Parser für natürliche Sprache 450 filtert.
Die Ressourcen-Templates 460 sind Deskriptoren der verschiedenen
Ressourcen, die in einer Ressourcenbank 455 verfügbar sind. In
Datenbanken können
diese Deskriptoren der Inhalt der Datenbank selbst sein, oder separate
Felder, die zum Suchen verwendet werden, wie Tags (z.B. XML), die
von manchen Ressourcenbanken wie WWW-Sites verwendet werden (z.B. Metatags).
Hier enthalten die Ressourcen-Templates 460 die Begriffe,
welche die Eintragungen in der Ressourcenbank 455 charakterisieren.
Die Templates sind nicht genau konfiguriert wie in einer normalen
Datenbank. Vielmehr können
die Ressourcen-Templates 460 einfach Textzusammenfassungen sein,
die den Inhalt der Ressource beschreiben. Stattdessen können die
Templates auch innerhalb der Eintragungen der Ressourcenbank 455 zusammengefasst
sein. Die Verwendung von Zusammenfassungen in natürlicher
Sprache als Templates (oder Template-Vorstufen, wenn die Zu sammenfassungen
einem Parsing unterzogen und danach als Templates strukturiert werden)
kann die Beisteuerung neuer Templates durch Benutzer erleichtern.
Diese Idee wird an anderer Stelle in der vorliegenden Patentbeschreibung
erörtert.
Siehe zum Beispiel Erörterung
im Zusammenhang mit 21.
-
Es
wird nun auf 11 Bezug genommen; bei einer
anderen Ausführungsform
werden aus einem Scan-Ereignis ein Benutzerzustand 235 und
ein Verwendungskontext abgeleitet. Der Benutzerzustand umfasst alle
verfügbaren
Informationen von dem Lesegerät,
welches ein tragbares Gerät
mit einem persönlichen Informationsplaner
sein kann, ein Mobiltelefon, ein GPS-Gerät mit einer Kartendatenbank,
welche die Aufenthaltsorte des Benutzers im Laufe der Zeit speichert,
usw. Das Lesegerät
(in 11 nicht dargestellt) kann mit anderen Geräten vernetzt
sein, so dass das Lesegerät
sogar in der Lage sein kann, seinen Standort zu bestimmen. Wenn
zum Beispiel ein tragbares Lesegerät in der Lage ist, sich zeitweilig
an ein Piconet anzuschließen
und zu ermitteln, dass es in ein Lebensmittelgeschäft gebracht
worden ist, könnte
das tragbare Lesegerät einen
Indikator dieses Ereignisses aufbewahren, zur Verwendung bei der
Bestimmung des aktuellen Zustands des Benutzers. In ähnlicher
Weise können
Informationen darüber,
mit wem sich der Benutzer in Kontakt befunden hat, in einer Vorrichtung
verfügbar
sein, die entweder mit dem Lesegerät kombiniert oder an das Lesegerät anschließbar ist.
Alle Informationen über
den Benutzerzustand, welche für
ein Scan-Ereignis von Bedeutung sind, werden in einen Internet-Suchprozess 233 eingespeist.
Permanente Präferenzdaten
können
in einem Präferenzdatenspeicher 237 gespeichert
sein, und ausgewählte
Teilmengen dieser Daten können
in den Internet-Suchprozess 233 eingespeist werden, um
ihn zu verfeinern. Dieselben Daten werden selektiv in eine Antworten-Datenbank-Suche 240 eingespeist.
Eine Antworten-Ressourcenbank 238 unterscheidet
sich von Sites im Internet dadurch, dass sie strukturiert ist, um
MRL-Lesegeräte
zu bedienen. Bei der vorliegenden Ausführungsform entsprechen Templates 241 der
Antworten-Ressourcenbank 238 Templates 460 in 10.
Diese enthalten Begriffe in gewöhnlicher
Sprache, welche zuvor einem Parsing durch einen NL-Parser unterzogen und
in die Templates, die den einzelnen Eintragungen entsprechen, eingebaut
worden sind. Die Templates 241 können somit geordnete Menge
von Daten sein, mit Feldern, welche wesentliche Merkmale der Antworten 239 angeben.
Ansonsten wird die Ressourcenbank 238 wie oben erläutert durchsucht.
-
Ein
anderes Merkmal der vorliegenden Ausführungsform ist, dass ein Wörterbuch,
das in einen Begriffserweiterungs-Prozess 245 integriert
ist, nur angewendet wird, um Anfragebegriffe zu erweitern, wenn
der Antworten-Datenbank-Suchprozess 240 ermittelt hat,
dass die Konfidenzniveaus der Ergebnisse alle niedrig sind. Dadurch
werden Rechenressourcen geschont, indem keine Suchen durchgeführt werden,
wenn eine direkte Verwendung der ursprünglichen Suchbegriffe ein Ergebnis
mit hoher Konfidenz liefern kann. Sowohl der Internet-Suchprozess 233 als
auch der Antworten-Datenbank-Suchprozess 240 generieren
jeweils eine Menge von Antworten 234 und 236,
jede mit einem entsprechenden Konfidenzniveau. Bei der vorliegenden
Ausführungsform
werden diese in einen Selektor-/Formatierer-Prozess 250 eingespeist,
um eine endgültige
ausgewählte
Menge 249 zu generieren, welche durch ein Benutzeroberflächen-Element 255 angezeigt
werden kann.
-
Die
Templates 241 können
auf eine beliebige gewünschte
Weise so strukturiert sein, dass die Genauigkeit von Übereinstimmungen
mit Anfragen reduziert und die Effizienz der Suche erhöht wird.
Außerdem
kann die Ausführungsform
von 11 dahingehend modifiziert werden, dass ein Begriffserweiterer
(Term Expander) 245 in den Internet-Suchprozess 233 integriert
wird.
-
Der
Präferenzdatenspeicher 237 (ebenso
wie die Profildaten 430, 8, die Präferenzen-Datenbank 611, 7,
und ähnliche
Komponenten in anderen Figuren) kann Daten enthalten, die durch
verschiedenartige Mittel erhalten wurden. Ein erster Typ einer Vorrichtung
zum Aufbau einer Präferenzen-Datenbank
ist vom Standpunkt des Benutzers aus eine passive Vorrichtung. Der
Benutzer nimmt lediglich auf normale Art und Weise eine Auswahl
vor (z.B. eine Menüauswahl
in einem Browser, der in ein Lesegerät eingebaut ist), und das System
baut nach und nach eine persönliche
Präferenzen-Datenbank
auf, indem es aus den Auswahlen ein Modell des Verhaltens des Benutzers
extrahiert. Danach verwendet es das Modell, um Vorhersagen darüber zu treffen,
was der Benutzer in Zukunft bevorzugen würde anzusehen, oder es zieht
Rückschlüsse, um
den Benutzer zu klassifizieren (z.B. ein Baseball-Fan oder ein Opernliebhaber).
Dieser Extraktionsprozess kann nach einfachen Algorithmen erfolgen,
wie etwa durch Ermitteln offensichtlicher Favoriten durch das Erkennen wiederholter
Anfragen nach demselben Objekt, oder er kann ein anspruchsvoller
Maschinen-Lernprozess sein, wie etwa ein Entscheidungsbaum-Verfahren
mit einer großen
Anzahl von Eingängen
(Freiheitsgraden). Solche Modelle suchen, allgemein ausgedrückt, nach
Mustern im Interaktionsverhalten des Benutzers (d.h. in der Interaktion
mit einer Benutzeroberfläche
zum Treffen einer Auswahl).
-
Ein
unkompliziertes und ziemlich robustes Verfahren zum Extrahieren
nützlicher
Informationen aus dem Verhaltensmuster des Benutzers besteht darin,
eine Tabelle von Merkmalswert-Zählern
zu generieren. Ein Beispiel eines Merkmals ist die "Tageszeit", und ein entsprechender
Wert könnte "Morgen" sein. Wenn eine Auswahl
getroffen wird, werden die Zähler
der Merkmalswerte, welche die gewählte Option charakterisieren, inkrementiert.
Gewöhnlich
hat eine gegebene Option viele Merkmalswerte. Es kann auch eine
Menge von negativen Optionen generiert werden, indem eine Teilmenge
von gleichzeitigen "Shows" ausgewählt wird,
gegenüber
denen die gewählte
Option bevorzugt wurde. Ihre jeweiligen Merkmalswert-Zähler werden
dann dekrementiert. Diese Daten werden zu einem Bayesschen Prediktor
gesendet, welcher die Zählwerte
als Gewichte für
Merkmals-Zählwerte
verwendet, die Kandidaten charakterisieren, um die Wahrscheinlichkeit
dafür vorherzusagen,
dass ein Kandidat von einem Benutzer bevorzugt wird. Dieser Typ
eines Profilierungs-Mechanismus wird in der am 04.02.2000 eingereichten
US-Patentanmeldung, Serien-Nr. 09/498,271, für BAYESIAN TV SHOW RECOMMENDER
beschrieben. Ein regelbasierender Empfehler (Recommender) in derselben
Klasse von Systemen, welche Profile passiv aus Beobachtungen des
Benutzerverhaltens erstellen, ist auch in der am 14.01.99 veröffentlichten
PCT-Anmeldung WO 99/01984 für
INTELLIGENT ELECTRONIC PROGRAM GUIDE beschrieben.
