EP2302525A1 - Parallel computing system and communication control program - Google Patents
Parallel computing system and communication control program Download PDFInfo
- Publication number
- EP2302525A1 EP2302525A1 EP10174920A EP10174920A EP2302525A1 EP 2302525 A1 EP2302525 A1 EP 2302525A1 EP 10174920 A EP10174920 A EP 10174920A EP 10174920 A EP10174920 A EP 10174920A EP 2302525 A1 EP2302525 A1 EP 2302525A1
- Authority
- EP
- European Patent Office
- Prior art keywords
- value
- sign
- relative coordinates
- absolute value
- processors
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Ceased
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/80—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors
- G06F15/8007—Architectures of general purpose stored program computers comprising an array of processing units with common control, e.g. single instruction multiple data processors single instruction multiple data [SIMD] multiprocessors
- G06F15/803—Three-dimensional arrays or hypercubes
Definitions
- Embodiments discussed herein relate to an all-to-all communication method performed in a parallel computer and the like.
- the inter-processor communication performance substantially affects the overall performance of an application.
- a small bisection bandwidth network such as a mesh and a torus
- the overlapping of communication channels tends to occur, and thus the communication performance is deteriorated.
- the development of a communication algorithm enabling the use of all bands is important.
- Mesh refers to a system of network configuration for connecting processors of a parallel computer. According to the system, the processors are arranged at grid points of a multidimensional orthogonal grid, and adjacent ones of the processors are connected together in respective dimensions of multidimensional orthogonal coordinates.
- Torus is another word referring to a system of network configuration of a parallel computer.
- the processors are arranged at grid points of a multidimensional orthogonal grid, and adjacent ones of the processors are connected together in respective dimensions of multidimensional orthogonal coordinates. Further, the processors located at the ends in each of the dimensions are connected together, and thereby each of the dimensions has a circular coordinate system.
- Figs. 3A to 3E illustrate some examples of mesh and torus.
- Figs. 3A to 3E illustrate states of connection between processors in various types of networks, wherein the processors are indicated by circles or spheres.
- Fig. 3A illustrates a two-dimensional 4 ⁇ 4 mesh
- Fig. 3B illustrates a two-dimensional 4 ⁇ 4 torus.
- Each of Figs. 3A and 3B illustrates an example in which the lengths in the respective dimensions of the network are equal. Essentially, however, the lengths in the respective dimensions of the mesh or torus may be different.
- Fig. 3C illustrates an example of a two-dimensional 4x6 torus.
- Fig. 3D illustrates an example of a three-dimensional 4 ⁇ 4 ⁇ 4 mesh
- Fig. 3E illustrates an example of a three-dimensional 4 ⁇ 4 ⁇ 4 torus.
- “Bisection bandwidth” is an indicator indicating the bandwidth of a network, and refers to the sum of the bandwidths of all links present between two sections divided from a network so that each of the sections includes substantially the same number of processors, e.g., the bandwidths of data transfer channels connecting the processors. If there are a plurality of conceivable division patterns for dividing a network into two sections, a division pattern minimizing the bisection bandwidth is used.
- All-to-all communication refers to communication in which each of all processors included in a distributed parallel computer takes a communication pattern of transferring mutually different messages to all of the other processors. All-to-all communication is frequently used in many applications, such as matrix transposition and fast Fourier transform.
- Non-Patent Document 1 proposes algorithms for hypercube and mesh topologies.
- Non-Patent Documents 2 and 3 propose algorithms for n-dimensional torus topologies.
- phase division According to the method of phase division, however, all processors perform the transfer of messages and the suspension of the transfer in synchronization with one another. Further, all processors are synchronized at every start of each phase. Therefore, an issue arises when the method is used in an actual system. The method using phase division increases unnecessary overhead in all-to-all communication.
- Non-Patent Document 5 uses, in BlueGene® (see Non-Patent Document 4), an algorithm combining the randomization of a communication address with the adaptive routing technique.
- Non-Patent Document 6 discloses a technique using the static routing and the barrier synchronization in an asymmetric torus.
- one processor has a plurality of communication controllers.
- This type of hardware is capable of performing a plurality of message communications in parallel.
- Non-Patent Documents 7 and 8 disclose methods of effectively using a plurality of communication controllers.
- LSI Large-Scale Integration
- it has become easier to mount a plurality of communication hardware modules on each processor.
- a specific communication pattern such as all-to-all communication.
- the methods of Non-Patent Documents 7 and 8 do not take the overlapping of communication channels into account, and thus deteriorate the communication performance of a parallel computer using a mesh or torus topology due to the overlapping of communication channels.
- Non-Patent Document 1 D. S. Scott, "Efficient all-to-all communication patterns in hypercube and mesh topologies," in 6th Distributed Memory Computing Conference, 1991, pp. 398-403 ;
- Non-Patent Document 2 Takeshi Horie and Kenichi Hayashi, "Optimal All-to-All Communication Method in Torus Network," Transactions of Information Processing Society of Japan, vol. 34, no. 4, pp. 628-637, 1993 ;
- Non-Patent Document 3 Y.-C. Tseng and S. K. S. Gupta, "All-to-all personalized communication in a wormhole-routed torus," IEEE Transactions on Parallel and Distributed Systems, vol. 7, no. 5, pp. 498-505, May 1996 ;
- Non-Patent Document 4 N. R. Adiga, M. A. Blumrich, D. Chen, P. Coteus, A. Gara, M. E. Giampapa, P. Heidelberger, S. Singh, B. D. Steinmacher-Burow, T. Takken, M. Tsao, and P. Vranas, "Blue Gene/L torus interconnection network," IBM Journal of Research and Development, vol. 49, no. 2/3, pp. 265-276, 2005 ;
- Non-Patent Document 5 G. Alamasi, P. Heidelberger, C. J. Archer, X. Martorell, C. C. Erway, J. E. Moreira, B. Steinmacher-Burow, and Y. Zheng, "Optimization of mpi collective communication on bluegene/I systems," in ICS '05: Proceedings of the 19th annual international conference on Supercomputing, New York, NY, USA: ACM, 2005, pp. 253-262 ;
- Non-Patent Document 6 S. Kumar, Y. Sabharwal, R. Garg, and P. Heidelberger, "C7ptirnization of All-to-All Communication on the Blue Gene/L Supercomputer," in 37th International Conference on Parallel Processing, Sept 2008, pp. 320-329 ;
- Non-Patent Document 7 J. Bruck, C.-T. Ho, S. Kipnis, and D. Weathersby, "Efficient Algorithms for all-to-all communications in multi-port message-passing systems," in SPAA '94: Proceedings of the sixth annual ACM symposium on Parallel algorithms and architectures, New York, NY, USA: ACM, 1994, pp. 298-309 ; and
- Non-Patent Document 8 V. Tipparaju and J. Nieplocha, "Optimizing all-to-all collective communication by exploiting concurrency in modern networks," in SC '05: Proceedings of the 2005 ACM/IEEE conference on Supercomputing, Washington, DC, USA: IEEE Computer Society, 2005, p. 46 .
- phase division In optimal all-to-all communication for a torus network, the method of phase division has been employed.
- inter-processor communication is divided into a plurality of sets, and the sets of inter-processor communication are sequentially carried out to thereby achieve all-to-all communication.
- Communications in each phase are selected so that the overlapping of channels does not occur, and that all connections are used.
- some processors perform communication and some processors do not perform communication in substantially the same communication phase. It is therefore necessary to achieve the communications of the respective processors by the co-operation of different control methods. As a result, there arises an issue of complicated control.
- An aspect of the present embodiments provide a parallel computing system, which multi-dimensionally connects a plurality of processors by using an interconnection network, determines, in dimensional order, communication channels from each of the processors in the parallel computing system to other processors in the interconnection network, sets, as the relative coordinates of destination processors with respect to each of the processors in data communications performed at substantially the same timing, relative coordinates common to all of the processors, and performs data communications with destination processors having the set relative coordinates.
- each of computing nodes performs substantially simultaneous inter-node communications with a plurality of destination nodes.
- substantially the same transmission control is performed on all of the nodes. It is therefore possible to reduce control overhead attributed to the dependencies among complicated inter-node controls.
- the respective processors determine the destination processors in accordance with the algorithms common thereto. Therefore, the implementation of the transmission control on the processors is performed.
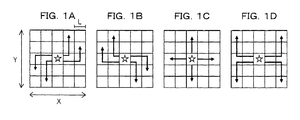
- Figs. 1A to 1D illustrate a two-dimensional torus topology according to an embodiment, wherein each of the sides of the topology has a length corresponding to an odd number;
- Figs. 2A and 2B illustrate a two-dimensional torus topology according to an embodiment, wherein each of the sides of the topology has a length corresponding to an even number;
- Figs. 3A to 3E illustrate examples of network configuration
- Fig. 4 illustrates a configuration of a node according to an embodiment.
- a parallel computing system connects a plurality of processors by using an interconnection network.
- the interconnection network is a two-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, the length in a first dimension and the length in a second dimension of the interconnection network are equal to each other. See Fig. 1 for an example of the parallel computing system according to the embodiment.
- Each grid in Fig. 1 denotes a processor.
- Each of the processors included in the parallel computing system of the present embodiment is capable of substantially simultaneously transmitting data to a maximum of four processors. Further, in the substantially simultaneous data transmission from each source processor to the respective destination processors, the relative coordinates of the destination processors with respect to the source processor are set to be common to all of the processors included in the parallel computing system.
- the length in the first dimension and the length in the second dimension of the interconnection network are represented as L.
- the length "L” indicates the number of links in the direction of each dimension, and does not necessarily refer to the physical length. This definition similarly applies to the other embodiments.
- the relative coordinate value in the first dimension is represented as Xn
- the relative coordinate value in the second dimension is represented as Yn.
- an arbitrary source processor in the parallel computing system substantially simultaneously transmits data to destination processors by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- each of the processors performs the following operations.
- each of the processors determines the relative coordinate values of the relative coordinates "X1, Y1" as follows:
- the relative coordinate values of the relative coordinates indicating three other destination processors are determined as follows.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1,” “X2, Y2,” “X3, Y3,” and “X4, Y4.”
- all of the processors in the parallel computing system perform, at substantially the same timing, substantially simultaneous data transmission to four destination processors indicated by substantially the same relative coordinates. Therefore, the present embodiment is capable of transmitting data by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of the relative coordinates indicating three other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1,” “X2, Y2,” “X3, Y3,” and "X4, Y4.”
- each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of the relative coordinates of two other destination processors as follows.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to three destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1,” “X2, Y2,” and “X3, Y3" by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- the number of the processors included in the parallel computing system is also an odd number.
- the number of the destination processors to be subjected to all-to-all communication is an even number.
- each of the processors performs substantially simultaneous transmission to four destination processors by performing the substantially simultaneous transmission the (L1) 2 /4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other and performing the substantially simultaneous transmission the (L-1)/2 times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, while changing the relative coordinate values for each of the substantially simultaneous transmissions and determining the relative coordinate values of the destination processors so that data is not transmitted to the same processor more than once.
- the number of the processors included in the parallel computing system is an even number.
- the number of the destination processors to be subjected to all-to-all communication is an odd number.
- each of the processors performs substantially simultaneous transmission to four destination processors the (L-1) 2 /4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other, performs substantially simultaneous transmission to four destination processors the (L/2-1) times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, and performs one substantially simultaneous transmission to three destination processors with the absolute value of X1 and the absolute value of Y1 set to be equal to each other and set to half the L value, while changing the relative coordinate values for each of the simultaneous transmissions and determining the relative coordinate values of the destination processors so that the overlapping of destination processors does not occur.
- the parallel computing system may arbitrarily determine the transfer direction for each data transfer in a dimension in which the absolute value of the corresponding relative coordinate is half the L value.
- each of the processors performs substantially simultaneous transmission to a plurality of destination processors a plurality of times.
- simultaneous transmission performed by all of the processors in a similar manner is a condition for equalizing the loads on the links.
- the processors have different processing times due to disturbance factors. As a result, asymmetry may occur in which, during a substantially simultaneous communication by a processor, another processor starts the next simultaneous communication.
- the synchronization of the processors is performed with the use of a synchronization mechanism by hardware, which is generally provided in a parallel computing system. Even if a parallel computing system does not include a synchronization mechanism, as in the case of a PC (Personal Computer) cluster or the like, the parallel computing system may use a synchronization library usually provided by software.
- the processing of determining the relative coordinate values of the destination processors may be performed by each of the processors every time the data transmission processing is performed. Further, the relative coordinate values of the destination processors previously determined by an arbitrary algorithm may be set in a table or the like of each of the processors, and the relative coordinate values set in the table or the like may be read by each of the processors every time the data transmission processing is performed.
- a parallel computing system connects a plurality of processors by using an interconnection network.
- the interconnection network is a two-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, the length in a first dimension and the length in a second dimension of the interconnection network are different from each other.
- Each of the processors in the parallel computing system according to the second embodiment is capable of substantially simultaneously transmitting data to a maximum of four processors.
- the relative coordinates used when data is substantially simultaneously transmitted from each of the processors to a plurality of destination processors are common to all of the processors included in the parallel computing system.
- the maximum value of the length in the first dimension and the length in the second dimension of the interconnection network is represented as L.
- the relative coordinate value in the first dimension is represented as Xn
- the relative coordinate value in the second dimension is represented as Yn. If any of the length in the first dimension and the length in the second dimension is less than the L value, however, a transmittable range corresponding to the length in the dimension is preset, and the transmission operation is not performed to relative coordinates exceeding the transmittable range.
- each of the processors in the parallel computing system substantially simultaneously transmits data to destination processors having the relative coordinates determined as follows, by using the respective links of the two-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors first determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of the relative coordinates of three other destination processors as follows.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1,” “X2, Y2,” “X3, Y3,” and “X4, Y4" by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of the relative coordinates of three other destination processors as follows.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1,” “X2, Y2,” “X3, Y3,” and “X4, Y4" by using the respective links of the two-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of the relative coordinates of two other destination processors as follows.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to three destination processors located at the above-determined relative coordinates "X1, Y1,” “X2, Y2,” and “X3, Y3" by using the respective links of the two-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors performs substantially simultaneous transmission to four destination processors by performing the substantially simultaneous transmission the (L-1) 2 /4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other and performing the substantially simultaneous transmission the (L-1)/2 times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, while changing the relative coordinate values of the destination processors in each of the simultaneous transmissions so that the overlapping of destination processors does not occur.