-
Ein
zweiter Typ von Vorrichtungen ist aktiver. Er ermöglicht dem
Benutzer, Vorlieben und Abneigungen mit Hilfe von Einstufungsmerkmalen
anzugeben. Diese können
eine Punktbewertung von Paaren "Merkmal-Wert" beinhalten (ein
Gewicht für
das Merkmal plus ein Wert; z.B. Gewicht = Wichtigkeit des Merkmals, und
Wert = der Wert der Bevorzugung oder Missbilligung), oder irgendeine
andere Festlegung von Regeln. Zum Beispiel kann der Benutzer über eine
Benutzeroberfläche
angeben, dass der Benutzer Dramen und Action-Filme bevorzugt, und
dass er nicht gern kocht. Diese Kriterien können dann angewendet werden,
um vorherzusagen, welche Alternative aus einer Menge von Alternativen
für den
Benutzer von Nutzen wäre.
-
Als
ein Beispiel des zweiten Typs von Systemen beschreibt eine EP-Anmeldung (
EP 0854645 A2 )
ein System, welches einem Benutzer die Möglichkeit gibt, allgemeine
Präferenzen
einzugeben, wie etwa eine bevorzugte Kategorie von Sendungen, zum
Beispiel Fernsehkomödien,
Spielfilmserien, alte Filme usw. Die Anmeldung beschreibt außerdem Präferenzen-Templates,
in welchen Präferenzen-Profile
ausgewählt
wer den können,
zum Beispiel eines für
Kinder im Alter von 10-12, ein anderes für weibliche Teenager, ein anderes
für Liebhaber
von Flugzeugen usw.
-
Ein
dritter Typ von Systemen ermöglicht
Benutzern, Ressourcen auf irgendeine Weise einzustufen. Zum Beispiel
ermöglicht
gegenwärtig
ein digitaler Videorecorder mit der Bezeichnung TIVO® Benutzern,
einer Sendung bis zu drei "Daumen
hoch" oder bis zu
drei "Daumen runter" zu geben. Diese
Information ist in gewisser Hinsicht ähnlich zu dem ersten Typ von
Systemen, mit der Ausnahme, dass es einen feineren Auflösungsgrad
für die
den Merkmal-Wert-Paaren gegebene Gewichtung, die erreicht werden
kann, ermöglicht,
und dass der Ausdruck des Benutzergeschmackes in diesem Kontext
expliziter ist. So kann zum Beispiel eine Benutzeroberfläche, die
bei der vorliegenden Erfindung verwendet wird, eine OK-Taste aufweisen,
um ein aktuelles Dialogfeld oder ein Anzeigeelement zu quittieren
und zu schließen.
Neben der OK-Taste könnte
die Benutzeroberfläche
eine "NICHT OK"-Taste aufweisen,
um dem Benutzer zu ermöglichen,
den Dialog zu schließen,
jedoch anzuzeigen, dass die Antwort nicht von Nutzen war.
-
Eine
PCT-Anmeldung (WO 97/4924 mit dem Titel "System and Method for Using Television
Schedule Information) ist ein Beispiel für den dritten Typ. Sie beschreibt
ein System, bei welchem ein Benutzer durch einen elektronischen
Programmführer
navigieren kann, der wie üblich
in Form eines Rasters angezeigt wird, und verschiedene Sendungen
auswählen
kann. An jeder Stelle kann er eine von verschiedenen beschriebenen
Aufgaben ausführen,
darunter Auswählen
einer Sendung zum Aufzeichnen oder Ansehen, Einstellen eines Erinnerungs-Services
(Reminders), um eine Sendung anzusehen, und Auswählen einer Sendung, um sie als
Favorit zu kennzeichnen. Das Kennzeichnen einer Sendung als Favorit
erfolgt vermutlich zu dem Zweck, um eine feste Regel zu implementieren,
wie etwa: "Immer
die Option anzeigen, diese Show zu sehen", oder um einen periodisch wiederkehrenden
Erinnerungs-Service zu implementieren. Der Zweck der Kennzeichnung von
Favoriten ist in der Anmeldung nicht klar beschrieben. Was jedoch
wichtiger ist, für
Zwecke der Schaffung einer Präferenzen-Datenbank
kann dem Benutzer, wenn er eine Sendung auswählt, um sie als Favorit zu kennzeichnen,
die Option zur Verfügung
gestellt werden, den Grund anzugeben, weshalb sie ein Favorit ist. Der
Grund wird auf dieselbe Art und Weise angegeben wie andere explizite
Kriterien: durch Definieren von allgemeinen Präferenzen. Der einzige Unterschied
zwischen diesem Typ von Eingabe und dem anderer Systeme, die sich
auf explizite Kriterien stützen,
besteht darin, wann die Kriterien eingegeben werden. Das vorliegende
System kann Profildaten unter Verwendung jedes beliebigen der oben
beschriebenen Verfahren aufbauen.
-
Profildaten
können
verwendet werden, um Anfragen zu modifizieren, wie oben erläutert. Jedoch
können
die Profildaten unter gewissen Umständen einen gespeicherten Zusammenhang
zwischen einem Typ von Scan-Ereignis und einer zu verwendenden Ressource
enthalten. Zum Beispiel könnte
ein Benutzer eine Antwort zum Programmieren eines Mikrowellenherdes
zum Auftauen von Speiseeis definieren. Die Verwendung des Profils
und die Suche nach Antworten sollte solchen Ressourcen ein hohes
Gewicht geben, die von dem Benutzer zur Verwendung unter klar definierten
Umständen
erzeugt wurden. Daher kann das Profil seine eigene Liste von Ressourcen
und Templates enthalten, welche verwendet werden, um eine Anfrage
zuzuordnen, was einem Durchsuchen einer externen Ressourcenbank
vorzuziehen ist.
-
Es
wird auf 12 Bezug genommen; eine Modifikation
des Prozesses von 6A ermöglicht einem Benutzer, Informationen über ein
feststehendes 120 oder tragbares Lesegerät 100 zu
empfangen, und falls sich der Benutzer dafür entscheidet, zu diesem Zeitpunkt
keine Antwort zu empfangen, oder falls das tragbare Lesegerät 100 nicht
in der Lage ist, eine Verbindung zum Server 140 herzustellen,
wird die Antwort verzögert und
später
fortgesetzt. Es wird angenommen, dass der Benutzer in Schritt S10
das MRL-Mittel T scannt und damit bewirkt, dass das Lesegerät 100/120 Daten
von dem MRL-Mittel T erfasst. In Schritt S12 bestimmt das Lesegerät 100/120,
ob es in der Lage ist, eine Verbindung zum Netz/Internet 130 herzustellen.
Wenn das Lesegerät 100/120 verbunden
ist, kann die Interaktion zwischen dem Lesegerät 100/120 und
dem LAN-Server 150 oder Netzserver 140 eingeleitet
werden, beginnend mit der Übertragung
von Daten zum Netzserver 140 in Schritt S16. Zum Beispiel
können
die übertragenen
Daten Daten vom MRL-Mittel T sowie andere Informationen umfassen,
wobei die anderen Informationen zum Beispiel die Kennung des Benutzers
und/oder gewisse Profildaten, die den Benutzer charakterisieren,
beinhalten. In den Informationen vom MRL-Mittel T kann eine Netzadresse
enthalten sein, zu welcher das Lesegerät 100/120 eine
Verbindung herstellen kann, um den Informationsaustausch durchzuführen. In
Schritt S20 wird die Interaktion fortgesetzt, so wie es durch den
Interaktionsprozess definiert ist, der auf dem Server 140 ausgeführt wird.
Die bei der Interaktion ausgetauschten Daten können Daten umfassen, die mit
den erfassten Daten im Zusammenhang stehen, ferner Benutzereingaben
und/oder Daten, die auf dem Netzserver 140 gespeichert
sind. Im Allgemeinen ist es denkbar, dass die Interaktion im Einklang
gemäß einem
und mittels eines Client-Server-Prozesses durchgeführt wird,
zum Beispiel unter Verwendung von HDML (Handheld Device Markup Language),
einer Auszeichnungssprache für kleine
drahtlose Geräte,
oder von HTML (Hypertext Markup Language).
-
Wenn
in Schritt S12 ermittelt wird, dass das Lesegerät 100/120 keine
Verbindung zu dem Server 140/150 herstellen kann,
kann das Lesegerät 100/120 in
Schritt S14 die erfassten Daten in seinem Speicher M speichern.
Optional kann das Lesegerät 100 in
Schritt S18 die Tatsache anzeigen, dass die Daten lokal gespeichert
werden können,
und in Schritt S22 eine Quittung anfordern. Die Quittung kann beinhalten,
dass dem Benutzer die Option zur Verfügung gestellt wird, die in
Schritt S20 gespeicherten Daten zu löschen.
-
In
Schritt S24 kann der Zustand des Lesegerätes 100 ermittelt
werden. Falls es verbunden ist und nicht verarbeitete gespeicherte
Daten enthält,
die von den Schritten S14, S18 und S22 stammen, geht die Steuerung an
Schritt S28 über,
wo die Interaktion oder ein anderer Interaktionsprozess, welcher
zuvor nicht stattgefunden hat, eingeleitet wird. Zu den Daten, die
in Schritt S50 zum Netzserver 140/150 übertragen
werden, kann die Zeit gehören,
die vergangen ist, seit das HMDR-Mittel T gescannt wurde. Daraus
kann der Interaktionsprozess bestimmen, ob es sinnvoll ist, den
Benutzer zu einem Verkaufsstand innerhalb des Geschäftes zu
dirigieren (falls seit dem Scan nur eine kurze Zeit vergangen ist).
Auch in diesem Falle kann der Interaktionsprozess ein anderes Routing
von Informationen vorsehen. Zum Beispiel könnte der Benutzer verlangen,
dass sachdienliche Nachrichten, Gutscheine usw. nach Möglichkeit
per E-Mail gesendet werden.