- each of the processors performs substantially simultaneous transmission to four destination processors the (L-1) 2 /4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other, performs substantially simultaneous transmission to four destination processors the (L/2-1) times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, and performs one substantially simultaneous transmission to three destination processors with the absolute value of X1 and the absolute value of Y1 set to be equal to each other and set to half the L value so that the overlapping of destination processors does not occur.
- a parallel computing system connects a plurality of processors by using an interconnection network.
- the interconnection network is a two-dimensional mesh, and the communication channels of the interconnection network are determined in dimensional order.
- each of the processors in the parallel computing system substantially simultaneously transmits data to a maximum of four processors.
- the relative coordinates of a plurality of destination processors with respect to an arbitrary processor are common to all of the processors included in the parallel computing system.
- the maximum value of the length in a first dimension and the length in a second dimension of the interconnection network is represented as L.
- the relative coordinate value in the first dimension is represented as Xn
- the relative coordinate value in the second dimension is represented as Yn. If the relative coordinates of a destination processor with respect to an arbitrary processor are located outside the interconnection network, however, the transmission from the processor to the destination processor is not performed.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- the relative coordinate values of the relative coordinates of three other destination processors are determined as follows.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1,” “X2, Y2,” “X3, Y3,” and “X4, Y4" by using the respective links of the two-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of three other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1,” “X2, Y2,” “X3, Y3,” and “X4, Y4" by using the respective links of the two-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to three destination processors located at the above-determined relative coordinates "X1, Y1,” “X2, Y2,” and “X3, Y3" by using the respective links of the two-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- an arbitrary processor performs substantially simultaneous transmission to four destination processors by performing the substantially simultaneous transmission the (L-1) 2 /4 times with the absolute value of X1 and the absolute value of Y1 in the relative coordinates of the destination processor set to be different from each other and performing the simultaneous transmission the (L-1)/2 times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other so that the overlapping of destination processors does not occur.
- an arbitrary processor performs substantially simultaneous transmission to four destination processors the (L-1) 2 /4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other, performs substantially simultaneous transmission to four destination processors the (L/2-1) times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, and performs one substantially simultaneous transmission to three destination processors so that the overlapping of destination processors does not occur.
- the interconnection network is a three-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, the length in a first dimension, the length in a second dimension, and the length in a third dimension of the interconnection network are substantially equal to one another.
- Each of the processors in the parallel computing system of the present embodiment substantially simultaneously transmits data to a maximum of six processors. Further, the relative coordinates of a plurality of destination processors with respect to an arbitrary processor are common to all of the processors included in the parallel computing system.
- an arbitrary source processor in the parallel computing system simultaneously transmits data to the destination processors in accordance with the following procedure by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- each of the length in the first dimension, the length in the second dimension, and the length in the third dimension of the interconnection network is represented as L.
- the relative coordinate value in the first dimension is represented as Xn
- the relative coordinate value in the second dimension is represented as Yn
- the relative coordinate value in the third dimension is represented as Zn.
- each of the processors sets the relative coordinate values of relative coordinates "X1, Y1, Z1" of an arbitrary destination processor in the following procedure.
- at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values, and the relative coordinates correspond to one of the following conditions:
- each of the processors determines the relative coordinates of five other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to six destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1, Z1,” “X2, Y2, Z2,” “X3, Y3, Z3,” “X4, Y4, Z4,” “X5, Y5, Z5,” and “X6, Y6, Z6” by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- all of the processors perform, at substantially the same timing, simultaneous data transmission to destination processors having the same relative coordinate values.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- each of the processors determines the relative coordinates of three other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1, Z1,” “X2, Y2, Z2,” “X3, Y3, Z3,” and "X4, Y4, Z4" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- each of the processors determines the relative coordinates of six other destination processors as follows.
- Each of all processors in the parallel computing system performs, as the first simultaneous transmission, substantially simultaneous data transmission to the first destination processor corresponding to the relative coordinates "X1, Y1, Z1,” the second destination processor corresponding to the relative coordinates "X2, Y2, Z2,” and the third destination processor corresponding to the relative coordinates "X3, Y3, Z3" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- each of the source processors performs, as the second simultaneous transmission, substantially simultaneous data transmission to the fourth destination processor corresponding to the relative coordinates "X4, Y4, Z4," the fifth destination processor corresponding to the relative coordinates "X5, Y5, Z5,” the sixth destination processor corresponding to the relative coordinates "X6, Y6, Z6,” and the seventh destination processor corresponding to the relative coordinates "X7, Y7, Z7" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links. That is, in the present example, the data transmission to seven destination processors in total is performed in two sessions.
- the parallel computing system determines the relative coordinates of the destination processors by combining, as required, the above-described three types of relative coordinate value determination algorithms, and performs the substantially simultaneous data transmission to the destination processors.
- an arbitrary processor performs substantially simultaneous transmission to six destination processors the (L 3 -4L+3)/4 times, and performs substantially simultaneous transmission to four destination processors the L-1 times such that the overlapping of destination processors does not occur.
- an arbitrary processor performs simultaneous transmission to six destination processors the (L 3 -4L+1)/4 times, performs substantially simultaneous transmission to four destination processors the L-2 times, and performs substantially simultaneous transmission to seven destination processors with one substantially simultaneous transmission to three destination processors and one substantially simultaneous transmission to four destination processors so that the overlapping of destination processors does not occur.
- a parallel computing system connects a plurality of processors by using an in interconnection network.
- the interconnection network according to the fifth embodiment is a three-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, at least one of the length in a first dimension, the length in a second dimension, and the length in a third dimension of the interconnection network is different from the lengths in the other dimensions.
- each of all processors in the parallel computing system substantially simultaneously transmits data to a maximum of six processors.
- the relative coordinates of a plurality of destination processors used when data is substantially simultaneously transmitted from an arbitrary processor to the destination processors are common to all of the processors included in the parallel computing system.
- the maximum value of the length in the first dimension, the length in the second dimension, and the length in the third dimension of the interconnection network is represented as L.
- the relative coordinate value in the first dimension is represented as Xn
- the relative coordinate value in the second dimension is represented as Yn
- the relative coordinate value in the third dimension is represented as Zn. If any of the length in the first dimension, the length in the second dimension, and the length in the third dimension is less than the L value, however, a transmittable range corresponding to the length in the dimension is preset, and the transmission processing is not performed to a processor located at relative coordinates exceeding the transmittable range.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows.
- each of the processors determines the relative coordinates of five other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to six destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X6, Y6, Z6" by using the respective links of the three-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- each of the processors determines the relative coordinates of three other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X4, Y4, Z4" by using the respective links of the three-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- each of the processors determines the relative coordinates of six other destination processors as follows.
- Each of all processors in the parallel computing system performs, as the first simultaneous transmission, substantially simultaneous data transmission to the first destination processor corresponding to the relative coordinates "X1, Y1, Z1,” the second destination processor corresponding to the relative coordinates "X2, Y2, Z2,” and the third destination processor corresponding to the relative coordinates "X3, Y3, Z3" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- each of the source processors performs, as the second simultaneous transmission, substantially simultaneous data transmission to the fourth destination processor corresponding to the relative coordinates "X4, Y4, Z4," the fifth destination processor corresponding to the relative coordinates "X5, Y5, Z5,” the sixth destination processor corresponding to the relative coordinates "X6, Y6, Z6,” and the seventh destination processor corresponding to the relative coordinates "X7, Y7, Z7" by using the respective links of the three-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- the parallel computing system determines the relative coordinates of the destination processors by combining, as required, the above-described three types of relative coordinate value determination algorithms, and performs the substantially simultaneous data transmission to the destination processors.
- each of the processors performs substantially simultaneous transmission to six destination processors the (L 3 -4L+3)/4 times, and performs substantially simultaneous transmission to four destination processors the L-1 times so that the overlapping of destination processors does not occur.
- each of the processors performs substantially simultaneous transmission to six destination processors the (L 3 -4L+1)/4 times, performs substantially simultaneous transmission to four destination processors the L-2 times, and performs substantially simultaneous transmission to seven destination processors with one substantially simultaneous transmission to three destination processors and one substantially simultaneous transmission to four destination processors so that the overlapping of destination processors does not occur.
- a parallel computing system connects a plurality of processors by using an interconnection network.
- the interconnection network is a three-dimensional mesh, and the communication channels of the interconnection network are determined in dimensional order. Further, each of all processors in the parallel computing system substantially simultaneously transmits data to a maximum of six processors.
- the relative coordinates of a plurality of destination processors with respect to each of the processors are common to all of the processors included in the parallel computing system.
- the maximum value of the length in a first dimension, the length in a second dimension, and the length in a third dimension of the interconnection network is represented as L.
- the relative coordinate value in the first dimension is represented as Xn
- the relative coordinate value in the second dimension is represented as Yn
- the relative coordinate value in the third dimension is represented as Zn. If a destination processor is located outside the interconnection network, however, the transmission to the destination processor is not performed.
- Each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows.
- each of the processors determines the relative coordinate values so that at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values, and that the relative coordinate values correspond to one of the following conditions:
- each of the processors determines the relative coordinates of five other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to six destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X6, Y6, Z6" by using the respective links of the three-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- each of the processors determines the relative coordinates of three other destination processors as follows.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X4, Y4, Z4" by using the respective links of the three-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- each of the processors determines the relative coordinate values of six other destination processors as follows.
- Each of all processors in the parallel computing system performs, as the first simultaneous transmission, substantially simultaneous data transmission to the first destination processor corresponding to the relative coordinates "X1, Y1, Z1,” the second destination processor corresponding to the relative coordinates "X2, Y2, Z2,” and the third destination processor corresponding to the relative coordinates "X3, Y3, Z3" by using all links of the three-dimensional mesh interconnection network with substantially equal loads placed on the links.
- each of the source processors performs, as the second simultaneous transmission, substantially simultaneous data transmission to the fourth destination processor corresponding to the relative coordinates "X4, Y4, Z4," the fifth destination processor corresponding to the relative coordinates "X5, Y5, Z5,” the sixth destination processor corresponding to the relative coordinates "X6, Y6, Z6,” and the seventh destination processor corresponding to the relative coordinates "X7, Y7, Z7" by using the respective links of the three-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- each of the processors performs substantially simultaneous transmission to six destination processors the (L 3 -4L+3)/4 times, and performs substantially simultaneous transmission to four destination processors the L-1 times so that the overlapping of destination processors does not occur.
- each of the processors performs substantially simultaneous transmission to six destination processors the (L 3 -4L+1)/4 times, performs substantially simultaneous transmission to four destination processors the L-2 times, and performs substantially simultaneous transmission to seven destination processors with one substantially simultaneous transmission to three destination processors and one substantially simultaneous transmission to four destination processors so that the overlapping of destination processors does not occur.
- each of the processors transmits and receives a plurality of messages in parallel in accordance with a plurality of communication controllers provided in the corresponding node.
- the processors serving as communication destinations are arranged in order. Thereby, the relative coordinates of the destination processors with respect to each of nodes are set to be the same among all of the nodes, and the number of inter-processor communications routed through all links between network routers of the system is equalized among the links.
- a parallel computing system using a two-dimensional torus which connects nodes 1 each configured to include a processor 2, four communication controllers 3, and a network router 4, as illustrated in Fig. 4 , the number of inter-processor communications routed through the respective links is equalized among the links in accordance with the following algorithms.
- Figs. 1A to 1D are diagrams illustrating an example of a two-dimensional torus topology.
- the two-dimensional torus topology illustrated in Figs. 1A to 1D has two sides having the same length corresponding to an odd number.
- Figs. 1A to 1D the length of each of the sides is represented as 2n+1, wherein "n" represents a natural number. Further, the star illustrated in Figs. 1A to 1D indicates a source processor.
- each of all processors first performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, j), (-i, -j), (j, i), and (-j, -i) with respect to the processor ( Fig. 1A ).
- each of the processors performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, -j), (-i, j), (-j, i), and (j, -i) with respect to the processor ( Fig. 1B ).
- each of the processors performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, 0), (-i, 0), (0, i), and (0, -i) with respect to the processor ( Fig. 1C ).
- each of the processors performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, i), (-i, -i), (-i, i), and (i, -i) with respect to the processor ( Fig. 1D ).
- Figs. 2A and 2B illustrate a two-dimensional torus topology which has two sides having the same length corresponding to an even number. Also in Figs. 2A and 2B , the star indicates a source processor.
- an arbitrary processor communicates with a processor having a value of at least -n and at most n as the relative coordinate thereof on each of the coordinate axes with respect to the arbitrary processor. Then, in accordance with the following combinations, the arbitrary processor communicates with the remaining processors having a value of -n-1 or n+1 as the relative coordinate thereof on at least one of the coordinate axes with respect to the arbitrary processor.
- each of all processors first performs substantially simultaneous communication with four processors respectively located at relative coordinates (n+1, i), (-n-1, -i), (i, n+1), and (-i, -n-1) with respect to the processor ( Fig. 2A ).
- each of all processors performs substantially simultaneous communication with three processors respectively located at relative coordinates (n+1, 0), (0, n+1), and (-n-1, -n-1) with respect to the processor ( Fig. 2B ).
- each of the processors first performs simultaneous communication with six processors in accordance with the following combinations of relative coordinates.
- "i", "J” and "k” denotes coordinate values of X axis, Y axis and Z axis of a three-dimensional torus topology.
- six sets of relative coordinates form one group. This feature similarly applies to the subsequent examples.
- each of the processors performs substantially simultaneous communication with six processors corresponding to the following combinations of relative coordinates with respect to the processor. Also in the following example, six sets of relative coordinates form one group.
- each of the processors performs substantially simultaneous communication with a plurality of processors corresponding to the following combinations of relative coordinates with respect to the processor.