-
Der
Prozess von 12 sieht einen stationären schleifenförmigen Prozess
vor, wenn das Lesegerät 100/120 nichts
zu tun hat, wie in Schritt S24 angegeben ist, und die Rückkehr zu
Schritt S10, wenn ein Scan eingeleitet wird.
-
Es
wird nun auf 13 Bezug genommen; bei einem
beispielhaften Ablauf, welcher gemäß dem Prozess von 12 eintreten
kann, erfasst das Lesegerät 100/120 in
Schritt S40 Daten von dem MRL-Mittel T und sendet sie in Schritt
S42 an einen Informationsanbieter, welcher den Netzserver 140 programmiert
hat. Von einem Softwareprozess (Interaktionsprozess), der auf dem
Netzserver 140 ausgeführt
wird, wird eine Nachricht erzeugt, was den Empfang einer Nachricht
durch das Lesegerät 100/120 in
S46 zur Folge hat. Die Nachricht wird dann in S48 von dem Lesegerät 100/120 ausgegeben.
-
Die
Daten, die von dem Lesegerät 100/120 erfasst
werden, können
einfach eine eindeutige Kennung des Gerätes beinhalten, oder sie könnten standardisierte
Symbole enthalten, welche Produktcode, Seriennummer, Einzelhändler, zu
dem das Produkt versen det wurde, usw. angeben. Die letztgenannten
Daten können jedoch,
wie durch Klammern angegeben ist, aus einer eindeutigen Kennung
abgeleitet werden, wenn diese Kennungen in einer Datenbank des Informationsanbieters
zugeordnet sind. Die an den Informationsanbieter gesendeten Daten
können
das Datum des Scans, die Uhrzeit des Scans, die Kennung des Scanners
(oder der Person) und andere Informationen umfassen, die nicht aus
dem MRL-Mittel T
abgeleitet, aber verfügbar
sind. Die Kennung des Scanners kann eindeutig sein oder ein Code
für eine
Klassifizierung des Profils sein, oder sie kann auf ein bestimmtes
Profil hindeuten, ohne den Scanner explizit zu identifizieren. Auch
in diesem Falle könnten
die Profildaten auch von dem Lesegerät 100/120 gesendet
werden.
-
Es
wird nun auf 14 Bezug genommen; bei einem
anderen beispielhaften Ablauf werden Daten in S80 erfasst und in
S82 gespeichert. Zu einem späteren
Zeitpunkt wird das Lesegerät 100/120 verbunden
und überträgt in Reaktion
auf dieses Ereignis in S84 die Daten, die in S80 erfasst wurden,
an einen Informationsanbieter. Der Informationsanbieter sendet dann
in S86 eine Antwortnachricht an das Lesegerät 100/120.
Das Lesegerät 100/120 speichert
dann in S88 die Antwortnachricht. Später wird beim Eintreten irgendeines
Ereignisses, welches einem günstigen
Zeitpunkt für
eine Ausgabe entspricht, wobei das Ereignis des günstigen Zeitpunktes
durch irgendeinen Prozess bestimmt wird, wie etwa eine direkte Anforderung
durch einen Benutzer, die am Lesegerät 100/120 angezeigt
wird, die gespeicherte Nachricht in S90 ausgegeben. Das Lesegerät kann so
programmiert sein, dass es die Nachricht automatisch ausgibt, wenn
das Lesegerät 100/120 in
der Lage ist, eine Verbindung herzustellen (d.h. wenn das Lesegerät 100/120 bestimmt,
dass es verbunden ist).
-
Es
wird nun auf 15 Bezug genommen; ein weiterer
Ablauf beginnt in S30 mit der Erfassung der Daten des MRL-Mittels
T. Die Daten werden in S32 gespeichert. Zu irgendeinem späteren Zeitpunkt,
wenn das Lesegerät 100/120 verbunden
ist, werden die gespeicherten Daten in S34 an den Informationsanbieter
gesendet. Der Informationsanbieter sendet eine Nachricht, welche
in S36 empfangen wird und an das Lesegerät 100/120 gesendet
wird. Zu irgendeinem späteren
Zeitpunkt wird auf ein Ereignis hin, das anzeigt, dass ein günstiger
Zeitpunkt für
die verzögerte
Interaktion gegeben ist, in Schritt S38 die Nachricht ausgegeben,
um den Benutzer aufzufordern zu beginnen, mit dem Informationsanbieter
zu interagieren. Die Nachricht kann eine einfache Aufforderung sein,
oder sie kann irgendein Feedback auf der Basis der in S34 gesendeten
Daten anzeigen, wie etwa ein Menü mit
Optionen, die zu Beginn des Interaktionsprozesses definiert wurden.
-
Es
wird auf 16 Bezug genommen; ein weiterer
Ablauf beginnt in S70 mit der Erfassung der Daten des MRL-Mittels
T. Die Daten werden in S72 auf dem Lesegerät 100/120 gespeichert.
Danach, wenn das Lesegerät 100/120 verbunden
ist, stellt das Lesegerät 100/120 in
S74 eine Verbindung zum Netzserver 140 her und überträgt die gespeicherten
Daten. In S76 wird der Benutzer aufgefordert, eine Nachricht vom
Netzserver 140 anzunehmen, und bei Annahme wird in S78
die Nachricht gleichzeitig oder zu einem späteren Zeitpunkt zugestellt.
Es folgen verschiedene Beispiele zur Veranschaulichung.
-
Der
Dialog kann in einer späteren
Session in Reaktion auf eine E-Mail wie folgt stattfinden. Der Benutzer
gibt in S76 an, dass er zu einem späteren Zeitpunkt an der Interaktion
teilnehmen möchte,
die von dem Benutzer einzuleiten ist, indem er einen HTML-Link in
einer E-Mail-Nachricht wählt.
(Offensichtlich muss die Aufforderung nicht so kompliziert sein;
zum Beispiel kann dem Benutzer in 40 eine Auswahl präsentiert
werden, die mit dem Vermerk versehen ist: "Später
E-Mail-Benachrichtigung senden, um über <Produkt> zu erfahren.")
-
Der
Dialog kann später über eine
gezielte TV-Werbung oder eine interaktive TV-Session wie folgt stattfinden.
(Für die
Zwecke der vorliegenden Erfindung können diese im Wesentlichen
dieselben sein wie ein Endgerät,
das an das Internet angeschlossen ist, wobei ein Fernsehgerät mit Set-Top-Box
im Wesentlichen dazu äquivalent
ist.) Der Benutzer wählt
eine Option für
die Übermittlung
per TV, und das Stattfinden der Interaktion wird für einen
Zeitpunkt geplant, zu dem das Fernsehgerät des Benutzers eingeschaltet
ist (oder für
irgendeinen Zeitpunkt, der vom Benutzer gewählt wird). Andere Alternativen,
die S78 entsprechen, sind etwa, dass der Benutzer angibt, dass er
einen Telefonanruf der Vertriebsabteilung oder einen Vertreterbesuch
oder eine reguläre
Zusendung von Informationen per Post wünscht.
-
Es
ist anzumerken, dass der Prozess in S78 auf dem tragbaren Endgerät, auf einem
stationären
Gerät, etwa
einem Gerät,
das sich auf dem Gelände
eines Einzelhandelsgeschäftes
befindet, oder auf irgendeinem anderen Gerät ablaufen kann. Es wird auf 17 Bezug
genommen; die Bestimmung eines günstigen
Zeitpunktes für
das Beginnen oder Fortsetzen einer verzögerten Interaktion, das Liefern
von Informationen oder eine Transaktion kann mittels einer festen
Zeitverzögerung
S301, eines Ereignisses, das angibt, dass sich der Benutzer an einem
bestimmten Ort befindet oder mit einer vorgegebenen Tätigkeit
beschäftigt
ist S302, der Synchronisation eines tragbaren Lesegerätes mit
einem stationären
Endgerät
S303 oder einfach einer zufälligen
Zeit S304 erfolgen. Wenn irgendeines dieser Ereignisse S301, S302,
S303, S304 eintritt, wird in Schritt S310 eine Service-Anforderung
eingeleitet, und der Interaktionsprozess wird fortgesetzt bzw. begonnen.
Zum Beispiel kann der Benutzer auf ein Internetportal zugreifen
und die Nachricht in Reaktion auf das Einloggen oder das Cookie
des Benutzers, das mit den in S74 gesendeten Kennungsdaten verknüpft ist,
empfangen. Für gespeicherte
Daten, die einer verzögerten
Interaktion entsprechen, können
eine Zeit und ein Datum des Verfalls festgelegt werden, und es kann
bewirkt werden, dass sie nach Ablauf dieser Zeit verfallen S305.
In diesem Falle kann ein anderer Prozess ausgeführt werden S305, wie etwa,
dass dem Benutzer die Option zur Verfügung gestellt wird, die Interaktion
noch weiter zu verschieben, eine E-Mail-Nachricht zu senden usw.
Die Daten und die im Entstehen begriffene Interaktion können entweder
durch das Lesegerät 100/120 oder
durch den Netzserver 140 gelöscht werden.
-
Während bei
den obigen Ausführungsformen
die Erfindung im Hinblick auf den Informationsaustausch beschrieben
wurde, ist es denkbar, dass diese Austauschvorgänge auch Aktionen auslösen könnten. Zum
Beispiel könnte
ein Ergebnis des Interaktionsprozesses der Online-Kauf eines Produktes
sein. Außerdem
muss die Interaktion nicht unbedingt auf dem Lesegerät 100/120 erfolgen,
welches die Daten gesendet hat. Die Interaktion kann über eine
Verbindung zum Informationsanbieter stattfinden, die mittels eines
anderen Gerätes bereitgestellt
wird, wie etwa eines der Geräte 170-190.
Eine Methode, um die Interaktion über die anderen Geräte einzuleiten,
besteht im Scannen des MRL-Mittels T mit einem Scanner des Gerätes. Eine
andere kann im Synchronisieren des Lesegerätes 100 mit dem Gerät bestehen,
wobei zum Beispiel die in 34 empfangene Nachricht zusammen mit anderen
Daten, die benötigt
werden, um die Interaktion abzuschließen, falls dies entsprechend
dem Interaktionsprozess erforderlich ist, zu dem Gerät übermittelt
wird.
-
Es
wird auf 18 Bezug genommen; indem einige
der obigen Merkmale in eine Ausführungsform übernommen
werden, werden in Schritt S110 Scan- und andere Daten erfasst. Die
besten Übereinstimmungen in
einer oder mehreren Ressourcenbanken werden in Schritt S115 bestimmt.
Anschließend
wird in Schritt S120 bestimmt, ob das Konfidenzniveau eines oder
mehrerer Ergebnisse hoch ist. Falls keines der Ergebnisse ein hohes
Konfidenzniveau hat, werden in Schritt S140 neue Begriffe generiert,
wobei ein geeignetes Verfahren angewendet wird, wie etwa ein Wörterbuch
verwandter Begriffe, wie es oben beschrieben wurde, oder indem die
Suchanfrage durch Einholen neuer Informationen vom Benutzer eindeutig
gemacht wird. In diesem Falle kann die Identifizierung von Unterscheidungsmerkmalen
in den Suchergebnissen, die weiter unten in Verbindung mit 24 erör tert wird,
angewendet werden, um zusätzliches
Feedback vom Benutzer zu erhalten. Danach wird in Schritt S145 eine
neue Suche durchgeführ,
und die Ergebnisse werden in Schritt S150 auf hohe Konfidenz geprüft, so wie
in Schritt S120. Wenn die Ergebnisse erneut kein hohes Konfidenzniveau
aufweisen, wird eine Suche nach einer Übereinstimmung mit hoher Konfidenz
durchgeführt,
indem Begriffe in der Anfrage durch andere Begriffe ersetzt werden,
welche nicht unbedingt mit dem ersetzten Begriff verwandt sind.
Dies kann als eine "Jagd
nach einer entfernten Übereinstimmung" S156 beschrieben
werden. Wenn zum Beispiel die Cerealien mit einer Tischsäge gescannt
wurden, könnte
der Begriff "Tischsäge" durch eine Anzahl
von Alternativen ersetzt werden, die näher mit anderen Suchbegriffen
wie etwa "Cerealien" verwandt sind, selbst wenn
die Ersatzbegriffe möglicherweise
von dem ursprünglichen
Begriff entfernt sind. Solche Begriffe könnten eine Antwort mit hoher
Konfidenz erzeugen, wie sie etwa "Geschirrschrank" in der Kombination mit "Cerealien" erzeugen würde. Die
Suche mit einem oder mehreren Ersatzbegriffen bewirkt, wenn sie
erfolgreich ist S157, dass das Lesegerät in Schritt S159 den Benutzer
zu dem Artikel lenkt, der durch den Ersatzbegriff gekennzeichnet
ist. Falls die Suche nicht erfolgreich ist, kann eine allgemeine
Antwort S158 generiert werden. An allen oder an irgendwelchen Stellen
des Prozessablaufes von 18 kann
dem Benutzer die Option zur Verfügung gestellt
werden, aus der Suche nach einer Antwort auszusteigen, um dem Benutzer
zu ermöglichen,
in Schritt S155 eine neue Antwort und ein neues Antwort-Template
für die
zukünftige
Verwendung zu erzeugen. Zum Beispiel könnte der Benutzer in Schritt
S155 einen Mikrowellenherd so programmieren, dass er etwas erhitzt, für das das
System des Lesegerätes
keine spezielle Antwort in seiner Ressourcenbank hatte. Es ist anzumerken,
dass der obige Ablauf auch dahingehend modifiziert werden kann,
dass eine allgemeine Antwort S158 zusammen mit einer Nachricht ausgegeben
wird, die ein anderes Gerät
empfiehlt, wie in Schritt S159, oder dass dem Benutzer die Möglichkeit
gegeben wird, falls er es wünscht,
von Schritt S159 zu Schritt S158 überzugehen, indem geeignete
Steuerelemente auf der Benutzeroberfläche generiert werden.
-
Falls
in einem der Schritte S120 und S150 ermittelt wird, dass das Konfidenzniveau
eines oder mehrerer Ergebnisse hoch ist, bestimmt das System in
Schritt S125, ob eine einzige Antwort mit einem hohen Konfidenzniveau
vorhanden ist oder mehrere. Falls mehr als eine vorhanden ist, werden
in Schritt S130 die Alternativen dem Benutzer präsentiert, und die Steuerung
geht an Schritt S160 von 19 über. Falls
nur eine Antwort vorhanden ist, geht die Steuerung unmittelbar an
Schritt S160 von 19 über.
-
In
Schritt S160 wird die Präferenz
des Benutzers im Hinblick darauf, wie ein einziges dominierendes Ergebnis
gehandhabt werden soll, bestimmt. Manche Benutzer bevorzugen eventuell,
dass ein System automatisch eine Aktion durchführt, zum Beispiel um den Mikrowellenherd
zu programmieren, um Zeit zu sparen. Andere Benutzer, die sich weniger
um die Effizienz sorgen, könnten
es bevorzugen, den Prozess während
der gesamten Zeit zu steuern. Die Benutzer können in Abhängigkeit davon, wo sie sich
befinden, diese Option ändern.
Wenn der Benutzer zum Beispiel gerade einkauft, wünscht der
Benutzer möglicherweise
nicht, dass ihm Informationen sofort übermittelt werden, sondern
er zieht es vor, dass ihm die Option des Routings zum Beispiel per
E-Mail oder mit irgendeinem anderen Mittel zwecks späterer Durchsicht
oder Handhabung gegeben wird. Wenn beim Abfragen eines Benutzerprofildaten-Speichers
ermittelt wird, dass die direkte Antwort bevorzugt wird, wird in
Schritt S145 eine durch die Ressource definierte geeignete Aktion
implementiert. Dies kann einfach die sofortige Übermittlung von Informationen
zum Display eines Lesegerätes
sein.
-
Zwei
weitere Möglichkeiten
der Handhabung von Ressourcen sind in der Ausführungsform von 19 definiert
und werden von der Präferenz
des Benutzers diktiert (oder möglicherweise
von irgendwelchen anderen Mitteln, wie etwa dem Typ des Lesegerätes, der
Tageszeit, dem Standort des Lesegerätes, dem Typ der Ressource,
die übermittelt
wird, usw.). Eine besteht darin, dass manche Ressourcen, da sie
einer Prioritäts-Ausnahmeliste entsprechen,
unmittelbar implementiert werden sollten. Zum Beispiel kann der
Benutzer stark an gewissen Ergebnissen interessiert sein, wie etwa
an die Gesundheit betreffenden Warnhinweisen oder Neuigkeiten oder
Wetterwarnungen. In solchen Fällen
wünscht
der Benutzer eventuell, dass die Ressource übermittelt oder implementiert
wird. In Schritt S170 ist diese Art von Ausnahme implementiert.
Wenn die Ressource einer Ressource mit hoher Priorität oder einem
anderen Typ von Ausnahme entspricht, wird die Ressource in Schritt
S165 übermittelt
oder implementiert. Andernfalls wird in Schritt S180 dem Benutzer
die Option zur Verfügung
gestellt, die abgerufene Ressource zurückzustellen oder zu ignorieren
oder zu übermitteln
oder zu implementieren. Dieser letztgenannte Schritt S180 schließt das Erhalten
einer Eingabe vom Benutzer ein. Falls sich der Benutzer dafür entscheidet,
die Ressource zu ignorieren S185, endet der Prozess. Falls sich
der Benutzer dafür
entscheidet, die Ressource zu übermitteln
zu implementieren, wird in Schritt S165 die Aktion durchgeführt. Falls
sich der Benutzer dafür
entscheidet, die Übermittlung
oder Implementierung der Ressource aufzuschieben S175, kann die
Offline-Prozedur vorhergehen der Ausführungsformen implementiert werden,
die ein Warten auf das Eintreten eines günstigen Zeitpunktes S190 bewirkt,
bis entweder die Aktion durchgeführt
wird S165 oder irgendein Ereignis wie etwa der Ablauf des Lebenszeit-Timers
eintritt, woraufhin der Programmfaden (Thread) des Prozesses der
Abfrage und Übermittlung
von Ressourcen beendet wird S195.
-
Es
wird auf 20 Bezug genommen; ein Prozess
zum Erzeugen von Nachrichten auf der Benutzeroberfläche eines
Lesegerätes
bei Nichtvorhandensein von Scan-Ereignissen
beginnt mit der Erkennung der Anwesenheit eines Benutzers in Schritt
S405. Stattdessen kann auch die Schleife von 20 ununterbrochen oder
in bestimmten Zeitabständen
oder nach irgendeinem anderen Zeitplan durchlaufen werden. In Schritt S407
wird von dem Lesegerät
automatisch eine Ressource angefordert und eine Antwort empfangen.
Die Anforderung kann aus Präferenzdaten
des Benutzers generiert werden. In Schritt S410 wird die empfangene Ressource
mit den Präferenzdaten
des Benutzers verglichen und entweder zurückgewiesen, wobei in diesem Falle
die Steuerung an Schritt S405 übergeht,
oder ganz oder teilweise angenommen, wobei sie in diesem Falle in
Schritt S415 übermittelt
wird und die Steuerung an Schritt S405 zurückgegeben wird. Es ist anzumerken, dass
die Übermittlung
der Ressource die Einleitung der Interaktion oder irgendeines automatischen
Prozesses oder einfach die Übermittlung
von Informationen wie etwa einer Werbung umfassen kann.