- an arbitrary processor communicates with a processor having a value of at least -n and at most n as each of the relative coordinates thereof on the respective coordinate axes (x-axis, y-axis, and z-axis) with respect to the arbitrary processor. Then, in accordance with the following combinations, the arbitrary processor communicates with, among the remaining processors, the processors having a value of -n-1 or n+1 as the relative coordinate thereof on at least one of the three coordinate axes.
- each of the processors performs substantially simultaneous communication with six processors corresponding to the following combinations of relative coordinates with respect to the processor.
- each of the processors performs substantially simultaneous communication with six processors corresponding to the following combinations of relative coordinates with respect to the processor.
- each of the processors performs substantially simultaneous communication with a plurality of processors corresponding to the following combinations of relative coordinates with respect to the processor.
- the processing in which each of the processors determines the destination processors is performed as a program recorded in a recording medium is executed by each of the processors.
- the recording medium for recording the program may include a storage device, e.g., as a magnetic disk device included in a node provided with the processor.
- the program may be stored in a portable recording medium, e.g., an optical disk and a magnetic disk, read from the portable recording medium with the use of a storage medium reading device provided to the node or the like, and executed by the processor.
- Various types of semiconductor recording devices may be used as the recording medium for recording the program.
Abstract
A parallel computing system includes a plurality of processors multi-dimensionally commented by an interconnection network, wherein each of the processors in the parallel computing system determines, in dimensional order, communication channels to other processors in the interconnection network, each of the processors sets, as relative coordinates of destination processors with respect to the plurality of processors in data communications performed at a same timing, relative coordinates common to all of the processors, and each of the processors performs data communications with destination processors having the set relative coordinates.
Description
- This application is based upon and claims the benefit of priority of prior Japanese Patent Application No.
2009-201560, filed on September 1, 2009 - Embodiments discussed herein relate to an all-to-all communication method performed in a parallel computer and the like.
- In a distributed parallel computer, the inter-processor communication performance substantially affects the overall performance of an application. In a small bisection bandwidth network, such as a mesh and a torus, the overlapping of communication channels tends to occur, and thus the communication performance is deteriorated. Particularly in such a network, the development of a communication algorithm enabling the use of all bands is important.
- "Mesh" refers to a system of network configuration for connecting processors of a parallel computer. According to the system, the processors are arranged at grid points of a multidimensional orthogonal grid, and adjacent ones of the processors are connected together in respective dimensions of multidimensional orthogonal coordinates.
- "Torus" is another word referring to a system of network configuration of a parallel computer. According to the system, the processors are arranged at grid points of a multidimensional orthogonal grid, and adjacent ones of the processors are connected together in respective dimensions of multidimensional orthogonal coordinates. Further, the processors located at the ends in each of the dimensions are connected together, and thereby each of the dimensions has a circular coordinate system.
-
Figs. 3A to 3E illustrate some examples of mesh and torus.Figs. 3A to 3E illustrate states of connection between processors in various types of networks, wherein the processors are indicated by circles or spheres.Fig. 3A illustrates a two-dimensional 4×4 mesh, andFig. 3B illustrates a two-dimensional 4×4 torus. Each ofFigs. 3A and 3B illustrates an example in which the lengths in the respective dimensions of the network are equal. Essentially, however, the lengths in the respective dimensions of the mesh or torus may be different.Fig. 3C illustrates an example of a two-dimensional 4x6 torus. Further,Fig. 3D illustrates an example of a three-dimensional 4×4×4 mesh, andFig. 3E illustrates an example of a three-dimensional 4×4×4 torus. - "Bisection bandwidth" is an indicator indicating the bandwidth of a network, and refers to the sum of the bandwidths of all links present between two sections divided from a network so that each of the sections includes substantially the same number of processors, e.g., the bandwidths of data transfer channels connecting the processors. If there are a plurality of conceivable division patterns for dividing a network into two sections, a division pattern minimizing the bisection bandwidth is used.
- All-to-all communication refers to communication in which each of all processors included in a distributed parallel computer takes a communication pattern of transferring mutually different messages to all of the other processors. All-to-all communication is frequently used in many applications, such as matrix transposition and fast Fourier transform.
- Some all-to-all communication algorithms have been proposed so far which take the overlapping of communication channels in a network into account.
- Non-Patent
Document 1 proposes algorithms for hypercube and mesh topologies. - Non-Patent
Documents - These algorithms achieve a theoretically minimum communication time. All of these algorithms assume "a method of phase division" in message communication. The algorithms divide inter-processor communication into a plurality of sets and sequentially carry out the sets of inter-processor communication, to thereby achieve all-to-all communication. Each processor repeats the transfer of messages and the suspension of the transfer as previously scheduled, to thereby increase the usage rate of all links of a network to 100%.
- According to the method of phase division, however, all processors perform the transfer of messages and the suspension of the transfer in synchronization with one another. Further, all processors are synchronized at every start of each phase. Therefore, an issue arises when the method is used in an actual system. The method using phase division increases unnecessary overhead in all-to-all communication.
- Non-Patent Document 5 uses, in BlueGene® (see Non-Patent Document 4), an algorithm combining the randomization of a communication address with the adaptive routing technique.
- Non-Patent Document 6 discloses a technique using the static routing and the barrier synchronization in an asymmetric torus.
- In some of parallel computers of recent years, one processor has a plurality of communication controllers. This type of hardware is capable of performing a plurality of message communications in parallel.
- Non-Patent Documents 7 and 8 disclose methods of effectively using a plurality of communication controllers. Along with an increase in the degree of integration of LSI (Large-Scale Integration), it has become easier to mount a plurality of communication hardware modules on each processor. As a result, there has been an increasing desire for a method of effectively using a plurality of communication hardware modules with a specific communication pattern, such as all-to-all communication. Meanwhile, the methods of Non-Patent Documents 7 and 8 do not take the overlapping of communication channels into account, and thus deteriorate the communication performance of a parallel computer using a mesh or torus topology due to the overlapping of communication channels.
- Related art includes the following:
- Non-Patent Document 1: D. S. Scott, "Efficient all-to-all communication patterns in hypercube and mesh topologies," in 6th Distributed Memory Computing Conference, 1991, pp. 398-403;
- Non-Patent Document 2: Takeshi Horie and Kenichi Hayashi, "Optimal All-to-All Communication Method in Torus Network," Transactions of Information Processing Society of Japan, vol. 34, no. 4, pp. 628-637, 1993;
- Non-Patent Document 3: Y.-C. Tseng and S. K. S. Gupta, "All-to-all personalized communication in a wormhole-routed torus," IEEE Transactions on Parallel and Distributed Systems, vol. 7, no. 5, pp. 498-505, May 1996;
- Non-Patent Document 4: N. R. Adiga, M. A. Blumrich, D. Chen, P. Coteus, A. Gara, M. E. Giampapa, P. Heidelberger, S. Singh, B. D. Steinmacher-Burow, T. Takken, M. Tsao, and P. Vranas, "Blue Gene/L torus interconnection network," IBM Journal of Research and Development, vol. 49, no. 2/3, pp. 265-276, 2005;
- Non-Patent Document 5: G. Alamasi, P. Heidelberger, C. J. Archer, X. Martorell, C. C. Erway, J. E. Moreira, B. Steinmacher-Burow, and Y. Zheng, "Optimization of mpi collective communication on bluegene/I systems," in ICS '05: Proceedings of the 19th annual international conference on Supercomputing, New York, NY, USA: ACM, 2005, pp. 253-262;
- Non-Patent Document 6: S. Kumar, Y. Sabharwal, R. Garg, and P. Heidelberger, "C7ptirnization of All-to-All Communication on the Blue Gene/L Supercomputer," in 37th International Conference on Parallel Processing, Sept 2008, pp. 320-329;
- Non-Patent Document 7: J. Bruck, C.-T. Ho, S. Kipnis, and D. Weathersby, "Efficient Algorithms for all-to-all communications in multi-port message-passing systems," in SPAA '94: Proceedings of the sixth annual ACM symposium on Parallel algorithms and architectures, New York, NY, USA: ACM, 1994, pp. 298-309; and
- Non-Patent Document 8: V. Tipparaju and J. Nieplocha, "Optimizing all-to-all collective communication by exploiting concurrency in modern networks," in SC '05: Proceedings of the 2005 ACM/IEEE conference on Supercomputing, Washington, DC, USA: IEEE Computer Society, 2005, p. 46.
- In optimal all-to-all communication for a torus network, the method of phase division has been employed. In the phase division, inter-processor communication is divided into a plurality of sets, and the sets of inter-processor communication are sequentially carried out to thereby achieve all-to-all communication. Communications in each phase are selected so that the overlapping of channels does not occur, and that all connections are used. According to this method, some processors perform communication and some processors do not perform communication in substantially the same communication phase. It is therefore necessary to achieve the communications of the respective processors by the co-operation of different control methods. As a result, there arises an issue of complicated control.
- An aspect of the present embodiments provide a parallel computing system, which multi-dimensionally connects a plurality of processors by using an interconnection network, determines, in dimensional order, communication channels from each of the processors in the parallel computing system to other processors in the interconnection network, sets, as the relative coordinates of destination processors with respect to each of the processors in data communications performed at substantially the same timing, relative coordinates common to all of the processors, and performs data communications with destination processors having the set relative coordinates.
- According to a parallel computing system and program of an embodiment of the present invention, all-to-all communication using all links with substantially equal loads placed thereon is achieved in a parallel computing system using a two- or three-dimensional topology. According to the present embodiment, each of computing nodes performs substantially simultaneous inter-node communications with a plurality of destination nodes. In the parallel computing system and program of the present embodiment, substantially the same transmission control is performed on all of the nodes. It is therefore possible to reduce control overhead attributed to the dependencies among complicated inter-node controls. Further, according to the present embodiment, the respective processors determine the destination processors in accordance with the algorithms common thereto. Therefore, the implementation of the transmission control on the processors is performed.
- Further, according to the parallel computing system and program of the present embodiments, it is possible to have substantially the same number of communications overlap in any of the communication channels, and to achieve desired all-to-all communication.
- The object and advantages of the invention will be realized and attained by means of the elements and combinations particularly pointed out in the claims.
- It is to be understood that both the foregoing general description and the following detailed description are exemplary and explanatory and are not restrictive of the invention, as claimed.
-
Figs. 1A to 1D illustrate a two-dimensional torus topology according to an embodiment, wherein each of the sides of the topology has a length corresponding to an odd number; -
Figs. 2A and 2B illustrate a two-dimensional torus topology according to an embodiment, wherein each of the sides of the topology has a length corresponding to an even number; -
Figs. 3A to 3E illustrate examples of network configuration; and -
Fig. 4 illustrates a configuration of a node according to an embodiment. - In the figures, dimensions and/or proportions may be exaggerated for clarity of illustration. It will also be understood that when an element is referred to as being "connected to" another element, it may be directly connected or indirectly connected, i.e., intervening elements may also be present. Further, it will be understood that when an element is referred to as being "between" two elements, it may be the only element layer between the two elements, or one or more intervening elements may also be present.
- Embodiments of the present invention will be described below.
- First Embodiment
- A parallel computing system according to an embodiment of the present invention connects a plurality of processors by using an interconnection network. In the present embodiment, the interconnection network is a two-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, the length in a first dimension and the length in a second dimension of the interconnection network are equal to each other. See
Fig. 1 for an example of the parallel computing system according to the embodiment. Each grid inFig. 1 denotes a processor. - Each of the processors included in the parallel computing system of the present embodiment is capable of substantially simultaneously transmitting data to a maximum of four processors. Further, in the substantially simultaneous data transmission from each source processor to the respective destination processors, the relative coordinates of the destination processors with respect to the source processor are set to be common to all of the processors included in the parallel computing system.
- In the present embodiment, the length in the first dimension and the length in the second dimension of the interconnection network are represented as L. Herein, the length "L" indicates the number of links in the direction of each dimension, and does not necessarily refer to the physical length. This definition similarly applies to the other embodiments.
- Further, in the relative coordinates of the n-th destination processor with respect to a source processor, the relative coordinate value in the first dimension is represented as Xn, and the relative coordinate value in the second dimension is represented as Yn. In the present embodiment, an arbitrary source processor in the parallel computing system substantially simultaneously transmits data to destination processors by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- In the parallel computing system according to the present embodiment, each of the processors performs the following operations.
- The relative coordinates of the first destination processor with respect to an arbitrary source processor are now represented as "X1, Y1." "X" denotes coordinate in X axis, and "Y" denotes coordinate in Y axis which is perpendicular to X axis. According to a first relative coordinate value determination algorithm, each of the processors determines the relative coordinate values of the relative coordinates "X1, Y1" as follows:
- 1) Set the absolute value of X1 and the absolute value of Y1 to be different from each other; and
- 2) Set X1 to zero and set the absolute value of Y1 to be different from half the L value, or set Y1 to zero and set the absolute value of X1 to be different from half the L value.
- In this case, the relative coordinate values of the relative coordinates indicating three other destination processors are determined as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to the sign-inverted value of Y1.
- 2) In relative coordinates "X3, Y3," set X3 to Y1, and set Y3 to X1.
- 3) In relative coordinates "X4, Y4," set X4 to the sign-inverted value of Y1, and set Y4 to the sign-inverted value of X1.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1," "X2, Y2," "X3, Y3," and "X4, Y4." In this process, all of the processors in the parallel computing system perform, at substantially the same timing, substantially simultaneous data transmission to four destination processors indicated by substantially the same relative coordinates. Therefore, the present embodiment is capable of transmitting data by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- Further, according to a second relative coordinate value determination algorithm, each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be equal to the absolute value of Y1; and
- 2) Set the absolute value of X1 and the absolute value of Y1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinate values of the relative coordinates indicating three other destination processors as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to the sign-inverted value of Y1.
- 2) In relative coordinates "X3, Y3," set X3 to Y1, and set Y3 to X1.
- 3) In relative coordinates "X4, Y4," set X4 to the sign-inverted value of Y1, and set Y4 to the sign-inverted value of X1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1," "X2, Y2," "X3, Y3," and "X4, Y4."