-
Es
wird auf 21 Bezug genommen; eine Prozedur,
durch welche neue Ressourcen und Templates generiert werden können, beginnt
in Schritt S430 mit der Präsentation
eines oder mehrerer Ressourcen-Kandidaten für den Benutzer zwecks Auswahl.
Wenn der Benutzer zum Beispiel ein MRL-Mittel von Speiseeis mit einem
Mikrowellenherd-Lesegerät
scannt, könnte
der Server mit (für
den Benutzer) bedeutungslosen Antworten aufwarten, oder mit überhaupt
keinen. Siehe zum Beispiel Schritt S156 in 18. Dann
könnte
die vorliegende Prozedur aufgerufen werden, um dem Benutzer die
Gelegenheit zu geben, Programmieranweisungen für den Mikrowellenherd zu definieren.
Zum Beispiel kann der Benutzer Anweisungen zum Auftauen des Speiseeises
definieren (z.B. Leistungsniveau 50% und 60 Sekunden Einschaltdauer).
Wenn der Benutzer das nächste
Mal das Mikrowellenherd-Lesegerät
verwendet, um ein MRL-Mittel von Speiseeis zu scannen, könnte der
Server sofort mit Anweisungen zum Programmieren des Mikrowellenherdes
antworten. Außerdem
könnte der
Server die Anweisungen, die von einem Benutzer eingegeben wurden,
entweder optional oder automatisch anderen Benutzern zur Verfügung stel len.
In Schritt S433 akzeptiert der Benutzer entweder eine der Alternativen,
wobei in diesem Falle die angenommene Ressource als eine bevorzugte
Ressource für
die gegebenen Umstände
S460 implementiert und gespeichert wird, oder er weist sie alle
zurück.
Hierbei gibt der Benutzer ein Feedback, welches verwendet werden
kann, um, wie oben erläutert,
die Profildaten zu erweitern. In Schritt S435 wird eine Benutzeroberfläche generiert,
um dem Benutzer zu ermöglichen,
einen Ressourcentyp anzugeben, und eine Eingabe zu akzeptieren,
die diesen definiert. In Schritt S440 wird eine Benutzeroberfläche generiert,
um dem Benutzer zu ermöglichen,
irgendwelche erforderlichen Einzelheiten oder Parameter für die Ressource
anzugeben. Wenn zum Beispiel die Ressource ein Programm für einen
Mikrowellenherd ist, könnte der
Benutzer Zeit, Leistungsniveau usw. festlegen. In Schritt S445 werden
die eingegebenen Daten als eine neue Ressource und ein neues Template
gespeichert. In Schritt S450 wird der Profildatenspeicher mit der
neuen Ressource und dem neuen Template aktualisiert.
-
In
Schritt S455 werden die Ressource und das Template in einer externen
provisorischen Ressourcenbank gespeichert, um anderen Benutzern
zu ermöglichen,
sie zu verwenden. Die provisorische Ressourcenbank kann anders als
eine standardmäßige gehandhabt
werden, um eine absichtliche oder versehentliche Kontamination einer
in großem
Umfang verwendeten Ressourcenbank mit nutzlosen oder gefährlichen
Ressourcen zu vermeiden. Daher kann eine separate Ressourcenbank
für provisorische
Ressourcen und Antworten auf die Ressourcen, die von bezeichneten
Teilnehmern (die im Benutzerpräferenzen-Proftl
angegeben sind) gesammelt wurden, verfügbar gemacht werden, bevor
ein Administrator bestimmt, was mit ihnen geschehen soll.
-
Es
wird auf 22 Bezug genommen, die einen
Ablauf zum Bereitstellen verschiedener Merkmale unter Verwendung
eines Ticketabschnittes, eines Gutscheines, einer Quittung oder
eines anderen Papierdokumentes zeigt, an dem ein MRL-Mittel angebracht
ist. Wie im Zusammenhang mit 3 und 4 erwähnt wurde,
kann an einem Ticketabschnitt oder anderen Dokument ein MRL-Mittel
angebracht sein. Diese Dokumente oder Gutscheine können zum
Beispiel ein wertvolles Marketinginstrument darstellen. Ein Benutzer,
der einen Film ansieht, kann seinen Ticketabschnitt an einem Stand
scannen, der sich am Kino befindet, und den Film, den er gerade
gesehen hat, bewerten, mit dem Film zusammenhängende Waren kaufen und andere
Dinge tun. Obwohl vorgeschlagen worden ist, Strichcodes auf einem
Ticketabschnitt zu verwenden, um Benutzer mit Websites für den Kauf
von Waren zu verbinden, wird durch diesen Grad von Automatisierung
dem Benutzer lediglich die Notwendigkeit erspart, eine Webadresse
einzugeben. Die vorliegende Idee besteht darin, den Kauf oder die
Eingabe von Informationen in eine Präferenzen-Datenbank sehr einfach
und schnell zu gestalten. Es besteht eine wesentlich größere Wahrscheinlichkeit
eines Verkaufs, wenn einem Benutzer die Gelegenheit gegeben wird,
einen Filmsoundtrack sofort zu kaufen, wenn der Benutzer das Kino
verlässt
und die Musik noch frisch in Erinnerung hat. Je kleiner die Anzahl
der erforderlichen Schritte ist, desto wahrscheinlicher kommt es
zu einem Kauf. Bei einer Ausführungsform
der Erfindung ist ein MRL-Mittel an einem Ticketabschnitt angebracht.
Das Mittel kann eine Ressourcenadresse enthalten, bei welcher der
Filmsoundtrack gekauft werden kann. Außerdem enthält das Mittel eine ausreichende
Datendichte, um Konto-, Autorisations-, Versand- und Authentifizierungsinformationen
zuzuordnen oder zu speichern, um den Abschluss des Kaufs zu ermöglichen,
ohne von dem Benutzer irgendetwas anzufordern, außer der
Auswahl und Bestätigung
eines Artikels, der gekauft werden soll. Wenn ein Kinobesucher Tickets
unter Verwendung einer Kreditkarte kauft, kann das Konto zeitweilig
mit Daten auf dem MRL-Mittel auf dem Ticketabschnitt verknüpft werden.
Diese Daten können ferner
einen Bestellvorgang mit Präferenz-Informationen
verknüpfen,
die in der Benutzerprofil-Datenbank enthalten sind, und der Kauf
kann verwendet werden, um diese Datenbank zu vergrößern. Um
das Konto des Benutzers zu schützen,
kann für
die Verbindung zwischen dem Kreditkartenkonto des Benutzers und
den Ticketdaten eine bestimmte Ablauffrist vorgegeben sein, zum
Beispiel 2 Stunden nach dem Ende des Films oder anderen Ereignisses.
Als Anreiz für
den Benutzer, am Kino zu kaufen, kann dem Benutzer ein finanzieller
Anreiz gewährt
werden, wie etwa ein niedrigerer Preis bei seinem nächsten Ticketkauf,
ein Preisnachlass für
die bestellten Waren oder ein Werbegeschenk. Genau dieselben Funktionen
können über einen
Heimcomputer, der an das Internet angeschlossen ist, oder über ein
tragbares Endgerät
anstelle eines Terminals in einem Kiosk gewährleistet werden.
-
Die
Prozedur beginnt mit einem Registrierungsschritt S468, in welchem
ein Benutzer das Dokument erhalten kann, welches das MRL-Mittel
aufweist. Der Registrierungsprozess kann das Erhalten von Konto-, Autorisations-
und/oder Authentifizierungsinformationen von dem Benutzer, von einer
externen Quelle wie etwa einem eWallet, ATM-Netz oder Teilnehmernetz oder von einer
anderen Ressource beinhalten. Eine Kennung in dem an dem Dokument
angebrachten MRL wird dann in Schritt S470 mit dem Konto und den
erforderlichen Daten zum Ausführen
der Transaktion verknüpft.
Es ist anzumerken, dass in den Schritten S468 und S470 das Konto überhaupt
nichts mit Geld oder Kredit zu tun haben muss, sondern auch einfach
nur ein Konto zum Speichern persönlicher
Informationen sein kann, wie etwa von Präferenzen betreffs eines Gegenstandes wie
etwa von Filmen. Zum Beispiel könnte
ein Benutzer einen von einem Unterhaltungs-Service angebotenen Dienst
abonnieren, welcher einem Benutzer ermöglicht, ein privates Konto
zum Speichern seiner Präferenzen und
zum Verwenden dieser Präferenzen
für verschiedene
Dienste zu eröffnen,
als Gegenleistung für
die Erlaubnis des Benutzers, die Daten für Marketing-Zwecke zu verwenden. Zum Beispiel könnte der
Benutzer Filme einstufen, wenn er sie gesehen hat. Später, nachdem
er mehrere Filme eingestuft hat, könnte der Benutzer per E-Mail Empfehlungen
empfangen. Die Präferenzen
des Benutzers könnten
mit denen von Freunden kombiniert werden, um Empfehlungen für Treffen
von zwei oder mehr Freunden zu generieren, welche die Filme gemeinsam
ansehen.
-
In
Schritt S475 scannt der Benutzer sein Dokument an einem Endgerät, zum Beispiel
an einem Stand an einer Unterhaltungsstätte. In Schritt S480 wird der
Benutzer zu einer Eingabe aufgefordert, wie etwa zu einer Auswahl
eines Produktes für
den Kauf, einer Bewertung eines gerade besuchten Ereignisses usw.