- Meanwhile, according to a third relative coordinate value determination algorithm, each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be equal to the absolute value of Y1; and
- 2) Set the absolute value of X1 and the absolute value of Y1 to half the L value.
- In this case, each of the processors determines the relative coordinate values of the relative coordinates of two other destination processors as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to zero.
- 2) In relative coordinates "X3, Y3," set X3 to zero, and set Y3 to the sign-inverted value of Y1.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to three destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1," "X2, Y2," and "X3, Y3" by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- In the present embodiment, the above-described three types of relative coordinate value determination algorithms are combined as specified to determine the destination processors to which data should be substantially simultaneously transmitted.
- Herein, if the L value is an odd number, the number of the processors included in the parallel computing system is also an odd number. With respect to an arbitrary source processor, therefore, the number of the destination processors to be subjected to all-to-all communication is an even number. In this case, each of the processors performs substantially simultaneous transmission to four destination processors by performing the substantially simultaneous transmission the (L1)2/4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other and performing the substantially simultaneous transmission the (L-1)/2 times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, while changing the relative coordinate values for each of the substantially simultaneous transmissions and determining the relative coordinate values of the destination processors so that data is not transmitted to the same processor more than once.
- Meanwhile, if the L value is an even number, the number of the processors included in the parallel computing system is an even number. With respect to an arbitrary source processor, therefore, the number of the destination processors to be subjected to all-to-all communication is an odd number. In this case, therefore, each of the processors performs substantially simultaneous transmission to four destination processors the (L-1)2/4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other, performs substantially simultaneous transmission to four destination processors the (L/2-1) times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, and performs one substantially simultaneous transmission to three destination processors with the absolute value of X1 and the absolute value of Y1 set to be equal to each other and set to half the L value, while changing the relative coordinate values for each of the simultaneous transmissions and determining the relative coordinate values of the destination processors so that the overlapping of destination processors does not occur.
- According to the above-described operations, if the transfer distances of data substantially simultaneously transmitted from each of the processors are added up for each of the dimensions and directions, the sum of the transfer distances from each of the processors is equal among all dimensions and directions. Further, all of the processors perform data transfer to the same relative coordinates. It is therefore possible to achieve all-to-all communication in the parallel computing system with equal loads placed on the links. If the L value is an even number, however, the parallel computing system may arbitrarily determine the transfer direction for each data transfer in a dimension in which the absolute value of the corresponding relative coordinate is half the L value.
- In the parallel computing system of the present embodiment, each of the processors performs substantially simultaneous transmission to a plurality of destination processors a plurality of times. Herein, simultaneous transmission performed by all of the processors in a similar manner is a condition for equalizing the loads on the links. In some cases, however, the processors have different processing times due to disturbance factors. As a result, asymmetry may occur in which, during a substantially simultaneous communication by a processor, another processor starts the next simultaneous communication.
- If all of the processors in the parallel computing system are synchronized between a substantially simultaneous transmission and the next transmission communication, the occurrence of asymmetry due to disturbance factors is inhibited. It is therefore possible that all of the processors perform substantially simultaneous transmission in the same phase at substantially the same time. This feature similarly applies to the other embodiments described later. The synchronization of the processors is performed with the use of a synchronization mechanism by hardware, which is generally provided in a parallel computing system. Even if a parallel computing system does not include a synchronization mechanism, as in the case of a PC (Personal Computer) cluster or the like, the parallel computing system may use a synchronization library usually provided by software.
- The processing of determining the relative coordinate values of the destination processors may be performed by each of the processors every time the data transmission processing is performed. Further, the relative coordinate values of the destination processors previously determined by an arbitrary algorithm may be set in a table or the like of each of the processors, and the relative coordinate values set in the table or the like may be read by each of the processors every time the data transmission processing is performed.
- Second Embodiment
- A parallel computing system according to a second embodiment of the present invention connects a plurality of processors by using an interconnection network. In the present embodiment, the interconnection network is a two-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, the length in a first dimension and the length in a second dimension of the interconnection network are different from each other.
- Each of the processors in the parallel computing system according to the second embodiment is capable of substantially simultaneously transmitting data to a maximum of four processors. The relative coordinates used when data is substantially simultaneously transmitted from each of the processors to a plurality of destination processors are common to all of the processors included in the parallel computing system.
- In the second embodiment, the maximum value of the length in the first dimension and the length in the second dimension of the interconnection network is represented as L. Further, in the relative coordinates of the n-th destination processor with respect to a source processor, the relative coordinate value in the first dimension is represented as Xn, and the relative coordinate value in the second dimension is represented as Yn. If any of the length in the first dimension and the length in the second dimension is less than the L value, however, a transmittable range corresponding to the length in the dimension is preset, and the transmission operation is not performed to relative coordinates exceeding the transmittable range.
- In the present embodiment, each of the processors in the parallel computing system substantially simultaneously transmits data to destination processors having the relative coordinates determined as follows, by using the respective links of the two-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- According to a first relative coordinate value determination algorithm, each of the processors first determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be different from the absolute value of Y1; and
- 2) Set X1 to zero and set the absolute value of Y1 to be different from half the L value, or set Y1 to zero and set the absolute value of X1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinate values of the relative coordinates of three other destination processors as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to the sign-inverted value of Y1.
- 2) In relative coordinates "X3, Y3," set X3 to Y1, and set Y3 to X1.
- 3) In relative coordinates "X4, Y4," set X4 to the sign-inverted value of Y1, and set Y4 to the sign-inverted value of X1.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1," "X2, Y2," "X3, Y3," and "X4, Y4" by using all links of the two-dimensional torus interconnection network with substantially equal loads placed on the links.
- Further, according to a second relative coordinate value determination algorithm, each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be equal to the absolute value of Y1; and
- 2) Set the absolute value of X1 and the absolute value of Y1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinate values of the relative coordinates of three other destination processors as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to the sign-inverted value of Y1.
- 2) In relative coordinates "X3, Y3," set X3 to Y1, and set Y3 to X1.
- 3) In relative coordinates "X4, Y4," set X4 to the sign-inverted value of Y1, and set Y4 to the sign-inverted value of X1.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1," "X2, Y2," "X3, Y3," and "X4, Y4" by using the respective links of the two-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- Further, according to a third relative coordinate value determination algorithm, each of the processors sets the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be equal to the absolute value of Y1; and
- 2) Set the absolute value of X1 and the absolute value of Y1 to half the L value.
- In this case, each of the processors determines the relative coordinate values of the relative coordinates of two other destination processors as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to zero.
- 2) In relative coordinates "X3, Y3," set X3 to zero, and set Y3 to the sign-inverted value of Y1.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to three destination processors located at the above-determined relative coordinates "X1, Y1," "X2, Y2," and "X3, Y3" by using the respective links of the two-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- If the L value is an odd number, each of the processors performs substantially simultaneous transmission to four destination processors by performing the substantially simultaneous transmission the (L-1)2/4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other and performing the substantially simultaneous transmission the (L-1)/2 times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, while changing the relative coordinate values of the destination processors in each of the simultaneous transmissions so that the overlapping of destination processors does not occur.
- Meanwhile, if the L value is an even number, each of the processors performs substantially simultaneous transmission to four destination processors the (L-1)2/4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other, performs substantially simultaneous transmission to four destination processors the (L/2-1) times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, and performs one substantially simultaneous transmission to three destination processors with the absolute value of X1 and the absolute value of Y1 set to be equal to each other and set to half the L value so that the overlapping of destination processors does not occur.
- Third Embodiment
- In a third embodiment of the present invention, a parallel computing system connects a plurality of processors by using an interconnection network. The interconnection network is a two-dimensional mesh, and the communication channels of the interconnection network are determined in dimensional order. Further, each of the processors in the parallel computing system substantially simultaneously transmits data to a maximum of four processors. Herein, the relative coordinates of a plurality of destination processors with respect to an arbitrary processor are common to all of the processors included in the parallel computing system.
- In the present embodiment, the maximum value of the length in a first dimension and the length in a second dimension of the interconnection network is represented as L. Further, in the relative coordinates of the n-th destination processor with respect to a source processor, the relative coordinate value in the first dimension is represented as Xn, and the relative coordinate value in the second dimension is represented as Yn. If the relative coordinates of a destination processor with respect to an arbitrary processor are located outside the interconnection network, however, the transmission from the processor to the destination processor is not performed.
- Herein, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be different from the absolute value of Y1; and
- 2) Set X1 to zero and set the absolute value of Y1 to be different from half the L value, or set Y1 to zero and set the absolute value of X1 to be different from half the L value.
- In this case, the relative coordinate values of the relative coordinates of three other destination processors are determined as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to the sign-inverted value of Y1.
- 2) In relative coordinates "X3, Y3," set X3 to Y1, and set Y3 to X1.
- 3) In relative coordinates "X4, Y4," set X4 to the sign-inverted value of Y1, and set Y4 to the sign-inverted value of X1.
- Each of the processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1," "X2, Y2," "X3, Y3," and "X4, Y4" by using the respective links of the two-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- Then, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be equal to the absolute value of Y1; and
- 2) Set the absolute value of X1 and the absolute value of Y1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinate values of three other destination processors as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to the sign-inverted value of Y1.
- 2) In relative coordinates "X3, Y3," set X3 to Y1, and set Y3 to X1.
- 3) In relative coordinates "X4, Y4," set X4 to the sign-inverted value of Y1, and set Y4 to the sign-inverted value of X1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1," "X2, Y2," "X3, Y3," and "X4, Y4" by using the respective links of the two-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- Further, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1" of a destination processor as follows:
- 1) Set the absolute value of X1 to be equal to the absolute value of Y1; and
- 2) Set the absolute value of X1 and the absolute value of Y1 to half the L value.
- In this case, each of the processors determines the relative coordinate values of other destination processors as follows.
- 1) In relative coordinates "X2, Y2," set X2 to the sign-inverted value of X1, and set Y2 to zero.
- 2) In relative coordinates "X3, Y3," set X3 to zero, and set Y3 to the sign-inverted value of Y1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to three destination processors located at the above-determined relative coordinates "X1, Y1," "X2, Y2," and "X3, Y3" by using the respective links of the two-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- Herein, if the L value is an odd number, an arbitrary processor performs substantially simultaneous transmission to four destination processors by performing the substantially simultaneous transmission the (L-1)2/4 times with the absolute value of X1 and the absolute value of Y1 in the relative coordinates of the destination processor set to be different from each other and performing the simultaneous transmission the (L-1)/2 times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other so that the overlapping of destination processors does not occur.
- Meanwhile, if the L value is an even number, an arbitrary processor performs substantially simultaneous transmission to four destination processors the (L-1)2/4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other, performs substantially simultaneous transmission to four destination processors the (L/2-1) times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, and performs one substantially simultaneous transmission to three destination processors so that the overlapping of destination processors does not occur.
- Fourth Embodiment
- In a parallel computing system according to a fourth embodiment of the present invention, the interconnection network is a three-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, the length in a first dimension, the length in a second dimension, and the length in a third dimension of the interconnection network are substantially equal to one another.
- Each of the processors in the parallel computing system of the present embodiment substantially simultaneously transmits data to a maximum of six processors. Further, the relative coordinates of a plurality of destination processors with respect to an arbitrary processor are common to all of the processors included in the parallel computing system. In the present embodiment, an arbitrary source processor in the parallel computing system simultaneously transmits data to the destination processors in accordance with the following procedure by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- Herein, each of the length in the first dimension, the length in the second dimension, and the length in the third dimension of the interconnection network is represented as L. Further, in the relative coordinates of the n-th destination processor with respect to a source processor, the relative coordinate value in the first dimension is represented as Xn, the relative coordinate value in the second dimension is represented as Yn, and the relative coordinate value in the third dimension is represented as Zn.
- Herein, a case is assumed in which each of the processors sets the relative coordinate values of relative coordinates "X1, Y1, Z1" of an arbitrary destination processor in the following procedure. In this case, at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values, and the relative coordinates correspond to one of the following conditions:
- 1) Set X1 to zero, and set one of the absolute value of Y1 and the absolute value of Z1 to be different from half the L value;
- 2) Set Y1 to zero, and set one of the absolute value of X1 and the absolute value of Z1 to be different from half the L value;
- 3) Set Z1 to zero, and set one of the absolute value of X1 and the absolute value of Y1 to be different from half the L value;
- 4) Set X1 and Y1 to zero, and set the absolute value of Z1 to be different from half the L value;
- 5) Set X1 and Z1 to zero, and set the absolute value of Y1 to be different from half the L value; or
- 6) Set Y1 and Z1 to zero, and set the absolute value of X1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinates of five other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, set Y2 to the sign-inverted value of Y1, and set Z2 to the sign-inverted value of Z1.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to Z1, set Y3 to X1, and set Z3 to Y1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 to the sign-inverted value of Z1, set Y4 to the sign-inverted value of X1, and set Z4 to the sign-inverted value of Y1.
- 4) In relative coordinates "X5, Y5, Z5," set X5 to Y1, set Y5 to Z1, and set Z5 to X1.
- 5) In relative coordinates "X6, Y6, Z6," set X6 to the sign-inverted value of Y1, set Y6 to the sign-inverted value of Z1, and set Z6 to the sign-inverted value of X1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to six destination processors located at the respective positions of the above-determined relative coordinates "X1, Y1, Z1," "X2, Y2, Z2," "X3, Y3, Z3," "X4, Y4, Z4," "X5, Y5, Z5," and "X6, Y6, Z6" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- Further, all of the processors perform, at substantially the same timing, simultaneous data transmission to destination processors having the same relative coordinate values.
- Further, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- 1) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be equal to one another; and
- 2) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinates of three other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, set Y2 to the sign-inverted value of Y1, and set Z2 to the sign-inverted value of Z1.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to X1, set Y3 to Y1, and set Z3 to the sign-inverted value of Z1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 to the sign-inverted value of X1, set Y4 to the sign-inverted value of Y1, and set Z4 to Z1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1, Z1," "X2, Y2, Z2," "X3, Y3, Z3," and "X4, Y4, Z4" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links.
- Further, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- 1) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be equal to one another; and
- 2) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to half the L value.
- In this case, each of the processors determines the relative coordinates of six other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, and set Y2 and Z2 to zero.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to zero, set Y3 to the sign-inverted value of Y1, and set Z3 to the sign-inverted value of Z1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 and Z4 to zero, and set Y4 to Y1.
- 4) In relative coordinates "X5, Y5, Z5," set X5 to X1, set Y5 to zero, and set Z5 to Z1.
- 5) In relative coordinates "X6, Y6, Z6," set X6 and Y6 to zero, and set Z6 to the sign-inverted value of Z1.
- 6) In relative coordinates "X7, Y7, Z7," set X7 to the sign-inverted value of X1, set Y7 to the sign-inverted value of Y1, and set Z7 to zero.
- Each of all processors in the parallel computing system performs, as the first simultaneous transmission, substantially simultaneous data transmission to the first destination processor corresponding to the relative coordinates "X1, Y1, Z1," the second destination processor corresponding to the relative coordinates "X2, Y2, Z2," and the third destination processor corresponding to the relative coordinates "X3, Y3, Z3" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links. Then, each of the source processors performs, as the second simultaneous transmission, substantially simultaneous data transmission to the fourth destination processor corresponding to the relative coordinates "X4, Y4, Z4," the fifth destination processor corresponding to the relative coordinates "X5, Y5, Z5," the sixth destination processor corresponding to the relative coordinates "X6, Y6, Z6," and the seventh destination processor corresponding to the relative coordinates "X7, Y7, Z7" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links. That is, in the present example, the data transmission to seven destination processors in total is performed in two sessions.
- The parallel computing system according to the present embodiment determines the relative coordinates of the destination processors by combining, as required, the above-described three types of relative coordinate value determination algorithms, and performs the substantially simultaneous data transmission to the destination processors.
- Herein, if the L value is an odd number, an arbitrary processor performs substantially simultaneous transmission to six destination processors the (L3-4L+3)/4 times, and performs substantially simultaneous transmission to four destination processors the L-1 times such that the overlapping of destination processors does not occur.
- Meanwhile, if the L value is an even number, an arbitrary processor performs simultaneous transmission to six destination processors the (L3-4L+1)/4 times, performs substantially simultaneous transmission to four destination processors the L-2 times, and performs substantially simultaneous transmission to seven destination processors with one substantially simultaneous transmission to three destination processors and one substantially simultaneous transmission to four destination processors so that the overlapping of destination processors does not occur.
- Fifth Embodiment
- A parallel computing system according to a fifth embodiment of the present invention connects a plurality of processors by using an in interconnection network. The interconnection network according to the fifth embodiment is a three-dimensional torus, and the communication channels of the interconnection network are determined in dimensional order. Further, at least one of the length in a first dimension, the length in a second dimension, and the length in a third dimension of the interconnection network is different from the lengths in the other dimensions. Further, each of all processors in the parallel computing system substantially simultaneously transmits data to a maximum of six processors. The relative coordinates of a plurality of destination processors used when data is substantially simultaneously transmitted from an arbitrary processor to the destination processors are common to all of the processors included in the parallel computing system.
- Herein, the maximum value of the length in the first dimension, the length in the second dimension, and the length in the third dimension of the interconnection network is represented as L. Further, in the relative coordinates of the n-th destination processor with respect to a source processor, the relative coordinate value in the first dimension is represented as Xn, the relative coordinate value in the second dimension is represented as Yn, and the relative coordinate value in the third dimension is represented as Zn. If any of the length in the first dimension, the length in the second dimension, and the length in the third dimension is less than the L value, however, a transmittable range corresponding to the length in the dimension is preset, and the transmission processing is not performed to a processor located at relative coordinates exceeding the transmittable range.
- Herein, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows.
- Herein, if at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values,
- 1) Set X1 to zero, and set one of the absolute value of Y1 and the absolute value of Z1 to be different from half the L value,
- 2) Set Y1 to zero, and set one of the absolute value of X1 and the absolute value of Z1 to be different from half the L value,
- 3) Set Z1 to zero, and set one of the absolute value of X1 and the absolute value of Y1 to be different from half the L value,
- 4) Set X1 and Y1 to zero, and set the absolute value of Z1 to be different from half the L value,
- 5) Set X1 and Z1 to zero, and set the absolute value of Y1 to be different from half the L value, or
- 6) Set Y1 and Z1 to zero, and set the absolute value of X1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinates of five other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, set Y2 to the sign-inverted value of Y1, and set Z2 to the sign-inverted value of Z1.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to Z1, set Y3 to X1, and set Z3 to Y1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 to the sign-inverted value of Z1, set Y4 to the sign-inverted value of X1, and set Z4 to the sign-inverted value of Y1.
- 4) In relative coordinates "X5, Y5, Z5," set X5 to Y1, set Y5 to Z1, and set Z5 to X1.
- 5) In relative coordinates "X6, Y6, Z6," set X6 to the sign-inverted value of Y1, set Y6 to the sign-inverted value of Z1, and set Z6 to the sign-inverted value of X1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to six destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X6, Y6, Z6" by using the respective links of the three-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- Further, it is now assumed that each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- 1) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be equal to one another; and
- 2) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinates of three other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, set Y2 to the sign-inverted value of Y1, and set Z2 to the sign-inverted value of Z1.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to X1, set Y3 to Y1, and set Z3 to the sign-inverted value of Z1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 to the sign-inverted value of X1, set Y4 to the sign-inverted value of Y1, and set Z4 to Z1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X4, Y4, Z4" by using the respective links of the three-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- Meanwhile, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- 1) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be equal to one another; and
- 2) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to half the L value.
- In this case, each of the processors determines the relative coordinates of six other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, and set Y2 and Z2 to zero.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to zero, set Y3 to the sign-inverted value of Y1, and set Z3 to the sign-inverted value of Z1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 and Z4 to zero, and set Y4 to Y1.
- 4) In relative coordinates "X5, Y5, Z5," set X5 to X1, set Y5 to zero, and set Z5 to Z1.
- 5) In relative coordinates "X6, Y6, Z6," set X6 and Y6 to zero, and set Z6 to the sign-inverted value of Z1.
- 6) In relative coordinates "X7, Y7, Z7," set X7 to the sign-inverted value of X1, set Y7 to the sign-inverted value of Y1, and set Z7 to zero.
- Each of all processors in the parallel computing system performs, as the first simultaneous transmission, substantially simultaneous data transmission to the first destination processor corresponding to the relative coordinates "X1, Y1, Z1," the second destination processor corresponding to the relative coordinates "X2, Y2, Z2," and the third destination processor corresponding to the relative coordinates "X3, Y3, Z3" by using all links of the three-dimensional torus interconnection network with substantially equal loads placed on the links. Then, each of the source processors performs, as the second simultaneous transmission, substantially simultaneous data transmission to the fourth destination processor corresponding to the relative coordinates "X4, Y4, Z4," the fifth destination processor corresponding to the relative coordinates "X5, Y5, Z5," the sixth destination processor corresponding to the relative coordinates "X6, Y6, Z6," and the seventh destination processor corresponding to the relative coordinates "X7, Y7, Z7" by using the respective links of the three-dimensional torus interconnection network with a load of a specified value or less placed on each of the links.
- The parallel computing system according to the present embodiment determines the relative coordinates of the destination processors by combining, as required, the above-described three types of relative coordinate value determination algorithms, and performs the substantially simultaneous data transmission to the destination processors.
- Herein, if the L value is an odd number, each of the processors performs substantially simultaneous transmission to six destination processors the (L3-4L+3)/4 times, and performs substantially simultaneous transmission to four destination processors the L-1 times so that the overlapping of destination processors does not occur.
- Further, if the L value is an even number, each of the processors performs substantially simultaneous transmission to six destination processors the (L3-4L+1)/4 times, performs substantially simultaneous transmission to four destination processors the L-2 times, and performs substantially simultaneous transmission to seven destination processors with one substantially simultaneous transmission to three destination processors and one substantially simultaneous transmission to four destination processors so that the overlapping of destination processors does not occur.
- Sixth Embodiment
- A parallel computing system according to a sixth embodiment of the present invention connects a plurality of processors by using an interconnection network. The interconnection network is a three-dimensional mesh, and the communication channels of the interconnection network are determined in dimensional order. Further, each of all processors in the parallel computing system substantially simultaneously transmits data to a maximum of six processors. The relative coordinates of a plurality of destination processors with respect to each of the processors are common to all of the processors included in the parallel computing system.
- Herein, the maximum value of the length in a first dimension, the length in a second dimension, and the length in a third dimension of the interconnection network is represented as L. Further, in the relative coordinates of the n-th destination processor with respect to a source processor, the relative coordinate value in the first dimension is represented as Xn, the relative coordinate value in the second dimension is represented as Yn, and the relative coordinate value in the third dimension is represented as Zn. If a destination processor is located outside the interconnection network, however, the transmission to the destination processor is not performed.
- Each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows.
- In this case, each of the processors determines the relative coordinate values so that at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values, and that the relative coordinate values correspond to one of the following conditions:
- 1) Set X1 to zero, and set one of the absolute value of Y1 and the absolute value of Z1 to be different from half the L value;
- 2) Set Y1 to zero, and set one of the absolute value of X1 and the absolute value of Z1 to be different from half the L value;
- 3) Set Z1 to zero, and set one of the absolute value of X1 and the absolute value of Y1 to be different from half the L value;
- 4) Set X1 and Y1 to zero, and set the absolute value of Z1 to be different from half the L value;
- 5) Set X1 and Z1 to zero, and set the absolute value of Y1 to be different from half the L value; or
- 6) Set Y1 and Z1 to zero, and set the absolute value of X1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinates of five other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, set Y2 to the sign-inverted value of Y1, and set Z2 to the sign-inverted value of Z1.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to Z1, set Y3 to X1, and set Z3 to Y1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 to the sign-inverted value of Z1, set Y4 to the sign-inverted value of X1, and set Z4 to the sign-inverted value of Y1.
- 4) In relative coordinates "X5, Y5, Z5," set X5 to Y1, set Y5 to Z1, and set Z5 to X1.
- 5) In relative coordinates "X6, Y6, Z6," set X6 to the sign-inverted value of Y1, set Y6 to the sign-inverted value of Z1, and set Z6 to the sign-inverted value of X1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to six destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X6, Y6, Z6" by using the respective links of the three-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- Further, each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- 1) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be equal to one another; and
- 2) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be different from half the L value.
- In this case, each of the processors determines the relative coordinates of three other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, set Y2 to the sign-inverted value of Y1, and set Z2 to the sign-inverted value of Z1.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to X1, set Y3 to Y1, and set Z3 to the sign-inverted value of Z1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 to the sign-inverted value of X1, set Y4 to the sign-inverted value of Y1, and set Z4 to Z1.
- Each of all processors in the parallel computing system substantially simultaneously transmits data to four destination processors located at the above-determined relative coordinates "X1, Y1, Z1" to "X4, Y4, Z4" by using the respective links of the three-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- Further, it is now assumed that each of the processors determines the relative coordinate values of relative coordinates "X1, Y1, Z1" of a destination processor as follows:
- 1) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to be equal to one another; and
- 2) Set the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 to half the L value.
- In this case, each of the processors determines the relative coordinate values of six other destination processors as follows.
- 1) In relative coordinates "X2, Y2, Z2," set X2 to the sign-inverted value of X1, and set Y2 and Z2 to zero.
- 2) In relative coordinates "X3, Y3, Z3," set X3 to zero, set Y3 to the sign-inverted value of Y1, and set Z3 to the sign-inverted value of Z1.
- 3) In relative coordinates "X4, Y4, Z4," set X4 and Z4 to zero, and set Y4 to Y1.
- 4) In relative coordinates "X5, Y5, Z5," set X5 to X1, set Y5 to zero, and set Z5 to Z1.
- 5) In relative coordinates "X6, Y6, Z6," set X6 and Y6 to zero, and set Z6 to the sign-inverted value of Z1.
- 6) In relative coordinates "X7, Y7, Z7," set X7 to the sign-inverted value of X1, set Y7 to the sign-inverted value of Y1, and set Z7 to zero.
- Each of all processors in the parallel computing system performs, as the first simultaneous transmission, substantially simultaneous data transmission to the first destination processor corresponding to the relative coordinates "X1, Y1, Z1," the second destination processor corresponding to the relative coordinates "X2, Y2, Z2," and the third destination processor corresponding to the relative coordinates "X3, Y3, Z3" by using all links of the three-dimensional mesh interconnection network with substantially equal loads placed on the links. Then, each of the source processors performs, as the second simultaneous transmission, substantially simultaneous data transmission to the fourth destination processor corresponding to the relative coordinates "X4, Y4, Z4," the fifth destination processor corresponding to the relative coordinates "X5, Y5, Z5," the sixth destination processor corresponding to the relative coordinates "X6, Y6, Z6," and the seventh destination processor corresponding to the relative coordinates "X7, Y7, Z7" by using the respective links of the three-dimensional mesh interconnection network with a load of a specified value or less placed on each of the links.
- Herein, if the L value is an odd number, each of the processors performs substantially simultaneous transmission to six destination processors the (L3-4L+3)/4 times, and performs substantially simultaneous transmission to four destination processors the L-1 times so that the overlapping of destination processors does not occur.
- Meanwhile, if the L value is an even number, each of the processors performs substantially simultaneous transmission to six destination processors the (L3-4L+1)/4 times, performs substantially simultaneous transmission to four destination processors the L-2 times, and performs substantially simultaneous transmission to seven destination processors with one substantially simultaneous transmission to three destination processors and one substantially simultaneous transmission to four destination processors so that the overlapping of destination processors does not occur.
- In the above-described example of three-dimensional torus interconnection network, all of the processors in the parallel computing system are synchronized between a substantially simultaneous transmission and the next substantially simultaneous transmission. Accordingly, even if asymmetry occurs in the loads on the links of the three-dimensional torus interconnection network, all of the processors perform substantially the same simultaneous transmission at substantially the same time.