Die Autorisationsinformation des Benutzers wird in Schritt S485
von einem Server verarbeitet, und es wird eine Antwort generiert,
welche die Aufforderung zu weiteren Anfragen, eine Verkaufsbestätigung usw.
enthalten kann. In Schritt S490 kann zu weiteren Transaktionen aufgerufen
werden, und es können
entsprechende Benutzeroberflächen-Elemente
generiert werden. In Schritt S480 ist vorzugsweise eine Authentifizierungsschritt
inbegriffen, um sicherzustellen, dass ein verlorenes Dokument nicht
von jemandem, der es gefunden hat, benutzt wird. Für die Verknüpfung in
Schritt S470 kann eine Lebenszeit (Time to Live, TTL) festgelegt
sein, so dass nach dem Ablauf irgendeines vorgegebenen Zeitintervalls
das Dokument und das MRL-Mittel nicht mehr verwendet werden können. Indem
eine Verknüpfung
zwischen dem Konto des Benutzers und dem eindeutigen Code des MRL-Mittels
hergestellt wird, können
Käufe und
andere Transaktionen, die eine Autorisation erfordern, schnell abgewickelt
werden. Der Registrierungsprozess in Schritt S468 ist analog zur
Erzeugung einer zeitweiligen Kreditkarte in dem MRL-Mittel. Wie
erwähnt,
ist es jedoch unter den meisten Umständen vorzuziehen, damit eine
Authentifizierungsanforderung zu verknüpfen, wie etwa durch biometrische
Merkmale oder die Eingabe einer persönlichen Identifikationsnummer
(PIN) oder eines persönlichen
Symbols.
-
Der
Registrierungsprozess, welcher ein Konto mit einem MRL eines Tickets
verknüpft,
kann in einer Wohnung über
das Internet durchgeführt
werden, bevor sich der Benutzer zu der Unterhaltungsstätte begibt. Gegenwärtig gibt
es Vorschläge,
die Systeme betreffen, in welchen ein Benutzer ein Ticket kaufen
und dieses mit einem Strichcode zu Hause mit einem Drucker ausdrucken
kann. Das Ticket wird dann im Kino gescannt, um den Benutzer zu
autorisieren. Dasselbe könnte
mit einem MRL-Mittel geschehen. Der Benutzer speichert eine Verknüpfung zwischen
einem Konto und einem MRL ("Formulare" können kostenlos
oder gegen eine nominelle Gebühr
verteilt werden), indem er das MRL zu Hause scannt und eine sichere
Transaktion durchführt. Die
Verknüpfung
mit dem Konto, welche es ermöglicht,
das Ticket für
Käufe zu
verwenden, kann eine Ausgabenbegrenzung festlegen. Ein Erziehungsberechtigter
könnte
ein Ticket vorbereiten und einem Kind geben, welches dem Kind ermöglicht,
den Film zu besuchen und begrenzte Einkäufe zu tätigen. Zum Beispiel könnte das
Kind im Kino eine Platte oder Leckereien kaufen und dabei das MRL
als ein zeitweiliges Zahlungsmittel mit Ausgabenbegrenzung verwenden.
-
Es
wird auf 23 Bezug genommen; sie zeigt
einen einfachen Prozess zum Empfangen von Empfehlungen in Reaktion
auf eine Identifizierung des Benutzers. Zum Beispiel kann ein Benutzer
in einem Kino oder einer anderen Unterhaltungsstätte oder auf einer Website
Empfehlungen erhalten, indem ein in Schritt S491 eine Kennung (und
Authentifizierungsdaten, falls erforderlich) eingibt. In Schritt
S493 verwendet der Benutzer ein Steuerelement, um eine Anforderung
für eine
Empfehlung zu generieren, zum Beispiel eine Empfehlung, die eine
spezielle Kategorie betrifft. In Schritt S495 generiert ein Serverprozess
eine Empfehlung und speichert Präferenzdaten
in einer Profildatenbank zwecks Verwendung bei der Verfeinerung
von Empfehlungen, Cross-Selling usw. In Schritt S497 zeigt das Endgerät die resultierenden
Empfehlungen an, empfängt
weitere Eingaben usw. Es ist anzumerken, dass sich der obige Prozess
auf Restaurants, Unterhaltungsstätten oder
beliebige Arten von Artikeln oder Dienstleistungen beziehen kann,
für welche
viele Wahlmöglichkeiten verfügbar sind.
-
Es
wird auf 24 Bezug genommen; sie zeigt
eine Prozedur zum Verfeinern von Suchergebnissen, welche Unterscheidungsmerkmale
("Diskriminanten") in den Suchergebnissen
identifiziert, wenn die gefundene Anzahl sehr groß ist. Der
Suchmaschinen-Prozess kann nach Unterscheidungsmerkmalen in der
Menge der zurückgegebenen
Datensätze
suchen und, anstatt einfach die zurückgegebenen Ergebnisse aufzulisten, dem
Benutzer eine Liste von Unterscheidungsmerkmalen anbieten, aus denen
e auswählen
kann. Das Unterscheidungsmerkmal kann zum Beispiel ein wichtiger
Begriff sein, welcher in einem kleinen Teil der gefundenen Ergebnisse
erscheint, in den anderen jedoch auffallend fehlt. Der Prozess kann
eine Anzahl derartiger Unterscheidungsmerkmale identifizieren und
sie alle dem Benutzer zur Auswahl aus ihnen anbieten.
-
Die
Identifizierung von Diskriminanten ist an und für sich eine gut ausgearbeitete
Technik. Eine sehr einfache Herangehensweise besteht darin, ein
Histogramm zu generieren, welches die Begriffe angibt, die in den
zurückgegebenen
Datensätzen
am häufigsten
erscheinen, und dem Benutzer zu ermöglichen, unter den Begriffen
mit der größten Häufigkeit
auszuwählen.
Eine andere besteht darin, nach dem gemeinsamen Vorkommen von Wörtern zu
suchen, die in der Anfrage nicht angegeben sind, welche jedoch in
Verbindung mit Wörtern
erscheinen, welche in der Anfrage angegeben wurden, unter der Annahme,
dass die Ersteren die Letzteren modifizieren, wenn sie nahe beieinander
erscheinen. Diese ersteren Begriffe würden dann als Optionen präsentiert,
aus denen auszuwählen
ist. Die Generierung der Statistiken, die benötigt werden, um diese Unterscheidungsmerkmale
zu identifizieren, erfolgt auf direkte Weise aus den Prozessen,
die von den Suchmaschinen angewendet werden. Suchmaschinen erzeugen
oder verwenden Indexdateien, welche die schnelle Generierung solcher
Statistiken ermöglichen.
-
Die
Unterscheidungsmerkmale können
mit verschiedenen Mitteln abgeleitet werden. Zum Beispiel kann unter
Verwendung der zurückgegebenen
Auswahlmenge ein Histogramm generiert werden, das die Häufigkeit
jedes Begriffes in der zurückgegebenen
Menge von Datensätzen
angibt. Jene Begriffe mit der höchsten Trefferquote
können
angezeigt werden, und dem Benutzer kann ermöglicht werden, einen oder mehrere
davon auszuwählen.
Es werde zum Beispiel angenommen, dass die Anfrage die Boolesche
Verknüpfung "Hund" und "Fell oder Haar" und "gekräuselt oder
gewellt" enthält und das
Ziel darin besteht, Informationen über eine bestimmte Rasse zu
finden. In dem Beispiel enthalten die von der Suche zurückgegebenen
Datensätze
Informationen über
verschiedene Rassen, wobei die meisten sich auf bestimmte Rassen
konzentrieren. Die Begriffe mit der größten Trefferhäufigkeit
können
gewisse Informationen liefern, welche, wenn dies vom Benutzer angegeben
wird, verwendet werden können,
um der Suchmaschine mitzuteilen, dass gewisse Klassen von Datensätzen nicht
gewünscht
werden und gewisse Klassen gewünscht
werden. So können
zum Beispiel gebräuchliche
Deskriptoren zurückgegeben
werden, wie etwa "klein", "groß", "dünn" und "schwer". Der Benutzer kann aus ihnen auswählen, um
zu helfen, die ausgewählten
Datensätze
auf eine Anzahl zu reduzieren, welche bequem gebrowst werden oder
einen gewünschten
Treffer erzeugen kann. Um diesen Prozess zu erweitern, kann die
Benutzeroberfläche
die Anzahl der Treffer in der ursprünglichen Menge, die An zahl,
welche aus der Kombination irgendeines der vorgeschlagenen Unterscheidungsmerkmale
mit der ursprünglichen
Anfrage resultieren würde,
und den Effekt von Kombinationen, wenn unter Verwendung der unterscheidenden
Begriffe eine neue Anfrage generiert wird, anzeigen. Als Beispiel
für den
Letzteren werde angenommen, dass die Anfrage "dünn
und klein" enthält. Die
Anzeige könnte
den Effekt zeigen, wenn die einzelnen Begriffe hinzugefügt werden.
Dies ist ähnlich
zu der Art und Weise, wie Folio Bound Views® von
der Folio Corporation funktioniert, wo, wenn eine Suchanfrage eingegeben
wird, die Anzahl der zurückgegebenen
Ergebnisse ständig
aktualisiert wird.
-
Ein
Problem bei solch einem einfachen Unterscheidungsmerkmal besteht
darin, dass solche Begriffe einfach mit den Begriffen in der ursprünglichen
Suchanfrage mitkommen können.
Anders ausgedrückt,
sie können
den meisten der zurückgegebenen
Ergebnisse gemeinsam sein und sich daher als unzureichende Unterscheidungsmerkmale
zwischen den Ergebnissen erweisen. Mehr wünschenswert sind Unterscheidungsmerkmale,
bei denen eine hohe Wahrscheinlichkeit besteht, dass sie die zurückgegebenen
Datensätze
zu einem großen
Teil aufteilen. Ein Weg, um bessere Unterscheidungsmerkmale zu ermitteln,
besteht darin, nach Fällen des
gemeinsamen Vorkommens von Wörtern
zu suchen, welche nicht in der ursprünglichen Anfrage enthalten sind,
welche jedoch in Verbindung mit jenen in der ursprünglichen
Anfrage erscheinen, woraus gefolgert werden kann, dass die Verbindung
eine Bedeutung besitzt. Die Verbindung kann zum Beispiel aus der
Nähe der Begriffe
beieinander gefolgert werden, oder durch grammatisches Parsing (z.B.
Ermitteln von Adjektiven, welche den Begriff der Suchanfrage modifizieren),
usw. Diejenigen Kandidaten für
Unterscheidungsmerkmale, welche mit der größten Häufigkeit erscheinen, könnten dann
dem Benutzer präsentiert
werden, und dem Benutzer könnte
ermöglicht
werden, aus ihnen auszuwählen.
-
Eine
Verfeinerung der beiden vorhergehenden Herangehensweisen besteht
darin, Unterscheidungsmerkmale auf der Basis der Fähigkeit
des jeweiligen Unterscheidungsmerkmals zu wählen, die zurückgegebene
Menge in eine kleine Anzahl von Teilmengen aufzuteilen. Ein Weg,
um dies zu realisieren, besteht darin, eine Menge von Kandidaten
für Unterscheidungsmerkmale
mit hoher Trefferzahl zu nehmen, so wie sie durch die Histogramm-Prozedur
abgeleitet werden, und zu bestimmen, welche von ihnen "wichtige" Begriffe sind (wobei
die Wichtigkeit zum Beispiel aus der Häufigkeit des Vorkommens in
dem Datensatz, der Verwendung in einem Titel usw. gefolgert wird),
welche in einem kleinen Prozentsatz der gefundenen Ergebnisse erscheinen,
in den anderen jedoch auffallend fehlen. Das heißt, in manchen Datensätzen ist
der Begriff wichtig, doch der Begriff erscheint nicht in sämtlichen
Datensätzen.
In dem obigen Beispiel der Hunderasse mit gekräuseltem Fell wäre der Name
der Rasse, auf welche sich der Datensatz bezieht, wichtig in Datensätze, welche
die Rasse betreffen, und er würde
in Datensätzen
fehlen, welche diese Rasse nicht betreffen. Die Suchmaschine könnte dann
eine Liste solcher Unterscheidungsmerkmale zeigen, von denen viele
Namen von Rassen beinhalten könnten.
-
Die
Prozedur von 24 beginnt mit einer großen Anzahl
von Ergebnissen mit niedrigem Konfidenzniveau, die in Schritt S310
von einem Suchprozess zurückgegeben
werden. In Schritt S315 werden in den Suchergebnissen Unterscheidungsmerkmale
ermittelt, und in Schritt S320 werden darunter jene ausgewählt, die für den Zustand
des Benutzers von Bedeutung sind. Falls es irgendwelche Unterscheidungsmerkmale
gibt, die als relevant ermittelt werden S325, wird dem Benutzer
in Schritt S330 eine Frage präsentiert,
in Schritt S335 wird eine Eingabe empfangen, und in Schritt S340
wird eine neue Anfrage generiert. Falls keine relevanten Unterscheidungsmerkmale
gefunden werden, kann der Versuch abgebrochen werden, oder es kann
ein Prozess mit intensiverer Interaktion des Benutzers auf der Basis
beliebiger Unterscheidungsmerkmale durchgeführt werden. Die Relevanz von
Unterscheidungsmerkmalen kann bestimmt werden, indem die Benutzerpräferenzen-Datenbank
konsultiert wird. Da Anfragen möglicherweise
nicht viel Information aus dem Präferenzenprofil enthalten, können die
Kandidaten für
Unterscheidungsmerkmale als ein Test der Profildatenbank verwendet
werden, um Profilinhalt zu ermitteln, welcher für die Suche relevant sein kann.
In diesem Kontext können lexikalische
Wörterbücher verwendet
werden, um Begriffe im Profil zu erweitern.
-
Es
wird auf 25 Bezug genommen; sie zeigt
eine Prozedur zum Verwenden eines Wörterbuches zum Erweitern von
Anfragebegriffen. In Schritt S345 werden ein oder mehrere Begriffe,
welche die Oberbegriffe eines Suchbegriffes oder von Suchbegriffen
sind, generiert und beim Generieren einer neuen Anfrage oder von
neuen Anfragen in Schritt S375 angewendet. In Schritt S350 werden
zur gleichen Zeit ein oder mehrere neue Begriffe "wo gefunden" generiert und beim
Generieren einer neuen Anfrage oder von neuen Anfragen in Schritt
S375 angewendet. In Schritt S355 werden zur gleichen Zeit ein oder
mehrere neue Begriffe "wie
verwendet" generiert
und beim Generieren einer neuen Anfrage oder von neuen Anfragen
in Schritt S375 angewendet. In Schritt S360 werden zur gleichen
Zeit ein oder mehrere neue Begriffe "Teile von" generiert und beim Generieren einer
neuen Anfrage oder von neuen Anfragen in Schritt S375 angewendet.
In Schritt S365 werden zur gleichen Zeit ein oder mehrere neue Begriffe "wann verwendet" generiert und beim
Generieren einer neuen Anfrage oder von neuen Anfragen in Schritt
S375 angewendet. In Schritt S370 werden zur gleichen Zeit ein oder
mehrere neue Begriffe "Merkmale
von" generiert und
beim Generieren einer neuen Anfrage oder von neuen Anfragen in Schritt
S375 angewendet. Diese verwandten Begriffe sind nur Beispiele für Zwecke
der Veranschaulichung. Es ist anzumerken, dass die Generierungsschritte
S345-S370 rekursiv sein können,
so dass zum Beispiel Oberbegriffe von Hypernymen oder Holonymen
von Begriffen "Merkmal
von" ebenso generiert werden
können.
Die Prozedur von 25 kann auf Begriffe angewendet
werden, welche das Lesegerät,
den mit dem MRL-Mittel verknüpften
Artikel oder andere Begriffe charakterisieren, wie durch die Prozedur
von 26 veranschaulicht wird. In Schritt S380 werden
Alternativbegriffe für
den Typ des Lesegerätes
generiert. In Schritt S385 werden Alternativbegriffe für den Typ
des Artikels oder Ereignisses, das durch das MRL-Mittel gekennzeichnet
ist, generiert. In Schritt S386 können andere Begriffe auf dieselbe
Weise erweitert werden. Alle Erweiterungen können in Schritt S390 verwendet
werden, um Alternativanfragen zu generieren.
-
Es
wird auf 27 Bezug genommen; eine Benutzeroberfläche, welche
verwendet werden kann, um bestimmte Arten von Scan-Anforderungen
einzugeben, enthält
Steuerelemente zum Anzeigen verschiedener Skalen, anhand welcher
ein Arikel, Ereignis oder anderes Ding charakterisiert werden kann.
Zum Beispiel können
Lebensmittelgeschäfte
anhand einer Frische-Skala charakterisiert werden, auf welcher getrocknete
Waren niedrig und frische Produkte der Saison am höchsten eingestuft
würden,
und Tiefkühlgerichte
irgendwo in der Mitte. Ein Drehfeld-Steuerelement mit Drehknöpfen "nach oben" und "nach unten" 305 und 307 kann
verwendet werden, um den Typ der Änderung gegenüber einem
gescannten Beispielartikel anzugeben. Somit würde ein Benutzer das MRL-Mittel
eines Artikels scannen und dann sein Interesse an etwas angeben,
das ähnlich
ist, aber frischer (oder billiger, oder einfacher zuzubereiten,
oder gesünder).
Ein Modussteuerelement 300 kann verwendet werden, um zyklisch
zwischen verschiedenen Skalen umzuschalten, wie etwa Frische 310,
Kosten 315, Einfachheit der Zubereitung 320 und
Gesundheit 325. Das Lesegerät oder der Dienst, mit dem
es verbunden ist, kann die Skalen auf der Basis des Produkt- oder
Ereignistyps wählen,
dessen MRL-Mittel gescannt wird. Zum Beispiel könnte das MRL-Mittel eines Filmes
eine Menge von Skalen liefern, zu denen "gruselig", "Action", "unbeschwert" usw. gehören würde, während ein
Produkt aus einem Lebensmittelgeschäft solche Skalen erzeugen würde, wie
sie in 27 dargestellt sind. Die Skalen
können mehrere
Schichten aufweisen; zum Beispiel ermöglicht eine Schicht 325 unter
der Gesundheits-Skala dem Benutzer, detailliertere Merkmale zu ändern, zum
Beispiel den Salzgehalt 340, den Fettgehalt 335 und
den Fasergehalt 330. Es ist anzumerken, dass die Skalen
der unteren Ebene als Teil einer Profilerzeugung geändert werden
könnten,
so dass der Benutzer eine persönliche
Definition dafür
erzeugen würde,
was zum Beispiel Gesundheit ausmacht.
-
28 zeigt
eine Prozedur, die dazu dient, aus Scans resultierende Ausgänge nur
dann zu generieren, wenn vordefinierte Kriterien erfüllt sind.