- In the all-to-all communication method according to the embodiments described above, each of the processors transmits and receives a plurality of messages in parallel in accordance with a plurality of communication controllers provided in the corresponding node. In this process, the processors serving as communication destinations are arranged in order. Thereby, the relative coordinates of the destination processors with respect to each of nodes are set to be the same among all of the nodes, and the number of inter-processor communications routed through all links between network routers of the system is equalized among the links.
- Seventh Embodiment
- In a parallel computing system using a two-dimensional torus which connects
nodes 1 each configured to include aprocessor 2, fourcommunication controllers 3, and anetwork router 4, as illustrated inFig. 4 , the number of inter-processor communications routed through the respective links is equalized among the links in accordance with the following algorithms. -
Figs. 1A to 1D are diagrams illustrating an example of a two-dimensional torus topology. The two-dimensional torus topology illustrated inFigs. 1A to 1D has two sides having the same length corresponding to an odd number. - In the two-dimensional torus topology of
Figs. 1A to 1D , the length of each of the sides is represented as 2n+1, wherein "n" represents a natural number. Further, the star illustrated inFigs. 1A to 1D indicates a source processor. - In the two-dimensional torus topology according to the present embodiment, for all values of natural numbers i and j represented as 0<j<i≤n, each of all processors first performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, j), (-i, -j), (j, i), and (-j, -i) with respect to the processor (
Fig. 1A ). - Then, each of the processors performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, -j), (-i, j), (-j, i), and (j, -i) with respect to the processor (
Fig. 1B ). - Further, for all values of a natural number i represented as 0<i≤n, each of the processors performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, 0), (-i, 0), (0, i), and (0, -i) with respect to the processor (
Fig. 1C ). - Then, each of the processors performs substantially simultaneous communication with four processors respectively located at relative coordinates (i, i), (-i, -i), (-i, i), and (i, -i) with respect to the processor (
Fig. 1D ). - Eighth Embodiment
-
Figs. 2A and 2B illustrate a two-dimensional torus topology which has two sides having the same length corresponding to an even number. Also inFigs. 2A and 2B , the star indicates a source processor. - In the example of
Figs. 2A and 2B , the length of each of the sides is represented as 2n+2. In a similar manner as in the example of two-dimensional torus topology illustrated inFigs. 1A to 1D , in which the topology has two sides having the same length corresponding to an odd number, an arbitrary processor communicates with a processor having a value of at least -n and at most n as the relative coordinate thereof on each of the coordinate axes with respect to the arbitrary processor. Then, in accordance with the following combinations, the arbitrary processor communicates with the remaining processors having a value of -n-1 or n+1 as the relative coordinate thereof on at least one of the coordinate axes with respect to the arbitrary processor. - For all values of a natural number i represented as 0<i≤n, each of all processors first performs substantially simultaneous communication with four processors respectively located at relative coordinates (n+1, i), (-n-1, -i), (i, n+1), and (-i, -n-1) with respect to the processor (
Fig. 2A ). - Then, each of all processors performs substantially simultaneous communication with three processors respectively located at relative coordinates (n+1, 0), (0, n+1), and (-n-1, -n-1) with respect to the processor (
Fig. 2B ). - Ninth Embodiment
- In a parallel computing system using a three-dimensional torus, in which each of the processors has six communication controllers, the number of inter-processor communications routed through all links is equalized among the links in accordance with the following algorithms.
- The following description will be made of an example of a three-dimensional torus topology which has three sides having the same length corresponding to an odd number. Herein, the length of each of the sides is represented as 2n+1. For all values of natural numbers i, j, and k represented as 0<k<j<i≤n, each of the processors first performs simultaneous communication with six processors in accordance with the following combinations of relative coordinates. Here, "i", "J" and "k" denotes coordinate values of X axis, Y axis and Z axis of a three-dimensional torus topology. In the following, six sets of relative coordinates form one group. This feature similarly applies to the subsequent examples.
- 1) (i, j, k), (-i, -j, -k), (k, i, j), (-k, -i, -j), (j, k, i), (-j, -k, -i)
- 2) (i, j, -k), (-i, -j, k), (-k, i, j), (k, -i, -j), (j, -k, i), (-j, k, -i)
- 3) (i, -j, k), (-i, j, -k), (k, i, -j), (-k, -i, j), (-j, k, i), (j, -k, -i)
- 4) (i, -j, -k), (-i, j, k), (-k, i, -j), (k, -i, j), (-j, -k, i), (j, k, -i)
- 5) (i, k, j), (-i, -k, -j), (j, i, k), (-j, -i, -k), (k, j, i), (-k, -j, -i)
- 6) (i, k, -j), (-i, -k, j), (-j, i, k), (j, -i, -k), (k, -j, i), (-k, j, -i)
- 7) (i, -k, j), (-i, k, -j), (j, i, -k), (-j, -i, k), (-k, j, i), (k, -j, -i)
- 8) (i, -k, -j), (-i, k, j), (-j, i, -k), (j, -i, k), (-k, -j, i), (k, j, -i)
- Then, for all values of natural numbers i and j represented as 0<j<i≤n, each of the processors performs substantially simultaneous communication with six processors corresponding to the following combinations of relative coordinates with respect to the processor. Also in the following example, six sets of relative coordinates form one group.
- 1) (i, i, j), (-i, -i, -j), (j, i, i), (-j, -i, -i), (i, j, i), (-i, -j, -i)
- 2) (i, i, -j), (-i, -i, j), (-j, i, i), (j, -i, -i), (i, -i, i), (-i, j, -i)
- 3) (i, -i, j), (-i, i, -j), (j, i, -i), (-j, -i, i), (-i, j, i), (i, -j, -i)
- 4) (i, -i, -j), (-i, i, j), (-i, i, -i), (j, -i, i), (-i, -j, i), (i, j, -i)
- 5) (j, j, i), (-j, -j, -i), (i, j, i), (-i, -j, -j), (j, i, i), (-j, -i, -j)
- 6) (j, j, -i), (-j, -j, i), (-i, j, j), (i, -j, -j), (j, -i, j), (-j, i, -j)
- 7) (j, -j, i), (-j, j, -i), (i, j, -j), (-i, -j, j), (-j, i, j), (j, -i, -j)
- 8) (j, -j, -i), (-j, j, i), (-i, j, -j), (i, -j, j), (-j, -i, j), (j, i, -j)
- 9) (0, i, j), (0, -i, -j), (j, 0, i), (-j, 0, -i), (i, j, 0), (-i, -j, 0)
- 10) (0, i, -j), (0, -i, j), (-j, 0, i), (j, 0, -i), (i, -j, 0), (-i, j, 0)
- 11) (0, j, i), (0, -j, -i), (i, 0, j), (-i, 0, -j), (j, i, 0), (-j, -i, 0)
- 12) (0, j, -i), (0, -j, i), (-i, 0, j), (i, 0, -j), (j, -i, 0), (-j, i, 0)
- Further, for all values of a natural number i represented as 0<i≤n, each of the processors performs substantially simultaneous communication with a plurality of processors corresponding to the following combinations of relative coordinates with respect to the processor.
- 1) (0, i, i), (0, -i, -i), (i, 0, i), (-i, 0, -i), (i, i, 0), (-i, -i, 0)
- 2) (i, 0, 0), (-i, 0, 0), (0, 0, i), (0, 0, -i), (0, i, 0), (0, -i, 0)
- 3) (i, i, i), (-i, -i, -i), (i, i, -i), (-i, -i, i)
- 4) (i, -i, i), (-i, i, -i), (i, -i, -i), (-i, i, i)
- Tenth Embodiment
- Description will be made of a three-dimensional torus topology which has three sides having the same length corresponding to an even number. In the present example, the length of each of the sides is represented as 2n+2. In a similar manner as in the example of three-dimensional torus topology, in which the topology has three sides having the same length corresponding to an odd number, an arbitrary processor communicates with a processor having a value of at least -n and at most n as each of the relative coordinates thereof on the respective coordinate axes (x-axis, y-axis, and z-axis) with respect to the arbitrary processor. Then, in accordance with the following combinations, the arbitrary processor communicates with, among the remaining processors, the processors having a value of -n-1 or n+1 as the relative coordinate thereof on at least one of the three coordinate axes.
- Subsequently, for all values of natural numbers i and j represented as 0<j<i≤n, each of the processors performs substantially simultaneous communication with six processors corresponding to the following combinations of relative coordinates with respect to the processor.
- 1) (n+1, i, j), (-n-1, -i, -j), (j, n+1, i), (-j, -n-1, -i), (i, j, n+1), (-i, -j, -n-1)
- 2) (n+1, i, -j), (-n-1, -i, j), (-j, n+1, i), (j, -n-1, -i), (i, -j, n+1), (-i, j, -n-1)
- 3) (n+1, j, i), (-n-1, -j, -i), (i, n+1, j), (-i, -n-1, -j), (j, i, n+1), (-j, -i, -n-1)
- 4) (n+1, -j, i), (-n-1, j, -i), (i, n+1, -j), (-i, -n-1, j), (-j, i, n+1), (j, -i, -n-1)
- Further, for all values of a natural number i represented as 0<i≤n, each of the processors performs substantially simultaneous communication with six processors corresponding to the following combinations of relative coordinates with respect to the processor.
- 1) (n+1, i, i), (-n-1, -i, -i), (i, n+1, i), (-i, -n-1, -i), (i, i, n+1), (-i, -i, -n-1)
- 2) (n+1, i, -i), (-n-1, -i, i), (-i, n+1, i), (i, -n-1, -i), (i, -i, n+1), (-i, i, -n-1)
- 3) (n+1, i, 0), (-n-1, -i, 0), (0, n+1, i), (0, -n-1, -i), (i, 0, n+1), (-i, 0, -n-1)
- 4) (n+1, 0, i), (-n-1, 0, -i), (i, n+1, 0), (-i, -n-1, 0), (0, i, 11+1), (0, -i, -n-1)
- 5) (i, n+1, n+1), (-i, -n-1, -n-1), (n+1, i, n+1), (-n-1, -i, -n-1), (n+1, n+1, i), (-n-1, -n-1, -i)
- Finally, each of the processors performs substantially simultaneous communication with a plurality of processors corresponding to the following combinations of relative coordinates with respect to the processor.
- 1) (n+1, n+1, 0), (0, 0, n+1), (-n-1, 0, -n-1), (0, -n-1, 0)
- 2) (0, n+1, n+1), (n+1, 0, 0), (-n-1, -n-1, -n-1)
- In the above-described embodiments, the processing in which each of the processors determines the destination processors is performed as a program recorded in a recording medium is executed by each of the processors. The recording medium for recording the program may include a storage device, e.g., as a magnetic disk device included in a node provided with the processor. Further, the program may be stored in a portable recording medium, e.g., an optical disk and a magnetic disk, read from the portable recording medium with the use of a storage medium reading device provided to the node or the like, and executed by the processor. Various types of semiconductor recording devices may be used as the recording medium for recording the program.
- All examples and conditional language recited herein are intended for pedagogical purposes to aid the reader in understanding the principles of the invention and the concepts contributed by the inventor to furthering the art, and are to be construed as being without limitation to such specifically recited examples and conditions, nor does the organization of such examples in the specification relate to a showing of the superiority and inferiority of the invention. Although the embodiment(s) of the present invention(s) has (have) been described in detail, it should be understood that the various changes, substitutions, and alterations could be made hereto without departing from the spirit and scope of the invention.
Claims (9)
- A parallel computing system comprising:a plurality of processors multi-dimensionally commented by an interconnection network, whereineach of the processors in the parallel computing system determines, in dimensional order, communication channels to other processors in the interconnection network,each of the processors sets, as relative coordinates of destination processors with respect to the plurality of processors in data communications performed at a same timing, relative coordinates common to all of the processors, andeach of the processors performs data communications with destination processors having the set relative coordinates.
- The parallel computing system according to claim 1, wherein the plurality of processors in the parallel computing system is configured to simultaneously transmit data to a maximum of four processors,
wherein, when L represents the maximum value of the lengths in respective dimensions of the interconnection network and Xn and Yn respectively represent the relative coordinate value in a first dimension and the relative coordinate value in a second dimension of the relative coordinates of the n-th destination processor with respect to a source processor, the plurality of processors perform,
first transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be different from the absolute value of Y1, and in which X1 is set to zero and the absolute value of Y1 is set to be different from half the L value or Y1 is set to zero and the absolute value of X1 is set to be different from half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to the sign-inverted value of Y1, relative coordinates (X3, Y3) in which X3 is set to Y1 and Y3 is set to X1, and relative coordinates (X4, Y4) in which X4 is set to the sign-inverted value of Y1 and Y4 is set to the sign-inverted value of X1,
second transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be equal to the absolute value of Y1, and in which the absolute value of X1 and the absolute value of Y1 are set to be different from half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to the sign-inverted value of Y1, relative coordinates (X3, Y3) in which X3 is set to Y1 and Y3 is set to X1, and relative coordinates (X4, Y4) in which X4 is set to the sign-inverted value of Y1 and Y4 is set to the sign-inverted value of X1, and
third transmission processing of transmitting data to three destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be equal to the absolute value of Y1, and in which the absolute value of X1 and the absolute value of Y1 are set to half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to zero, and relative coordinates (X3, Y3) in which X3 is set to zero and Y3 is set to the sign-inverted value of Y1, and
wherein the plurality of processors in the parallel computing system performs, at the same timing, data communications using a same transmission processing with destination processors having the same relative coordinates. - The parallel computing system according to claim 1, wherein the plurality of processors in the parallel computing system is configured to simultaneously transmit data to a maximum of four processors,
wherein, when the interconnection network is a two-dimensional torus and is different in length between a first dimension and a second dimension thereof, and when L represents the maximum value of the length in the first dimension and the length in the second dimension of the interconnection network and Xn and Yn respectively represent the relative coordinate value in the first dimension and the relative coordinate value in the second dimension of the relative coordinates of an n-th destination processor with respect to a source processor, the plurality of processors perform,
first transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be different from the absolute value of Y1, and in which X1 is set to zero and the absolute value of Y1 is set to be different from half the L value or Y1 is set to zero and the absolute value of X1 is set to be different from half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to the sign-inverted value of Y1, relative coordinates (X3, Y3) in which X3 is set to Y1 and Y3 is set to X1, and relative coordinates (X4, Y4) in which X4 is set to the sign-inverted value of Y1 and Y4 is set to the sign-inverted value of X1,
second transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be equal to the absolute value of Y1, and in which the absolute value of X1 and the absolute value of Y1 are set to be different from half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to the sign-inverted value of Y1, relative coordinates (X3, Y3) in which X3 is set to Y1 and Y3 is set to X1, and relative coordinates (X4, Y4) in which X4 is set to the sign-inverted value of Y1 and Y4 is set to the sign-inverted value of X1, and
third transmission processing of transmitting data to three destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be equal to the absolute value of Y1, and in which the absolute value of X1 and the absolute value of Y1 are set to half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to zero, and relative coordinates (X3, Y3) in which X3 is set to zero and Y3 is set to the sign-inverted value of Y1, and
wherein the plurality of processors in the parallel computing system perform, at the same timing, data communications using a same transmission processing with destination processors having the same relative coordinates. - The parallel computing system according to claim 1, wherein each of the processors in the parallel computing system is configured to simultaneously transmit data to a maximum of four processors,
wherein, when the interconnection network is a two-dimensional mesh, and when L represents the maximum value of the length in a first dimension and the length in a second dimension of the interconnection network and Xn and Yn respectively represent the relative coordinate value in the first dimension and the relative coordinate value in the second dimension of the relative coordinates of an n-th destination processor with respect to a source processor, the plurality of processors perform,
first transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be different from the absolute value of Y1, and in which X1 is set to zero and the absolute value of Y1 is set to be different from half the L value or Y1 is set to zero and the absolute value of X1 is set to be different from half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to the sign-inverted value of Y1, relative coordinates (X3, Y3) in which X3 is set to Y1 and Y3 is set to X1, and relative coordinates (X4, Y4) in which X4 is set to the sign-inverted value of Y1 and Y4 is set to the sign-inverted value of X1,
second transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be equal to the absolute value of Y1, and in which the absolute value of X1 and the absolute value of Y1 are set to be different from half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to the sign-inverted value of Y1, relative coordinates (X3, Y3) in which X3 is set to Y1 and Y3 is set to X1, and relative coordinates (X4, Y4) in which X4 is set to the sign-inverted value of Y1 and Y4 is set to the sign-inverted value of X1, and
third transmission processing of transmitting data to three destination processors located at the respective positions of relative coordinates (X1, Y1) in which the absolute value of X1 is set to be equal to the absolute value of Y1, and in which the absolute value of X1 and the absolute value of Y1 are set to half the L value, relative coordinates (X2, Y2) in which X2 is set to the sign-inverted value of X1 and Y2 is set to zero, and relative coordinates (X3, Y3) in which X3 is set to zero and Y3 is set to the sign-inverted value of Y1, and
wherein the plurality of processors in the parallel computing system performs, at the same timing, data communications using a same transmission processing with destination processors having the same relative coordinates. - The parallel computing system according to claim 2, wherein, when the L value is an odd number, the plurality of processors performs simultaneous transmission of data to four destination processors by performing simultaneous transmission to four destination processors the (L-1)2/4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other and performing simultaneous transmission to four destination processors the (L-1)/2 times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, while changing the relative coordinate values in each of the simultaneous transmissions, and
wherein, when the L value is an even number, the plurality of processors performs simultaneous transmission to four destination processors the (L-1)2/4 times with the absolute value of X1 and the absolute value of Y1 set to be different from each other, performs simultaneous transmission to four destination processors the (L/2-1) times with the absolute value of X1 and the absolute value of Y1 set to be equal to each other, and performs one simultaneous transmission to three destination processors with the absolute value of X1 and the absolute value of Y1 set to be equal to each other and set to half the L value, while changing the relative coordinate values in each of the simultaneous transmissions. - The parallel computing system according to claim 1, wherein, when the interconnection network is a three-dimensional torus and is equal in length among a first dimension, a second dimension, and a third dimension thereof, and when L represents the length in each of the dimensions of the interconnection network and Xn, Yn, and Zn respectively represent the relative coordinate value in the first dimension, the relative coordinate value in the second dimension, and the relative coordinate value in the third dimension of the relative coordinates of an n-th destination processor with respect to a source processor, the plurality of processors perform,
first transmission processing of transmitting data to six destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values, and in which the relative coordinates correspond to one of a conditions of 1) X1 is set to zero and one of the absolute value of Y1 and the absolute value of Z1 is set to be different from half the L value, 2) Y1 is set to zero and one of the absolute value of X1 and the absolute value of Z1 is set to be different from half the L value, 3) Z1 is set to zero and one of the absolute value of X1 and the absolute value of Y1 is set to be different from half the L value, 4) X1 and Y1 are set to zero and the absolute value of Z1 is set to be different from half the L value, 5) X1 and Z1 are set to zero and the absolute value of Y1 is set to be different from half the L value, and 6) Y1 and Z1 are set to zero and the absolute value of X1 is set to be different from half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1, Y2 is set to the sign-inverted value of Y1, and Z2 is set to the sign-inverted value of Z1, relative coordinates (X3, Y3, Z3) in which X3 is set to Z1, Y3 is set to X1, and Z3 is set to Y1, relative coordinates (X4, Y4, Z4) in which X4 is set to the sign-inverted value of Z1, Y4 is set to the sign-inverted value of X1, and Z4 is set to the sign-inverted value of Y1, relative coordinates (X5, Y5, Z5) in which X5 is set to Y1, Y5 is set to Z1, and Z5 is set to X1, and relative coordinates (X6, Y6, Z6) in which X6 is set to the sign-inverted value of Y1, Y6 is set to the sign-inverted value of Z1, and Z6 is set to the sign-inverted value of X1,
second transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be equal to one another, and in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be different from half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1, Y2 is set to the sign-inverted value of Y1, and Z2 is set to the sign-inverted value of Z1, relative coordinates (X3, Y3, Z3) in which X3 is set to X1, Y3 is set to Y1, and Z3 is set to the sign-inverted value of Z1, and relative coordinates (X4, Y4, Z4) in which X4 is set to the sign-inverted value of X1, Y4 is set to the sign-inverted value of Y1, and Z4 is set to Z1, and
third transmission processing of transmitting data to seven destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be equal to one another, and in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1 and Y2 and Z2 are set to zero, relative coordinates (X3, Y3, Z3) in which X3 is set to zero, Y3 is set to the sign-inverted value of Y1, and Z3 is set to the sign-inverted value of Z1, relative coordinates (X4, Y4, Z4) in which X4 and Z4 are set to zero and Y4 is set to Y1, relative coordinates (X5, Y5, Z5) in which X5 is set to X1, Y5 is set to zero, and Z5 is set to Z1, relative coordinates (X6, Y6, Z6) in which X6 and Y6 are set to zero and Z6 is set to the sign-inverted value of Z1, and relative coordinates (X7, Y7, Z7) in which X7 is set to the sign-inverted value of X1, Y7 is set to the sign-inverted value of Y1, and Z7 is set to zero, and
wherein the plurality of processors in the parallel computing system performs, at the same timing, data communications using a same transmission processing with destination processors having the same relative coordinates. - The parallel computing system according to claim 1, wherein, when the interconnection network is a three-dimensional torus with one of a length in a first dimension, a length in a second dimension, and a length in a third dimension of the interconnection network different from the other lengths, and when L represents a maximum value of the length in the first dimension, the length in the second dimension, and the length in the third dimension of the interconnection network and Xn, Yn, and Zn respectively represent the relative coordinate value in the first dimension, the relative coordinate value in the second dimension, and the relative coordinate value in the third dimension of the relative coordinates of an n-th destination processor with respect to a source processor, the plurality of processors perform,
first transmission processing of transmitting data to six destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values, and in which the relative coordinates correspond to one of a conditions of 1) X1 is set to zero and one of the absolute value of Y1 and the absolute value of Z1 is set to be different from half the L value, 2) Y1 is set to zero and one of the absolute value of X1 and the absolute value of Z1 is set to be different from half the L value, 3) Z1 is set to zero and one of the absolute value of X1 and the absolute value of Y1 is set to be different from half the L value, 4) X1 and Y1 are set to zero and the absolute value of Z1 is set to be different from half the L value, 5) X1 and Z1 are set to zero and the absolute value of Y1 is set to be different from half the L value, and 6) Y1 and Z1 are set to zero and the absolute value of X1 is set to be different from half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1, Y2 is set to the sign-inverted value of Y1, and Z2 is set to the sign-inverted value of Z1, relative coordinates (X3, Y3, Z3) in which X3 is set to Z1, Y3 is set to X1, and Z3 is set to Y1, relative coordinates (X4, Y4, Z4) in which X4 is set to the sign-inverted value of Z1, Y4 is set to the sign-inverted value of X1, and Z4 is set to the sign-inverted value of Y1, relative coordinates (X5, Y5, Z5) in which X5 is set to Y1, Y5 is set to Z1, and Z5 is set to X1, and relative coordinates (X6, Y6, Z6) in which X6 is set to the sign-inverted value of Y1, Y6 is set to the sign-inverted value of Z1, and Z6 is set to the sign-inverted value of X1,
second transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be equal to one another, and in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be different from half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1, Y2 is set to the sign-inverted value of Y1, and Z2 is set to the sign-inverted value of Z1, relative coordinates (X3, Y3, Z3) in which X3 is set to X1, Y3 is set to Y1, and Z3 is set to the sign-inverted value of Z1, and relative coordinates (X4, Y4, Z4) in which X4 is set to the sign-inverted value of X1, Y4 is set to the sign-inverted value of Y1, and Z4 is set to Z1, and
third transmission processing of transmitting data to seven destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be equal to one another, and in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1 and Y2 and Z2 are set to zero, relative coordinates (X3, Y3, Z3) in which X3 is set to zero, Y3 is set to the sign-inverted value of Y1, and Z3 is set to the sign-inverted value of Z1, relative coordinates (X4, Y4, Z4) in which X4 and Z4 are set to zero and Y4 is set to Y1, relative coordinates (X5, Y5, Z5) in which X5 is set to X1, Y5 is set to zero, and Z5 is set to Z1, relative coordinates (X6, Y6, Z6) in which X6 and Y6 are set to zero and Z6 is set to the sign-inverted value of Z1, and relative coordinates (X7, Y7, Z7) in which X7 is set to the sign-inverted value of X1, Y7 is set to the sign-inverted value of Y1, and Z7 is set to zero, and
wherein the plurality of processors in the parallel computing system performs, at the same timing, data communications using a same transmission processing with destination processors having the same relative coordinates. - The parallel computing system according to claim 1, wherein, when the interconnection network is a three-dimensional mesh, and when L represents a maximum value of a length in a first dimension, a length in a second dimension, and a length in a third dimension of the interconnection network and Xn, Yn, and Zn respectively represent the relative coordinate value in the first dimension, the relative coordinate value in the second dimension, and the relative coordinate value in the third dimension of the relative coordinates of an n-th destination processor with respect to a source processor, the plurality of processors perform,
first transmission processing of transmitting data to six destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which at least one of the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 is different from the other absolute values, and in which the relative coordinates correspond to one of the following conditions of 1) X1 is set to zero and one of the absolute value of Y1 and the absolute value of Z1 is set to be different from half the L value, 2) Y1 is set to zero and one of the absolute value of X1 and the absolute value of Z1 is set to be different from half the L value, 3) Z1 is set to zero and one of the absolute value of X1 and the absolute value of Y1 is set to be different from half the L value, 4) X1 and Y1 are set to zero and the absolute value of Z1 is set to be different from half the L value, 5) X1 and Z1 are set to zero and the absolute value of Y1 is set to be different from half the L value, and 6) Y1 and Z1 are set to zero and the absolute value of X1 is set to be different from half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1, Y2 is set to the sign-inverted value of Y1, and Z2 is set to the sign-inverted value of Z1, relative coordinates (X3, Y3, Z3) in which X3 is set to Z1, Y3 is set to X1, and Z3 is set to Y1, relative coordinates (X4, Y4, Z4) in which X4 is set to the sign-inverted value of Z1, Y4 is set to the sign-inverted value of X1, and Z4 is set to the sign-inverted value of Y1, relative coordinates (X5, Y5, Z5) in which X5 is set to Y1, Y5 is set to Z1, and Z5 is set to X1, and relative coordinates (X6, Y6, Z6) in which X6 is set to the sign-inverted value of Y1, Y6 is set to the sign-inverted value of Z1, and Z6 is set to the sign-inverted value of X1,
second transmission processing of transmitting data to four destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be equal to one another, and in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be different from half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1, Y2 is set to the sign-inverted value of Y1, and Z2 is set to the sign-inverted value of Z1, relative coordinates (X3, Y3, Z3) in which X3 is set to X1, Y3 is set to Y1, and Z3 is set to the sign-inverted value of Z1, and relative coordinates (X4, Y4, Z4) in which X4 is set to the sign-inverted value of X1, Y4 is set to the sign-inverted value of Y1, and Z4 is set to Z1, and
third transmission processing of transmitting data to seven destination processors located at the respective positions of relative coordinates (X1, Y1, Z1) in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to be equal to one another, and in which the absolute value of X1, the absolute value of Y1, and the absolute value of Z1 are set to half the L value, relative coordinates (X2, Y2, Z2) in which X2 is set to the sign-inverted value of X1 and Y2 and Z2 are set to zero, relative coordinates (X3, Y3, Z3) in which X3 is set to zero, Y3 is set to the sign-inverted value of Y1, and Z3 is set to the sign-inverted value of Z1, relative coordinates (X4, Y4, Z4) in which X4 and Z4 are set to zero and Y4 is set to Y1, relative coordinates (X5, Y5, Z5) in which X5 is set to X1, Y5 is set to zero, and Z5 is set to Z1, relative coordinates (X6, Y6, Z6) in which X6 and Y6 are set to zero and Z6 is set to the sign-inverted value of Z1, and relative coordinates (X7, Y7, Z7) in which X7 is set to the sign-inverted value of X1, Y7 is set to the sign-inverted value of Y1, and Z7 is set to zero, and
wherein the plurality of processors in the parallel computing system performs, at the same timing, data communications using a same transmission processing with destination processors having the same relative coordinates. - The parallel computing system according to claim 6, wherein, when the L value is an odd number, each of the processors performs simultaneous transmission to six destination processors the (L3-4L+3)/4 times, and performs simultaneous transmission to four destination processors the L-1 times, while changing the relative coordinate values in each of the simultaneous transmissions, and
wherein, when the L value is an even number, each of the processors performs simultaneous transmission to six destination processors the (L3-4L+1)/4 times, performs simultaneous transmission to four destination processors the L-2 times, and performs one simultaneous transmission to seven destination processors, while changing the relative coordinate values in each of the simultaneous transmissions.