Der Benutzer kann dieses Merkmal ein- oder ausschalten. Wenn ein
Benutzer einen Artikel scannt und dieser nicht in irgendeiner vordefinierten
Weise mit den Kriterien übereinstimmt,
wird eine Null-Anzeige
oder keine Anzeige generiert. Die Idee besteht hier darin, dass
das tragbare Lesegerät
eines Benutzers als ein Mittel wirken kann, das den Benutzer nur
dann behelligt, wenn der Benutzer in die Nähe eines Artikels kommt, den
der Benutzer interessant finden würde. Die Konfiguration kann
eine Fähigkeit
erfordern, Artikel aus einer beträchtlichen Entfernung zu scannen,
so dass der Benutzer nichts zu tun braucht, um eine Reaktion zu
erhalten. MRL-Mittel können
von einzelnen Objekten getrogen werden, und das vorliegende System
kann verwendet werden, um dem Benutzer einige sachdienliche Informationen über die vorhandenen
Objekte anzuzeigen, wenn die gewisse Kriterien erfüllen. Beginnend
in Schritt S270, scannt das Lesegerät passiv MRL-Mittel in seiner
Nachbarschaft. In Schritt S272 vergleicht es sie der Reihe nach
mit einem Kriterienprofil. Falls in Schritt S274 eine Übereinstimmung
vorhanden ist, wird in Schritt S276 ein Signal generiert, um dieses
Ergebnis dem Benutzer anzuzeigen. Das Signal kann eine Ausgabe auf
ein Display oder eine akustische Ausgabe beinhalten, die Einzelheiten
darüber
angibt, was die Übereinstimmung
ausgelöst
hat. Wenn keine Übereinstimmung
ermittelt wird, werden in Schritt S270 erneut MRL-Mittel gescannt.
Ein beispielhaftes Szenarium kann wie folgt beschrieben werden.
Ein Käufer
ist ein Gartenbau-Liebhaber, wie aus seinem Profil klar hervorgeht.
Während
der Käufer
in einem Geschäft
für Haushaltgeräte an einer
Gruppe von Kühlschränken vorbeigeht, übermittelt
sein Lesegerät
ihm Informationen über
einen Kühlschrank,
an dem er gerade vorbeigegangen ist. Die Informationen enthalten
eine Beschreibung eines Merkmals des Kühlschranks, welches es ermöglicht,
unter Ausnutzung der sanften Wärme
vom Kondensator des Kühlschranks
auf der Oberseite des Kühlschranks
Setzlinge aufzuziehen.
-
Es
wird auf 29 Bezug genommen; wie oben
erläutert,
ist es wünschenswert,
dass es möglichst wenige
Ausnahmen unter den Typen von Artikeln gibt, für welche das MRL-System verwendet
werden kann. Zum Beispiel würde
es davon abhalten, ein automatisiertes System zur Führung eines
Lebensmittel-Bestandsverzeichnisses anzuwenden, wenn einige Dinge
in dem Lebensmittel-Bestandsverzeichnis nicht automatisch aktualisiert
werden könnten.
Verbrauchsgüter
könnten
in dieser Hinsicht ein Problem sein, da MRL-Mittel möglicherweise zu dem Zeitpunkt
und an dem Ort der Zubereitung eines Verbrauchsgutes, zum Beispiel
einer Schüssel
Kartoffelsalat, nicht programmierbar sind. Beginnend mit einem Registrierungsschritt
S605, werden ein vorprogrammiertes MRL-Mittel, das eine eindeutige Kennung
besitzt, und Informationen, welche das Verbrauchsgut kennzeichnen
und charakterisieren, einschließlich
einer anfänglichen
Menge, in Schritt S610 gespeichert. Danach, wenn ein Scan-Ereignis
eintritt S615, empfängt
der Benutzer eine Antwort oder Antworten in irgendeiner der oben
beschriebenen Weisen, wie jeweils anwendbar. Dem Benutzer wird in
Schritt S620 die Option zur Verfügung
gestellt, die Menge zu aktualisieren. Wenn sich der Benutzer dafür entscheidet,
dies zu tun, aktualisiert der Benutzer in Schritt S625 die Mengenangabe,
welche dann in der Zuordnungs-Ressource oder Datenbank gespeichert
wird. Wenn das Verbrauchsgut vollständig verbraucht worden ist
oder irgendein Lebenszeit-Parameter abläuft (z.B. wenn der Kartoffelsalat
so lange aufbewahrt worden ist, dass er für den Verzehr ungeeignet geworden
ist) S626, wird der Programmfaden gelöscht, und die Daten (Zuordnung)
entfernt. Es ist anzumerken, dass die obige Prozedur auch auf Artikel
angewendet werden kann, deren Bedingungen sich im Laufe der Zeit ändern, anstatt
auf Artikel, welche verbraucht werden. Zum Beispiel kann sich eine Tomatenpflanze
im Laufe der Zeit verändern
und dabei den Lebensmittelbestand erhöhen. Außerdem können die Artikel auch andere
Dinge als Lebensmittel sein, wie etwa Holz (z. B. verbliebene Bretter
in Metern), oder Nägel
in Kilogramm. Weiterhin können
MRL-Mittel unter
Verwendung beliebiger geeigneter Mittel angebracht werden; zum Beispiel
können
MRL-Mittel mit einer selbstklebenden Rückseite hergestellt werden,
oder mit wiederverwendbaren Bändern,
die an ihnen angebracht sind. MRL-Mittel können auch in Behälter eingegossen
oder dauerhaft an ihnen befestigt sein. Ein Display-Stand kann als
Träger
von MRL-Mitteln in der Nähe von
Obst- und Gemüsewaren
dienen, oder sie können
in die Kunststoffbeutel eingearbeitet sein, welche in den Obst-
und Gemüsebereichen
von Supermärkten
oft zur Verfügung
gestellt werden. Die Daten, welche das Verbrauchsgut kennzeichnen,
können
von einer Registrierkasse in einem Geschäft als eine zusätzlicher
Abgang aus dem Bestand einer Verkaufseinrichtung und/oder für eine Einkaufsverfolgung
(Purchase-Tracking) verwendet werden. Stattdessen können auch
Stationen vorhanden sein, welche es dem Benutzer ermöglichen, die
relevanten Informationen einzugeben, so wie in vielen europäischen Supermärkten, wo
Benutzer Obst- und Gemüseartikel
abwiegen und an einem Terminal eine Auswahl treffen, um einen Strichcode
auszudrucken. Die Zuordnungsdaten könnten auf dieselbe Art und
Weise generiert werden.
-
Es
wird auf 30 Bezug genommen; die Menge
kann automatisch mit Hilfe eines Gerätes aktualisiert werden, welches
die entnommene oder verbleibende Menge oder irgendeine andere Eigenschaft
eines Artikels, die sich geändert
hat, misst. Zum Beispiel könnte
eine intelligente Waage 650 mit einem in sie eingebauten
Lesegerät 645 verwendet
werden. Das letzte Leergewicht des Artikels würde jedes Mal, wenn der Artikel für einen
Moment auf die Waage 645 gestellt wurde, aktualisiert,
um die Menge anzuzeigen. Eine solche Waage 645 kann in
einen Kühlschrank
und/oder Küchenschrank
eingebaut sein. Die Waage kann eine Benutzeroberfläche 640 aufweisen.
Die Aktualisierungsdaten können
vom Benutzer manuell eingegeben werden; zum Beispiel könnte die
Benutzeroberfläche
eines in eine Tischsäge
eingebauten Lesegerätes
auffordern, die Änderung
der Größe eines
Brettes oder die Größe des abgeschnittenen
Stückes
einzugeben.
-
Wie
oben erläutert,
ist es unerheblich, wo die Zuordnungs- oder sonstigen Daten physikalisch
gespeichert werden. Netze und das Internet können ein Datenobjekt mit einem
Prozess verbinden, ebenso wie ein Datenbus einen physikalischen
Speicher oder nichtflüchtigen
Speicher mit einem Prozessor verbindet. Daher wird in dieser Erörterung
und an anderer Stelle, wo nicht ausdrücklich erwähnt ist, wo Daten gespeichert
werden, angenommen, dass dies nicht von Belang ist, und dass ein
Durchschnittsfachmann leicht eine geeignete Entscheidung treffen
könnte,
wo Daten gespeichert werden sollen – auf einem Server einer Verkaufseinrichtung,
auf einem Lesegerät,
auf einem Heim-Netzserver, auf einem Fremdserver usw. Daher können Profildaten einem
Benutzer auf allen seinen Wegen "folgen". So ist, wenn ein
Benutzer ein Lesegerät
an einem öffentlichen
Ort verwendet, das persönliche
Profil des Benutzers für
die Prozesse zugänglich,
die der Benutzer verwendet. Dies setzt voraus, dass geeignete Sicherheitseinrichtungen
angebracht sind, um die Profildaten des Benutzers zu schützen. Außerdem ist
anzumerken, dass in den obigen Erörterungen in den meisten Fällen vorausgesetzt
wurde, dass irgendeine Art von Benutzeroberfläche, wie etwa jene, die in
einen Handheld-Organizer mit einem Berührungsbildschirm eingebaut
sind, mit den erörterten
Lesegeräten
gekoppelt ist, um das Anzeigen und Eingeben von Daten zu ermöglichen.
Die Benutzeroberfläche
könnte
Teil des Gerätes
sein, an welchem das Lesegerät
angebracht und mit welchem es verknüpft ist, oder sie könnte Teil
des Lesegerätes sein.
Die Einzelheiten der Benutzeroberfläche sind nicht wichtig, sofern
nicht etwas Anderes angegeben ist, und könnten von einem beliebigen
geeigneten Typ sein, den der Konstrukteur nach seinem Ermessen wählen kann.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-