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2009201560A JP5540609B2 (en) | 2009-09-01 | 2009-09-01 | Parallel computing system and communication control program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| EP2302525A1 true EP2302525A1 (en) | 2011-03-30 |
Family
ID=43500980
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| EP10174920A Ceased EP2302525A1 (en) | 2009-09-01 | 2010-09-01 | Parallel computing system and communication control program |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US10430375B2 (en) |
| EP (1) | EP2302525A1 (en) |
| JP (1) | JP5540609B2 (en) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2566977C1 (en) | 2011-09-28 | 2015-10-27 | Тойота Дзидося Кабусики Кайся | Engine control system |
| EP2793141B1 (en) | 2011-12-12 | 2018-02-28 | Toyota Jidosha Kabushiki Kaisha | Engine control device |
| RU2486581C1 (en) * | 2012-07-11 | 2013-06-27 | Открытое акционерное общество "Научно-исследовательский институт "Субмикрон" | Parallel computing circuit with programmable architecture |
| JP6197791B2 (en) * | 2012-07-30 | 2017-09-20 | 日本電気株式会社 | Distributed processing apparatus, distributed processing system, and distributed processing method |
| US9077616B2 (en) | 2012-08-08 | 2015-07-07 | International Business Machines Corporation | T-star interconnection network topology |
| US9055078B2 (en) | 2013-01-10 | 2015-06-09 | International Business Machines Corporation | Token-based flow control of messages in a parallel computer |
| JP2014137732A (en) * | 2013-01-17 | 2014-07-28 | Fujitsu Ltd | Information processing system and control method for information processing system |
| EP2811796A1 (en) * | 2013-06-07 | 2014-12-10 | Stichting Vu-Vumuc | Position-based broadcast protocol and time slot schedule for a wireless mesh network |
| JP6499388B2 (en) | 2013-08-14 | 2019-04-10 | 富士通株式会社 | Parallel computer system, control program for management apparatus, and control method for parallel computer system |
| US20150106589A1 (en) * | 2013-10-16 | 2015-04-16 | REMTCS, Inc. | Small form high performance computing mini hpc |
| US9690734B2 (en) * | 2014-09-10 | 2017-06-27 | Arjun Kapoor | Quasi-optimized interconnection network for, and method of, interconnecting nodes in large-scale, parallel systems |
| US11516087B2 (en) * | 2020-11-30 | 2022-11-29 | Google Llc | Connecting processors using twisted torus configurations |
Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4598400A (en) * | 1983-05-31 | 1986-07-01 | Thinking Machines Corporation | Method and apparatus for routing message packets |
| EP0206580A2 (en) * | 1985-06-04 | 1986-12-30 | Thinking Machines Corporation | Method and apparatus for interconnecting processors in a hyper-dimensional array |
| US5175865A (en) * | 1986-10-28 | 1992-12-29 | Thinking Machines Corporation | Partitioning the processors of a massively parallel single array processor into sub-arrays selectively controlled by host computers |
| EP0132926B1 (en) * | 1983-05-31 | 1993-05-05 | W. Daniel Hillis | Parallel processor |
| EP0544532A2 (en) * | 1991-11-26 | 1993-06-02 | Fujitsu Limited | A parallel computer and its all-to-all communications method |
| US5247694A (en) * | 1990-06-14 | 1993-09-21 | Thinking Machines Corporation | System and method for generating communications arrangements for routing data in a massively parallel processing system |
| US5535408A (en) * | 1983-05-31 | 1996-07-09 | Thinking Machines Corporation | Processor chip for parallel processing system |
| US20060179270A1 (en) * | 2005-02-07 | 2006-08-10 | International Business Machines Corporation | All row, planar fault detection system |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH03116357A (en) * | 1989-09-29 | 1991-05-17 | Fujitsu Ltd | Parallel processing system |
| JPH04235654A (en) | 1991-01-10 | 1992-08-24 | Fujitsu Ltd | Network control system |
| JPH09330304A (en) * | 1996-06-05 | 1997-12-22 | Internatl Business Mach Corp <Ibm> | Method for determining communication schedule between processors |
| JP3709322B2 (en) * | 2000-03-10 | 2005-10-26 | 株式会社日立製作所 | Multidimensional crossbar network and parallel computer system |
| WO2002069168A1 (en) | 2001-02-24 | 2002-09-06 | International Business Machines Corporation | A global tree network for computing structures |
| WO2008114440A1 (en) * | 2007-03-20 | 2008-09-25 | Fujitsu Limited | Unique information group communication program, computer, unique information group communication method, and recording medium |
| JP5369775B2 (en) * | 2009-03-11 | 2013-12-18 | 富士通株式会社 | N-dimensional torus type distributed processing system, collective communication method and collective communication program |
-
2009
- 2009-09-01 JP JP2009201560A patent/JP5540609B2/en active Active
-
2010
- 2010-08-31 US US12/872,338 patent/US10430375B2/en active Active
- 2010-09-01 EP EP10174920A patent/EP2302525A1/en not_active Ceased
Patent Citations (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4598400A (en) * | 1983-05-31 | 1986-07-01 | Thinking Machines Corporation | Method and apparatus for routing message packets |
| EP0132926B1 (en) * | 1983-05-31 | 1993-05-05 | W. Daniel Hillis | Parallel processor |
| US5535408A (en) * | 1983-05-31 | 1996-07-09 | Thinking Machines Corporation | Processor chip for parallel processing system |
| EP0206580A2 (en) * | 1985-06-04 | 1986-12-30 | Thinking Machines Corporation | Method and apparatus for interconnecting processors in a hyper-dimensional array |
| US5175865A (en) * | 1986-10-28 | 1992-12-29 | Thinking Machines Corporation | Partitioning the processors of a massively parallel single array processor into sub-arrays selectively controlled by host computers |
| US5247694A (en) * | 1990-06-14 | 1993-09-21 | Thinking Machines Corporation | System and method for generating communications arrangements for routing data in a massively parallel processing system |
| EP0544532A2 (en) * | 1991-11-26 | 1993-06-02 | Fujitsu Limited | A parallel computer and its all-to-all communications method |
| US20060179270A1 (en) * | 2005-02-07 | 2006-08-10 | International Business Machines Corporation | All row, planar fault detection system |
Non-Patent Citations (12)
| Title |
|---|
| D. S. SCOTT: "Efficient all-to-all communication patterns in hypercube and mesh topologies", 6TH DISTRIBUTED MEMORY COMPUTING CONFERENCE, 1991, pages 398 - 403, XP010255055 |
| DANIEL HILLIS ET AL: "The connection machine: A computer architecture based on cellular automata", PHYSICA D, NORTH-HOLLAND, AMSTERDAM, NL, vol. 10, no. 1-2, 1 January 1984 (1984-01-01), pages 213 - 228, XP024479362, ISSN: 0167-2789, [retrieved on 19840101], DOI: 10.1016/0167-2789(84)90263-X * |
| G. ALAMASI; P. HEIDELBERGER; C. J. ARCHER; X. MARTORELL; C. C. ERWAY; J. E. MOREIRA; B. STEINMACHER-BUROW; Y. ZHENG: "ICS '05: Proceedings of the 19th annual international conference on Supercomputing", 2005, USA: ACM, article "Optimization of mpi collective communication on bluegene/I systems", pages: 253 - 262 |
| HILLIS W D ET AL: "THE CM-5 CONNECTION MACHINE: A SCALABLE SUPERCOMPUTER", COMMUNICATIONS OF THE ASSOCIATION FOR COMPUTING MACHINERY, ACM, NEW YORK, NY, US, vol. 36, no. 11, 1 November 1993 (1993-11-01), pages 31 - 40, XP000415037, ISSN: 0001-0782, DOI: 10.1145/163359.163361 * |
| J. BRUCK; C.-T. HO; S. KIPNIS; D. WEATHERSBY: "SPAA '94: Proceedings of the sixth annual ACM symposium on Parallel algorithms and architectures", 1994, ACM, article "Efficient Algorithms for all-to-all communications in multi-port message-passing systems", pages: 298 - 309 |
| LEISERSON C E ET AL: "The Network Architecture of the Connection Machine CM-5", JOURNAL OF PARALLEL AND DISTRIBUTED COMPUTING, ELSEVIER, AMSTERDAM, NL, vol. 33, no. 2, 15 March 1996 (1996-03-15), pages 145 - 158, XP004419204, ISSN: 0743-7315, DOI: 10.1006/JPDC.1996.0033 * |
| N. R. ADIGA; M. A. BLUMRICH; D. CHEN; P. COTEUS; A. GARA; M. E. GIAMPAPA; P. HEIDELBERGER; S. SINGH; B. D. STEINMACHER-BUROW; T. T: "Blue Gene/L torus interconnection network", IBM JOURNAL OF RESEARCH AND DEVELOPMENT, vol. 49, no. 2-3, 2005, pages 265 - 276, XP002496339 |
| S. KUMAR; Y. SABHARWAL; R. GARG; P. HEIDELBERGER; SEPT 2008: "Optimization of All-to-All Communication on the Blue Gene/L Supercomputer", 37TH INTERNATIONAL CONFERENCE ON PARALLEL PROCESSING, pages 320 - 329 |
| TAKESHI HORIE; KENICHI HAYASHI: "Optimal All-to-All Communication Method in Torus Network", TRANSACTIONS OF INFORMATION PROCESSING SOCIETY OF JAPAN, vol. 34, no. 4, 1993, pages 628 - 637 |
| TUCKER L W ET AL: "ARCHITECTURE AND APPLICATIONS OF THE CONNECTION MACHINE", COMPUTER, IEEE SERVICE CENTER, LOS ALAMITOS, CA, US, vol. 21, no. 8, 1 August 1988 (1988-08-01), pages 26 - 38, XP000118166, ISSN: 0018-9162, DOI: 10.1109/2.74 * |
| V. TIPPARAJU; J. NIEPLOCHA: "SC '05: Proceedings of the 2005 ACM/IEEE conference on Supercomputing", 2005, IEEE COMPUTER SOCIETY, article "Optimizing all-to-all collective communication by exploiting concurrency in modern networks", pages: 46 |
| Y.-C. TSENG; S. K. S. GUPTA: "All-to-all personalized communication in a wormhole-routed torus", IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, vol. 7, no. 5, May 1996 (1996-05-01), pages 498 - 505, XP000591120, DOI: doi:10.1109/71.503775 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5540609B2 (en) | 2014-07-02 |
| US20110213946A1 (en) | 2011-09-01 |
| US10430375B2 (en) | 2019-10-01 |
| JP2011053876A (en) | 2011-03-17 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10430375B2 (en) | Parallel computing system and communication control program | |
| US9253085B2 (en) | Hierarchical asymmetric mesh with virtual routers | |
| JP4676463B2 (en) | Parallel computer system | |
| Su et al. | Adaptive deadlock-free routing in multicomputers using only one extra virtual channel | |
| US9880972B2 (en) | Computer subsystem and computer system with composite nodes in an interconnection structure | |
| JP5425993B2 (en) | A method, a program, and a parallel computer system for scheduling a plurality of calculation processes including all-to-all communication (A2A) between a plurality of nodes (processors) constituting a network. | |
| CN112188325B (en) | Reconfigurable computing platform using optical network with one-to-many optical switch | |
| KR102583771B1 (en) | Reconfigurable computing pods using optical networks | |
| US11018896B2 (en) | Information processing apparatus and information processing method | |
| CN105075199A (en) | Direct network having plural distributed connections to each resource | |
| WO2018063577A1 (en) | Technologies for scalable hierarchical interconnect topologies | |
| US8504731B2 (en) | Network for interconnecting computers | |
| CN109952809B (en) | Quaternary full mesh dimension driven network architecture | |
| CN111078286B (en) | Data communication method, computing system and storage medium | |
| JP6036848B2 (en) | Information processing system | |
| US9774498B2 (en) | Hierarchical asymmetric mesh with virtual routers | |
| US20100031004A1 (en) | Arithmetic device | |
| JP2003067354A (en) | Parallel computer system and interprocessor communication processing method | |
| US20230412524A1 (en) | Device and method with multi-stage electrical interconnection network | |
| Feng et al. | Criso: An incremental scalable and cost-effective data center interconnection by using 2-port servers and low-end switches | |
| Zhou et al. | Embedding fault-free cycles of various lengths in k-ary n-cubes with faulty edges | |
| CN117807017A (en) | High-performance computer with cube supernode multi-plane interconnection and communication method thereof | |
| CN115037747A (en) | Data communication method and device, distributed system, device and medium | |
| Leonard et al. | The software interface for a cluster interconnect based on the Kautz digraph |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PUAI | Public reference made under article 153(3) epc to a published international application that has entered the european phase |
Free format text: ORIGINAL CODE: 0009012 |
|
| AK | Designated contracting states |
Kind code of ref document: A1 Designated state(s): AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO SE SI SK SM TR |
|
| AX | Request for extension of the european patent |
Extension state: BA ME RS |
|
| 17P | Request for examination filed |
Effective date: 20110926 |
|
| 17Q | First examination report despatched |
Effective date: 20151106 |
|
| STAA | Information on the status of an ep patent application or granted ep patent |
Free format text: STATUS: THE APPLICATION HAS BEEN REFUSED |
|
| 18R | Application refused |
Effective date: 20180916 |